आवश्यक शर्तें
इस ट्यूटोरियल में उदाहरणों का अभ्यास करने से पहले आपको क्लाइंट के साथ डेटाबेस सर्वर स्थापित करना होगा। इस ट्यूटोरियल में MariaDB डेटाबेस सर्वर और क्लाइंट का उपयोग किया जाता है।
1. सिस्टम को अपडेट करने के लिए निम्नलिखित कमांड चलाएँ:
$ sudo apt-अपडेट प्राप्त करें
2. मारियाडीबी सर्वर और क्लाइंट को स्थापित करने के लिए निम्नलिखित कमांड चलाएँ:
$ sudo apt-get install mariadb-server mariadb-client
3. मारियाडीबी डेटाबेस के लिए सुरक्षा स्क्रिप्ट स्थापित करने के लिए निम्नलिखित कमांड चलाएँ:
$ sudo mysql_secure_installation
4. मारियाडीबी सर्वर को पुनः आरंभ करने के लिए निम्नलिखित कमांड चलाएँ:
$ sudo /etc/init.d/mariadb पुनरारंभ करें
6. मारियाडीबी सर्वर में लॉग इन करने के लिए निम्नलिखित कमांड चलाएँ:
$ सुडो मारियाडब -यू रूट -पीSQL क्वेरी उदाहरणों की सूची
- डेटाबेस बनाएं
- तालिकाएँ बनाएँ
- तालिका का नाम बदलें
- तालिका में एक नया कॉलम जोड़ें
- तालिका से कॉलम हटाएँ
- तालिका में एक पंक्ति सम्मिलित करें
- तालिका में एकाधिक पंक्तियाँ सम्मिलित करें
- तालिका से सभी विशेष फ़ील्ड पढ़ें
- तालिका से डेटा फ़िल्टर करने के बाद तालिका पढ़ें
- बूलियन लॉजिक के आधार पर डेटा को फ़िल्टर करने के बाद तालिका पढ़ें
- डेटा की सीमा के आधार पर पंक्तियों को फ़िल्टर करने के बाद तालिका पढ़ें
- विशेष कॉलमों के आधार पर तालिका को क्रमबद्ध करने के बाद तालिका पढ़ें।
- कॉलम का वैकल्पिक नाम सेट करके तालिका पढ़ें
- तालिका में पंक्तियों की कुल संख्या की गणना करें
- एकाधिक तालिकाओं से डेटा पढ़ें
- विशेष फ़ील्ड को समूहीकृत करके तालिका पढ़ें
- डुप्लिकेट मानों को हटाने के बाद तालिका पढ़ें
- पंक्ति संख्या को सीमित करके तालिका पढ़ें
- आंशिक मिलान के आधार पर तालिका पढ़ें
- तालिका के विशेष क्षेत्र का योग गिनें
- विशेष फ़ील्ड के अधिकतम और न्यूनतम मान ज्ञात करें
- किसी फ़ील्ड के विशेष भाग पर डेटा पढ़ें
- संयोजन के बाद तालिका डेटा पढ़ें
- गणितीय गणना के बाद तालिका डेटा पढ़ें
- तालिका का एक दृश्य बनाएं
- विशेष स्थिति के आधार पर तालिका को अद्यतन करें
- विशेष स्थिति के आधार पर तालिका डेटा हटाएँ
- तालिका से सभी रिकॉर्ड हटाएँ
- टेबल गिराओ
- डेटाबेस छोड़ें
डेटाबेस बनाएं
मान लीजिए हमें लाइब्रेरी प्रबंधन प्रणाली के लिए एक सरल डेटाबेस डिज़ाइन करना है। इस कार्य को करने के लिए, सर्वर में एक डेटाबेस बनाने की आवश्यकता होती है जिसमें एकाधिक रिलेशनल टेबल शामिल हों। डेटाबेस सर्वर में लॉग इन करने के बाद, MariaDB डेटाबेस सर्वर में 'लाइब्रेरी' नामक डेटाबेस बनाने के लिए निम्नलिखित कमांड चलाएँ:
बनाएं डेटाबेस पुस्तकालय;आउटपुट दिखाता है कि लाइब्रेरी डेटाबेस सर्वर पर बनाया गया है:
 विभिन्न प्रकार के डेटाबेस ऑपरेशन करने के लिए सर्वर से डेटाबेस का चयन करने के लिए निम्नलिखित कमांड चलाएँ:
विभिन्न प्रकार के डेटाबेस ऑपरेशन करने के लिए सर्वर से डेटाबेस का चयन करने के लिए निम्नलिखित कमांड चलाएँ:
आउटपुट दिखाता है कि लाइब्रेरी डेटाबेस चयनित है:

तालिकाएँ बनाएँ
अगला चरण डेटा को संग्रहीत करने के लिए डेटाबेस के लिए आवश्यक तालिकाएँ बनाना है। ट्यूटोरियल के इस भाग में तीन तालिकाएँ बनाई गई हैं। ये पुस्तकें, सदस्य और उधार_जानकारी तालिकाएँ हैं।
- पुस्तक तालिका पुस्तक से संबंधित सभी डेटा संग्रहीत करती है।
- सदस्य तालिका उन सदस्यों के बारे में सारी जानकारी संग्रहीत करती है जो पुस्तकालय से पुस्तक उधार लेते हैं।
- उधार_जानकारी तालिका यह जानकारी संग्रहीत करती है कि किस सदस्य ने कौन सी पुस्तक उधार ली है।
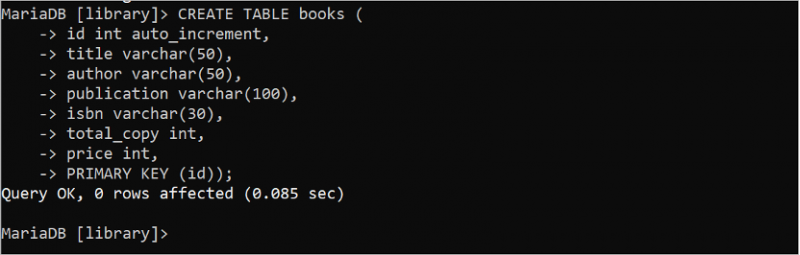
1. किताबें मेज
'लाइब्रेरी' डेटाबेस में 'किताबें' नाम की एक तालिका बनाने के लिए निम्नलिखित SQL कथन चलाएँ जिसमें सात फ़ील्ड और एक प्राथमिक कुंजी शामिल है। यहां, 'आईडी' फ़ील्ड प्राथमिक कुंजी है और डेटा प्रकार पूर्णांक है। auto_increment विशेषता का उपयोग 'id' फ़ील्ड के लिए किया जाता है। इसलिए, जब कोई नई पंक्ति डाली जाती है तो इस फ़ील्ड का मान स्वचालित रूप से बढ़ जाता है। वर्चर डेटा प्रकार का उपयोग वेरिएबल लंबाई के स्ट्रिंग डेटा को संग्रहीत करने के लिए किया जाता है। शीर्षक, लेखक, प्रकाशन और आईएसबीएन फ़ील्ड स्ट्रिंग डेटा संग्रहीत करते हैं। total_copy और कीमत फ़ील्ड का डेटा प्रकार int है। इसलिए, ये फ़ील्ड संख्यात्मक डेटा संग्रहीत करते हैं।
बनाएं मेज पुस्तकें (पहचान int यहाँ स्वत: वेतनवृद्धि ,
शीर्षक वर्चर ( पचास ) ,
लेखक वर्चर ( पचास ) ,
प्रकाशन वर्चर ( 100 ) ,
आईएसबीएन वर्चर ( 30 ) ,
total_copy int यहाँ ,
कीमत int यहाँ ,
प्राथमिक चाबी ( पहचान ) ) ;
आउटपुट दिखाता है कि 'पुस्तकें' तालिका सफलतापूर्वक बनाई गई है:
2. सदस्य मेज
'लाइब्रेरी' डेटाबेस में 'सदस्य' नाम की एक तालिका बनाने के लिए निम्नलिखित SQL कथन चलाएँ जिसमें 5 फ़ील्ड और एक प्राथमिक कुंजी शामिल है। 'आईडी' फ़ील्ड में 'पुस्तकें' तालिका की तरह ऑटो_इंक्रीमेंट विशेषता है। अन्य फ़ील्ड का डेटा प्रकार varchar है। तो, ये फ़ील्ड स्ट्रिंग डेटा संग्रहीत करते हैं।
बनाएं मेज सदस्यों (पहचान int यहाँ स्वत: वेतनवृद्धि ,
नाम वर्चर ( पचास ) ,
पता वर्चर ( 200 ) ,
संपर्क नंबर वर्चर ( पंद्रह ) ,
ईमेल वर्चर ( पचास ) ,
प्राथमिक चाबी ( पहचान ) ) ;
आउटपुट दिखाता है कि 'सदस्य' तालिका सफलतापूर्वक बनाई गई है:

3. उधार_जानकारी मेज
'लाइब्रेरी' डेटाबेस में 'borrow_info' नाम की एक तालिका बनाने के लिए निम्नलिखित SQL कथन चलाएँ जिसमें 6 फ़ील्ड हैं। यहां, 'आईडी' फ़ील्ड प्राथमिक कुंजी है लेकिन इस फ़ील्ड के लिए auto_increment विशेषता का उपयोग नहीं किया जाता है। इसलिए, जब कोई नया रिकॉर्ड तालिका में डाला जाता है तो इस फ़ील्ड में मैन्युअल रूप से एक अद्वितीय मान डाला जाता है। इस तालिका के लिए Book_id और member_id फ़ील्ड विदेशी कुंजी हैं; वे 'पुस्तकें' तालिका और 'सदस्य' तालिका की प्राथमिक कुंजी हैं। उधार_तिथि और वापसी_तिथि फ़ील्ड का डेटा प्रकार दिनांक है। तो, ये दो फ़ील्ड दिनांक मान को 'YYYY-MM-DD' प्रारूप में संग्रहीत करते हैं।
बनाएं मेज उधार_जानकारी (पहचान int यहाँ ,
उधार_तिथि तारीख ,
पुस्तक_आईडी int यहाँ ,
सदस्य पहचान पत्र int यहाँ ,
वापसी दिनांक तारीख ,
दर्जा वर्चर ( 10 ) ,
प्राथमिक चाबी ( पहचान ) ,
विदेश चाबी ( पुस्तक_आईडी ) प्रतिक्रिया दें संदर्भ पुस्तकें ( पहचान ) ,
विदेश चाबी ( सदस्य पहचान पत्र ) प्रतिक्रिया दें संदर्भ सदस्यों ( पहचान ) ) ;
आउटपुट दिखाता है कि 'borrow_info' तालिका सफलतापूर्वक बनाई गई है:

तालिका का नाम बदलें
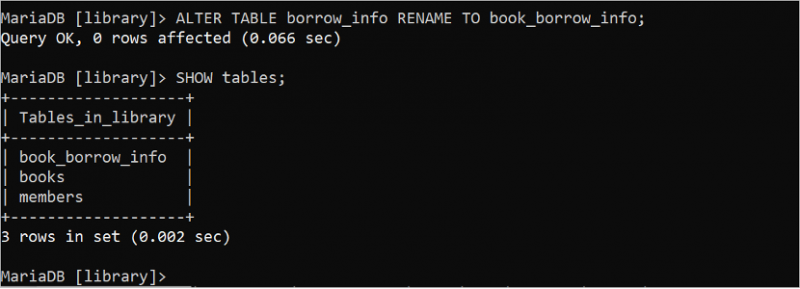
ALTER TABLE स्टेटमेंट का उपयोग SQL स्टेटमेंट में कई उद्देश्यों के लिए किया जा सकता है। 'borrow_info' तालिका का नाम 'book_borrow_info' में बदलने के लिए निम्नलिखित ALTER TABLE कथन चलाएँ। इसके बाद, SHOW टेबल स्टेटमेंट का उपयोग यह जांचने के लिए किया जा सकता है कि टेबल का नाम बदला गया है या नहीं।
ऑल्टर मेज उधार_जानकारी नाम बदलें को पुस्तक_उधार_जानकारी;दिखाना तालिकाएं ;
आउटपुट से पता चलता है कि तालिका का नाम सफलतापूर्वक बदल दिया गया है और उधार_इन्फो तालिका का नाम Book_borrow_info में बदल दिया गया है:
तालिका में एक नया कॉलम जोड़ें
तालिका बनाने के बाद एक या अधिक कॉलम जोड़ने या हटाने के लिए ALTER TABLE कथन का उपयोग किया जा सकता है। निम्नलिखित परिवर्तन तालिका कथन तालिका सदस्यों में 'स्थिति' नामक एक नया फ़ील्ड जोड़ता है। DESCRIBE स्टेटमेंट का उपयोग यह दिखाने के लिए किया जाता है कि तालिका संरचना बदली गई है या नहीं।
ऑल्टर मेज सदस्यों जोड़ना दर्जा वर्चर ( 10 ) ;वर्णन करना सदस्य;
आउटपुट से पता चलता है कि एक नया कॉलम जो 'स्थिति' है, 'सदस्य' तालिका में जोड़ा गया है और तालिका का डेटा प्रकार वर्चर है:

तालिका से कॉलम हटाएँ
निम्नलिखित परिवर्तन तालिका कथन 'सदस्य' तालिका से 'स्थिति' नामक फ़ील्ड को हटा देता है। DESCRIBE स्टेटमेंट का उपयोग यह दिखाने के लिए किया जाता है कि तालिका संरचना बदली गई है या नहीं।
ऑल्टर मेज सदस्यों बूँद कॉलम दर्जा ;वर्णन करना सदस्य;
आउटपुट से पता चलता है कि 'स्थिति' कॉलम 'सदस्य' तालिका से हटा दिया गया है:

तालिका में एक पंक्ति सम्मिलित करें
INSERT INTO स्टेटमेंट का उपयोग तालिका में एक या अधिक पंक्तियों को सम्मिलित करने के लिए किया जाता है। 'पुस्तकें' तालिका में एक पंक्ति सम्मिलित करने के लिए निम्नलिखित SQL कथन चलाएँ। यहां, 'आईडी' फ़ील्ड को इस क्वेरी से हटा दिया गया है क्योंकि ऑटो-इंक्रीमेंट विशेषता के लिए एक नया रिकॉर्ड डालने पर यह स्वचालित रूप से रिकॉर्ड में डाला जाता है। यदि इस फ़ील्ड का उपयोग INSERT कथन में किया जाता है, तो मान शून्य होना चाहिए।
डालना में पुस्तकें ( शीर्षक , लेखक , प्रकाशन , आईएसबीएन , total_copy , कीमत )मान ( '10 मिनट में एसक्यूएल' , 'बेन फोर्टा' , 'सैम्स पब्लिशिंग' , '784534235' , 5 , 39 ) ;
आउटपुट दिखाता है कि एक रिकॉर्ड 'पुस्तकें' तालिका में सफलतापूर्वक जोड़ा गया है:

डेटा को SET क्लॉज का उपयोग करके तालिका में डाला जा सकता है जहां प्रत्येक फ़ील्ड मान अलग से निर्दिष्ट किया गया है। INSERT INTO और SET क्लॉज का उपयोग करके 'सदस्यों' तालिका में एक पंक्ति सम्मिलित करने के लिए निम्नलिखित SQL कथन चलाएँ। इसी कारण से पिछले उदाहरण की तरह इस क्वेरी में भी 'आईडी' फ़ील्ड छोड़ दिया गया है।
डालना में सदस्योंतय करना नाम = 'जॉन सीना' , पता = '34, धनमंडी 9/ए, ढाका' , संपर्क नंबर = '+14844731336' , ईमेल = 'john@gmail.com' ;
आउटपुट दिखाता है कि सदस्य तालिका में एक रिकॉर्ड सफलतापूर्वक जोड़ा गया है:

'book_borrow_info' तालिका में एक पंक्ति सम्मिलित करने के लिए निम्नलिखित SQL कथन चलाएँ:
डालना में पुस्तक_उधार_जानकारी ( पहचान , उधार_तिथि , पुस्तक_आईडी , सदस्य पहचान पत्र , वापसी दिनांक , दर्जा )मान ( 1 , '2023-03-12' , 1 , 1 , '2023-03-19' , 'उधार' ) ;
आउटपुट दिखाता है कि 'book_borrow_info' तालिका में एक रिकॉर्ड जोड़ा गया है:

तालिका में एकाधिक पंक्तियाँ सम्मिलित करें
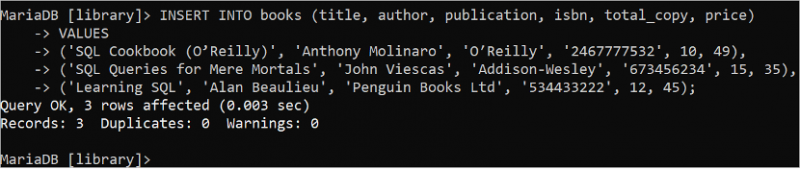
कभी-कभी, एकल INSERT INTO स्टेटमेंट का उपयोग करके एक समय में कई रिकॉर्ड जोड़ने की आवश्यकता होती है। एकल INSERT INTO कथन का उपयोग करके 'किताबें' तालिका में तीन रिकॉर्ड सम्मिलित करने के लिए निम्नलिखित SQL कथन चलाएँ। इस मामले में, VALUES क्लॉज का उपयोग एक बार के लिए किया जाता है और प्रत्येक रिकॉर्ड के डेटा को अल्पविराम द्वारा अलग किया जाता है।
डालना में पुस्तकें ( शीर्षक , लेखक , प्रकाशन , आईएसबीएन , total_copy , कीमत )मान
( 'एसक्यूएल कुकबुक (ओ'रेली)' , 'एंथनी मोलिनारो' , 'ओ'रेली' , '2467777532' , 10 , 49 ) ,
( 'केवल नश्वर लोगों के लिए एसक्यूएल क्वेरीज़' , 'जॉन विस्कस' , 'एडिसन-वेस्ले' , '673456234' , पंद्रह , 35 ) ,
( 'एसक्यूएल सीखना' , 'एलन ब्यूलियू' , 'पेंगुइन बुक्स लिमिटेड' , '534433222' , 12 , चार पांच ) ;
आउटपुट से पता चलता है कि 'पुस्तकें' तालिका में तीन रिकॉर्ड जोड़े गए हैं:
तालिका से सभी विशेष फ़ील्ड पढ़ें
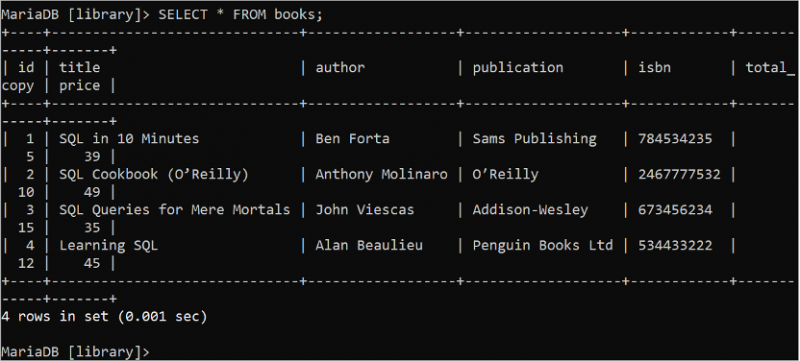
SELECT स्टेटमेंट का उपयोग 'डेटाबेस' तालिका से डेटा को पढ़ने के लिए किया जाता है। '*' चिन्ह का उपयोग SELECT स्टेटमेंट में तालिका के सभी फ़ील्ड को दर्शाने के लिए किया जाता है। पुस्तकें तालिका के सभी रिकॉर्ड पढ़ने के लिए निम्नलिखित SQL कमांड चलाएँ:
चुनना * से पुस्तकें;आउटपुट पुस्तक तालिका के सभी रिकॉर्ड दिखाता है जिसमें 4 रिकॉर्ड हैं:
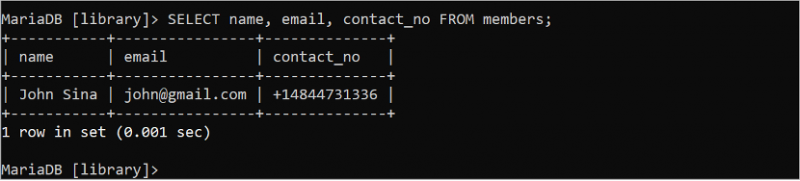
'सदस्य' तालिका के तीन फ़ील्ड के सभी रिकॉर्ड पढ़ने के लिए निम्नलिखित SQL कमांड चलाएँ:
चुनना नाम , ईमेल , संपर्क नंबर से सदस्य;आउटपुट 'सदस्य' तालिका के तीन फ़ील्ड के सभी रिकॉर्ड दिखाता है:
तालिका से डेटा फ़िल्टर करने के बाद तालिका पढ़ें
WHERE क्लॉज का उपयोग एक या अधिक शर्तों के आधार पर तालिका से डेटा को पढ़ने के लिए किया जाता है। 'पुस्तकें' तालिका के सभी क्षेत्रों के सभी रिकॉर्ड को पढ़ने के लिए निम्नलिखित चयन कथन चलाएँ जहाँ लेखक का नाम 'जॉन विस्कस' है।
चुनना * से पुस्तकें कहाँ लेखक = 'जॉन विस्कस' ;'पुस्तकें' तालिका में एक रिकॉर्ड होता है जो WHERE क्लॉज की स्थिति से मेल खाता है जो आउटपुट में दिखाया गया है:

बूलियन लॉजिक के आधार पर डेटा को फ़िल्टर करने के बाद तालिका पढ़ें
बूलियन AND लॉजिक का उपयोग WHERE क्लॉज में कई स्थितियों को परिभाषित करने के लिए किया जाता है जो सभी शर्तों के सत्य होने पर सत्य लौटाता है। तार्किक AND का उपयोग करके 'किताबें' तालिका के सभी फ़ील्ड के सभी रिकॉर्ड को पढ़ने के लिए निम्नलिखित SELECT स्टेटमेंट चलाएँ, जहाँ total_copy फ़ील्ड का मान 10 से अधिक है और मूल्य फ़ील्ड का मान 45 से कम है।
चुनना * से पुस्तकें कहाँ total_copy > 10 और कीमत < चार पांच ;पुस्तकें तालिका में एक रिकॉर्ड होता है जो WHERE क्लॉज की स्थिति से मेल खाता है जो आउटपुट में दिखाया गया है:

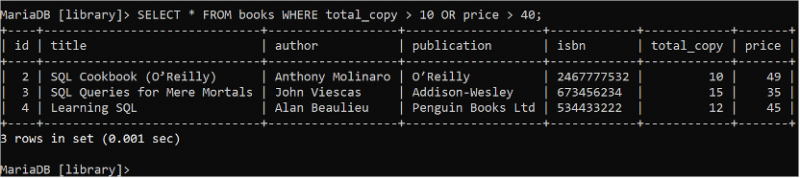
बूलियन OR लॉजिक का उपयोग WHERE क्लॉज में कई स्थितियों को परिभाषित करने के लिए किया जाता है जो कि यदि कोई भी शर्त सत्य होती है तो सत्य लौटाता है। 'पुस्तकें' तालिका के सभी फ़ील्ड के सभी रिकॉर्ड को पढ़ने के लिए निम्नलिखित चयन कथन चलाएँ, जहाँ total_copy फ़ील्ड का मान 10 से अधिक है या मूल्य फ़ील्ड का मान 40 से अधिक है।
चुनना * से पुस्तकें कहाँ total_copy > 10 या कीमत > 40 ;पुस्तकें तालिका में तीन रिकॉर्ड होते हैं जो आउटपुट में दिखाए गए WHERE क्लॉज की स्थिति से मेल खाते हैं:
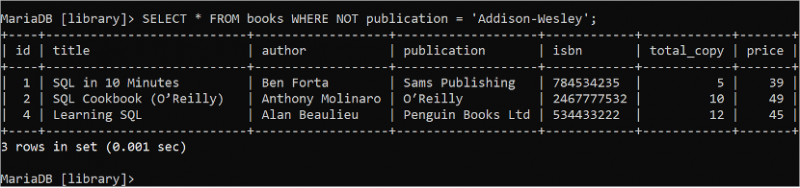
बूलियन नॉट तर्क का उपयोग स्थिति सत्य होने पर गलत लौटाने के लिए किया जाता है और स्थिति गलत होने पर सत्य लौटाने के लिए किया जाता है। 'पुस्तकें' तालिका के सभी फ़ील्ड के सभी रिकॉर्ड को पढ़ने के लिए निम्नलिखित चयन कथन चलाएँ जहाँ लेखक फ़ील्ड का मान 'एडिसन-वेस्ले' नहीं है।
चुनना * से पुस्तकें कहाँ नहीं लेखक = 'एडिसन-वेस्ले' ;'पुस्तकें' तालिका में तीन रिकॉर्ड होते हैं जो आउटपुट में दिखाए गए WHERE क्लॉज की स्थिति से मेल खाते हैं:
डेटा की सीमा के आधार पर पंक्तियों को फ़िल्टर करने के बाद तालिका पढ़ें
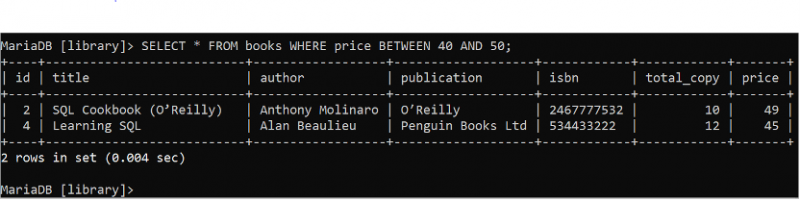
BETWEEN क्लॉज का उपयोग डेटाबेस तालिका से डेटा की सीमा को पढ़ने के लिए किया जाता है। 'पुस्तकें' तालिका के सभी फ़ील्ड के सभी रिकॉर्ड को पढ़ने के लिए निम्नलिखित चयन कथन चलाएँ जहाँ मूल्य फ़ील्ड का मान 40 से 50 के बीच है।
चुनना * से पुस्तकें कहाँ कीमत बीच में 40 और पचास ;पुस्तकें तालिका में दो रिकॉर्ड हैं जो आउटपुट में दिखाए गए WHERE क्लॉज की स्थिति से मेल खाते हैं। मूल्य मान की पुस्तकें, 39 और 35, परिणाम सेट से हटा दी गई हैं क्योंकि वे सीमा से बाहर हैं।
तालिका को क्रमबद्ध करने के बाद तालिका को पढ़ें
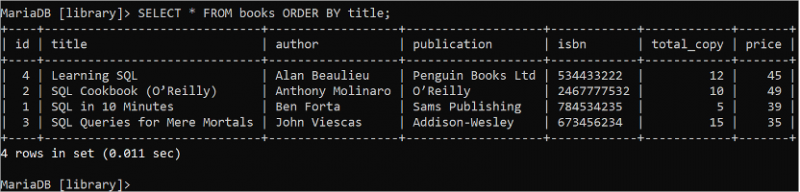
ORDER BY क्लॉज का उपयोग SELECT स्टेटमेंट के परिणाम सेट को आरोही या अवरोही क्रम में क्रमबद्ध करने के लिए किया जाता है। यदि ORDER BY क्लॉज का उपयोग ASC या DESC के बिना किया जाता है, तो परिणाम सेट को डिफ़ॉल्ट रूप से आरोही क्रम में क्रमबद्ध किया जाता है। निम्नलिखित चयन कथन शीर्षक फ़ील्ड के आधार पर पुस्तक तालिका से क्रमबद्ध रिकॉर्ड को पढ़ता है:
चुनना * से पुस्तकें आदेश द्वारा शीर्षक;'पुस्तकें' तालिका के शीर्षक फ़ील्ड का डेटा आउटपुट में आरोही क्रम में क्रमबद्ध किया गया है। यदि 'किताबें' तालिका के शीर्षक फ़ील्ड को आरोही क्रम में क्रमबद्ध किया जाता है, तो 'लर्निंग एसक्यूएल' पुस्तक वर्णानुक्रम में पहले आती है।
कॉलम का वैकल्पिक नाम सेट करके तालिका पढ़ें
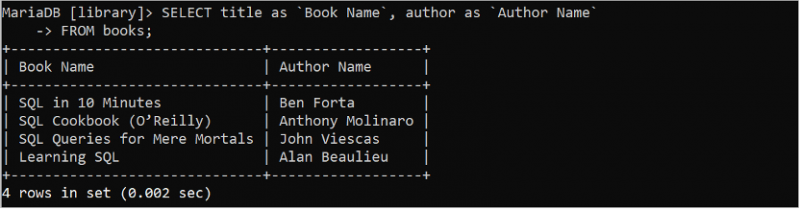
परिणाम सेट को अधिक पठनीय बनाने के लिए क्वेरी में कॉलम के वैकल्पिक नाम का उपयोग किया जाता है। वैकल्पिक नाम 'AS' कीवर्ड का उपयोग करके सेट किया गया है। निम्नलिखित SQL कथन वैकल्पिक नाम सेट करके शीर्षक और लेखक फ़ील्ड के मान लौटाता है।
चुनना शीर्षक जैसा `पुस्तक का नाम` , लेखक जैसा 'लेखक का नाम'से पुस्तकें;
शीर्षक फ़ील्ड को वैकल्पिक नाम के साथ प्रदर्शित किया जाता है जो कि 'पुस्तक का नाम' है और लेखक फ़ील्ड को वैकल्पिक नाम के साथ प्रदर्शित किया जाता है जो आउटपुट में 'लेखक का नाम' है।
तालिका में पंक्तियों की कुल संख्या की गणना करें
COUNT() SQL का एक समग्र फ़ंक्शन है जिसका उपयोग विशेष फ़ील्ड या सभी फ़ील्ड के आधार पर पंक्तियों की कुल संख्या की गणना करने के लिए किया जाता है। '*' प्रतीक का उपयोग सभी फ़ील्ड को दर्शाने के लिए किया जाता है और COUNT(*) का उपयोग तालिका के सभी रिकॉर्ड को गिनने के लिए किया जाता है।
निम्नलिखित क्वेरी पुस्तक तालिका के कुल रिकॉर्ड की गणना करती है:
चुनना गिनती करना ( * ) जैसा `कुल पुस्तकें` से पुस्तकें;आउटपुट में 'पुस्तकें' तालिका में चार रिकॉर्ड दिखाए गए हैं:

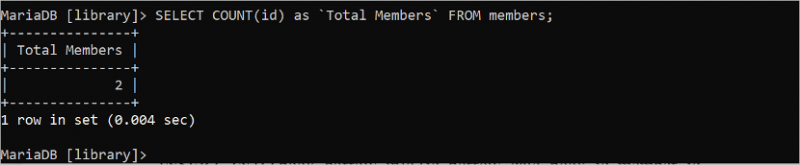
निम्नलिखित क्वेरी 'आईडी' फ़ील्ड के आधार पर 'सदस्य' तालिका की कुल पंक्तियों की गणना करती है:
चुनना गिनती करना ( पहचान ) जैसा `कुल सदस्य` से सदस्य;'सदस्य' तालिका में दो आईडी मान हैं जो आउटपुट में मुद्रित होते हैं:
एकाधिक तालिकाओं से डेटा पढ़ें
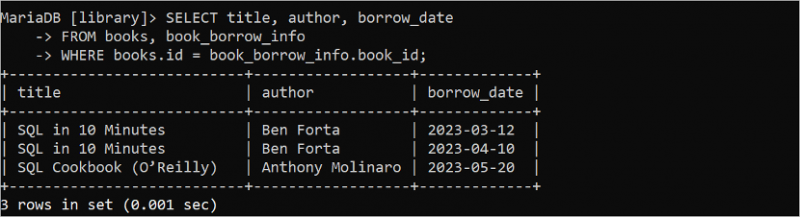
पिछले SELECT कथनों ने एक ही तालिका से डेटा पुनर्प्राप्त किया था। लेकिन SELECT स्टेटमेंट का उपयोग दो या दो से अधिक तालिकाओं से डेटा पुनर्प्राप्त करने के लिए किया जा सकता है। निम्नलिखित SELECT क्वेरी 'पुस्तकें' तालिका से शीर्षक और लेखक फ़ील्ड के मान और 'book_borrow_info' तालिका से उधार_तिथि को पढ़ती है।
चुनना शीर्षक , लेखक , उधार_तिथिसे पुस्तकें , पुस्तक_उधार_जानकारी
कहाँ पुस्तकें . पहचान = पुस्तक_उधार_जानकारी . पुस्तक_आईडी;
निम्नलिखित आउटपुट से पता चलता है कि 'एसक्यूएल इन 10 मिनट्स' पुस्तक दो बार उधार ली गई है और 'एसक्यूएल कुकबुक (ओ'रेली)' पुस्तक एक बार उधार ली गई है:
डेटा को विभिन्न प्रकार के JOINs जैसे INNER JOIN, OUTER JOIN इत्यादि का उपयोग करके कई तालिकाओं से पुनर्प्राप्त किया जा सकता है, जिन्हें इस ट्यूटोरियल में नहीं बताया गया है।
विशेष फ़ील्ड को समूहीकृत करके तालिका पढ़ें
ग्रुप बाय क्लॉज का उपयोग एक या अधिक फ़ील्ड के आधार पर पंक्तियों को समूहीकृत करके तालिका से रिकॉर्ड पढ़ने के लिए किया जाता है। इस प्रकार की क्वेरी को सारांश क्वेरी कहा जाता है. GROUP BY क्लॉज़ के उपयोग की जाँच करने के लिए आपको तालिकाओं में कई पंक्तियाँ सम्मिलित करनी होंगी। 'सदस्य' तालिका में एक रिकॉर्ड और 'book_borrow_info' तालिका में दो रिकॉर्ड डालने के लिए निम्नलिखित INSERT कथन चलाएँ।
डालना में सदस्योंतय करना नाम = 'वह हसन' , पता = '11/A, Jigatola, Dhaka' , संपर्क नंबर = '+8801734563423' , ईमेल = 'she@gmail.com' ;
डालना में पुस्तक_उधार_जानकारी ( पहचान , उधार_तिथि , पुस्तक_आईडी , सदस्य पहचान पत्र , वापसी दिनांक , दर्जा )
मान ( 2 , '2023-04-10' , 1 , 1 , '2023-04-15' , 'लौटा हुआ' ) ;
डालना में पुस्तक_उधार_जानकारी ( पहचान , उधार_तिथि , पुस्तक_आईडी , सदस्य पहचान पत्र , वापसी दिनांक , दर्जा )
मान ( 3 , '2023-05-20' , 2 , 1 , '2023-05-30' , 'उधार' ) ;
पिछले प्रश्नों को निष्पादित करके डेटा डालने के बाद, निम्नलिखित चयन कथन चलाएं जो ग्रुप बाय क्लॉज का उपयोग करके प्रत्येक सदस्य के आधार पर उधार ली गई पुस्तकों की कुल संख्या और सदस्य के नाम की गणना करता है। यहां, COUNT() फ़ंक्शन उस फ़ील्ड पर काम करता है जिसका उपयोग GROUP BY क्लॉज़ का उपयोग करके रिकॉर्ड को पुन: समूहित करने के लिए किया जाता है। 'सदस्य' तालिका के बुक_आईडी फ़ील्ड का उपयोग यहां समूहीकरण के लिए किया जाता है।
चुनना गिनती करना ( पुस्तक_आईडी ) जैसा `उधार ली गई कुल पुस्तक` , नाम जैसा `सदस्य का नाम` से पुस्तकें , सदस्यों , पुस्तक_उधार_जानकारी कहाँ पुस्तकें . पहचान = पुस्तक_उधार_जानकारी . पुस्तक_आईडी और सदस्यों . पहचान = पुस्तक_उधार_जानकारी . सदस्य पहचान पत्र समूह द्वारा पुस्तक_उधार_जानकारी . सदस्य पहचान पत्र;पुस्तकों, 'सदस्यों' और 'book_borrow_info' तालिकाओं के आंकड़ों के अनुसार, 'जॉन सिना' ने 2 पुस्तकें उधार लीं और 'एला हसन' ने 1 पुस्तक उधार ली।

डुप्लिकेट मानों को हटाने के बाद तालिका पढ़ें
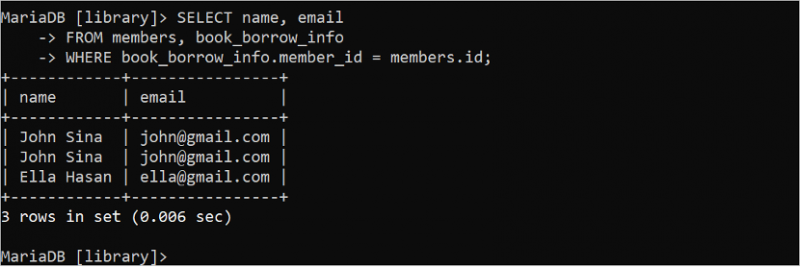
कभी-कभी, तालिका डेटा के आधार पर SELECT स्टेटमेंट के परिणाम सेट में डुप्लिकेट डेटा उत्पन्न होता है जो अनावश्यक है। उदाहरण के लिए, निम्नलिखित SELECT स्टेटमेंट 'book_borrow_info' तालिका के डेटा के लिए डुप्लिकेट रिकॉर्ड लौटाता है।
चुनना नाम , ईमेलसे सदस्यों , पुस्तक_उधार_जानकारी
कहाँ पुस्तक_उधार_जानकारी . सदस्य पहचान पत्र = सदस्यों . पहचान;
आउटपुट में, एक ही रिकॉर्ड दो बार दिखाई देता है क्योंकि 'जॉन सिना' सदस्य ने दो किताबें उधार ली थीं। इस समस्या को DISTINCT कीवर्ड का उपयोग करके हल किया जा सकता है। यह क्वेरी परिणाम से डुप्लिकेट रिकॉर्ड हटा देता है।
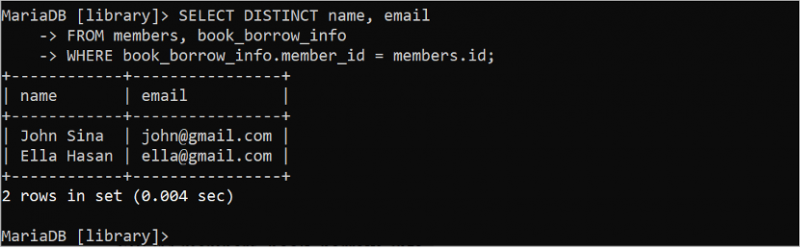
निम्न चयन कथन क्वेरी में DISTINCT कीवर्ड का उपयोग करके डुप्लिकेट मानों को छोड़ने के बाद 'सदस्यों' और 'book_borrow_info' तालिकाओं से सेट परिणाम के अद्वितीय रिकॉर्ड उत्पन्न करता है।
चुनना अलग नाम , ईमेलसे सदस्यों , पुस्तक_उधार_जानकारी
कहाँ पुस्तक_उधार_जानकारी . सदस्य पहचान पत्र = सदस्यों . पहचान;
आउटपुट दिखाता है कि परिणाम सेट से डुप्लिकेट मान हटा दिया गया है:
पंक्ति संख्या को सीमित करके तालिका पढ़ें
कभी-कभी, पंक्ति संख्या को सीमित करके डेटाबेस तालिका से परिणाम सेट की शुरुआत, परिणाम सेट के अंत, या परिणाम सेट के मध्य से रिकॉर्ड की विशेष संख्या को पढ़ने की आवश्यकता होती है। इसे कई तरीकों से किया जा सकता है. पंक्तियों को सीमित करने से पहले, पुस्तकें तालिका में कितने रिकॉर्ड मौजूद हैं यह जाँचने के लिए निम्नलिखित SQL कथन चलाएँ:
चुनना * से पुस्तकें;आउटपुट से पता चलता है कि पुस्तकें तालिका में चार रिकॉर्ड हैं:

निम्नलिखित चयन कथन 2 के मान के साथ LIMIT क्लॉज का उपयोग करके 'पुस्तकें' तालिका से पहले दो रिकॉर्ड पढ़ता है:
चुनना * से पुस्तकें आप LIMIT 2 ;'पुस्तकें' तालिका के पहले दो रिकॉर्ड पुनर्प्राप्त किए गए हैं जो आउटपुट में दिखाए गए हैं:

FETCH क्लॉज LIMIT क्लॉज का विकल्प है और इसका उपयोग निम्नलिखित SELECT स्टेटमेंट में दिखाया गया है। 'किताबें' तालिका के पहले 3 रिकॉर्ड SELECT स्टेटमेंट में केवल FETCH FIRST 3 ROWS क्लॉज का उपयोग करके पुनर्प्राप्त किए जाते हैं:
चुनना * से किताबें लायें पहला 3 पंक्तियों केवल ;आउटपुट 'किताबें' तालिका के पहले 3 रिकॉर्ड दिखाता है:

3 से दो रिकॉर्ड तृतीय निम्नलिखित SELECT कथन को क्रियान्वित करके पुस्तक तालिका की पंक्ति को पुनः प्राप्त किया जाता है। LIMIT क्लॉज का उपयोग यहां 2, 2 मान के साथ किया जाता है जहां पहला 2 तालिका की पंक्ति की प्रारंभिक स्थिति को परिभाषित करता है जो 0 से गिनती शुरू करता है और दूसरा 2 पंक्तियों की संख्या को परिभाषित करता है जो शुरुआती स्थिति से गिनती शुरू करता है।
चुनना * से पुस्तकें आप LIMIT 2 , 2 ;पिछली क्वेरी निष्पादित करने के बाद निम्नलिखित आउटपुट दिखाई देता है:

तालिका के अंत से रिकॉर्ड को स्वचालित रूप से बढ़े हुए प्राथमिक कुंजी मान के आधार पर तालिका को अवरोही क्रम में क्रमबद्ध करके और LIMIT क्लॉज का उपयोग करके पढ़ा जा सकता है। निम्नलिखित चयन कथन चलाएँ जो 'पुस्तकें' तालिका से अंतिम 2 रिकॉर्ड पढ़ता है। यहां, परिणाम सेट को 'आईडी' फ़ील्ड के आधार पर अवरोही क्रम में क्रमबद्ध किया गया है।
चुनना * से पुस्तकें आदेश द्वारा पहचान वर्णन आप LIMIT 2 ;पुस्तक तालिका के अंतिम दो रिकॉर्ड निम्नलिखित आउटपुट में दिखाए गए हैं:

आंशिक मिलान के आधार पर तालिका पढ़ें
आंशिक मिलान द्वारा तालिका से रिकॉर्ड पुनर्प्राप्त करने के लिए LIKE क्लॉज का उपयोग '%' प्रतीक के साथ किया जाता है। निम्नलिखित चयन कथन 'किताबें' तालिका से रिकॉर्ड खोजता है जहां लेखक फ़ील्ड में LIKE क्लॉज का उपयोग करके मूल्य की शुरुआत में 'जॉन' होता है। यहां, खोज स्ट्रिंग के अंत में '%' प्रतीक का उपयोग किया जाता है।
चुनना * से पुस्तकें कहाँ लेखक पसंद 'जॉन%' ;'पुस्तकें' तालिका में केवल एक रिकॉर्ड मौजूद है जिसमें लेखक फ़ील्ड के मान की शुरुआत में 'जॉन' स्ट्रिंग शामिल है।

निम्नलिखित चयन कथन 'किताबें' तालिका से रिकॉर्ड खोजता है जहां प्रकाशन फ़ील्ड में LIKE क्लॉज का उपयोग करके मूल्य के अंत में 'लिमिटेड' होता है। यहां, खोज स्ट्रिंग की शुरुआत में '%' प्रतीक का उपयोग किया गया है:
चुनना * से पुस्तकें कहाँ प्रकाशन पसंद '%लिमिटेड' ;'पुस्तकें' तालिका में केवल एक रिकॉर्ड मौजूद है जिसमें प्रकाशन फ़ील्ड के अंत में 'लिमिटेड' स्ट्रिंग शामिल है।

निम्नलिखित चयन कथन 'किताबें' तालिका से रिकॉर्ड खोजता है जहां शीर्षक फ़ील्ड में LIKE क्लॉज का उपयोग करके कहीं भी मान में 'क्वेरीज़' शामिल हैं। यहां, खोज स्ट्रिंग के दोनों ओर '%' प्रतीक का उपयोग किया गया है:
चुनना * से पुस्तकें कहाँ शीर्षक पसंद '%प्रश्न%' ;'पुस्तकें' तालिका में केवल एक रिकॉर्ड मौजूद है जिसमें शीर्षक फ़ील्ड में 'प्रश्न' स्ट्रिंग शामिल है।

तालिका के विशेष क्षेत्र का योग गिनें
SUM() SQL का एक अन्य उपयोगी समुच्चय फ़ंक्शन है जो तालिका के किसी भी संख्यात्मक फ़ील्ड के मानों के योग की गणना करता है। यह फ़ंक्शन एक तर्क लेता है जो संख्यात्मक होना चाहिए। निम्नलिखित SQL कथन 'पुस्तकें' तालिका के मूल्य फ़ील्ड के सभी मानों के योग की गणना करता है जिसमें पूर्णांक मान शामिल हैं।
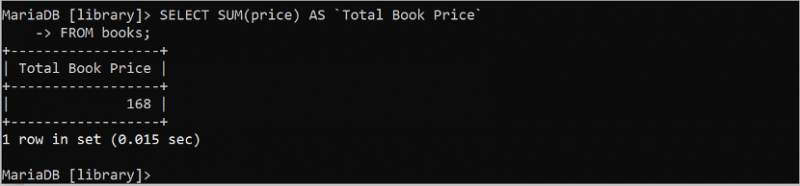
चुनना जोड़ ( कीमत ) जैसा 'कुल पुस्तक मूल्य'से पुस्तकें;
आउटपुट 'पुस्तकें' तालिका के मूल्य क्षेत्र के सभी मूल्यों का योग मूल्य दिखाता है। मूल्य फ़ील्ड के चार मान 39, 49, 35, और 45 हैं। इन मानों का योग 168 है।
विशेष फ़ील्ड के अधिकतम और न्यूनतम मान ज्ञात करें
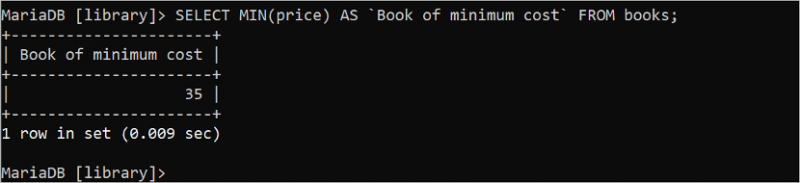
तालिका के विशेष क्षेत्र के न्यूनतम और अधिकतम मूल्यों का पता लगाने के लिए MIN() और MAX() समग्र फ़ंक्शन का उपयोग किया जाता है। दोनों फ़ंक्शन एक तर्क लेते हैं जो संख्यात्मक होना चाहिए। निम्नलिखित SQL कथन 'किताबें' तालिका से न्यूनतम मूल्य मान का पता लगाता है जो एक पूर्णांक है।
चुनना मिन ( कीमत ) जैसा `न्यूनतम लागत की पुस्तक` से पुस्तकें;पैंतीस (35) मूल्य फ़ील्ड का न्यूनतम मूल्य है जो आउटपुट में मुद्रित होता है।
निम्नलिखित SQL कथन 'पुस्तकें' तालिका से अधिकतम मूल्य मान का पता लगाता है:
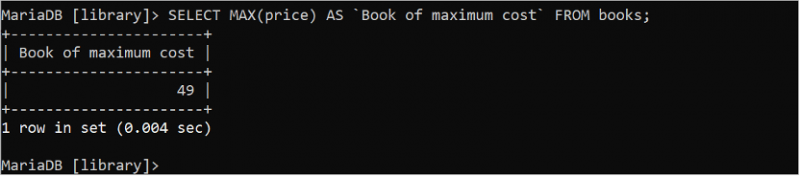
चुनना मैक्स ( कीमत ) जैसा `अधिकतम लागत की पुस्तक` से पुस्तकें;उनतालीस (49) मूल्य फ़ील्ड का अधिकतम मूल्य है जो आउटपुट में मुद्रित होता है।
डेटा या फ़ील्ड का विशेष भाग पढ़ें
SUBSTR() फ़ंक्शन का उपयोग SQL कथन में स्ट्रिंग डेटा के विशेष भाग या तालिका के विशेष फ़ील्ड के मान को पुनः प्राप्त करने के लिए किया जाता है। इस फ़ंक्शन में तीन तर्क हैं। पहले तर्क में स्ट्रिंग मान या तालिका का फ़ील्ड मान होता है जो एक स्ट्रिंग है। दूसरे तर्क में उप-स्ट्रिंग की प्रारंभिक स्थिति शामिल होती है जिसे पहले तर्क से पुनर्प्राप्त किया जाता है और इस मान की गिनती 1 से शुरू होती है। तीसरे तर्क में उप-स्ट्रिंग की लंबाई होती है जो शुरुआती स्थिति से गिनती शुरू होती है।
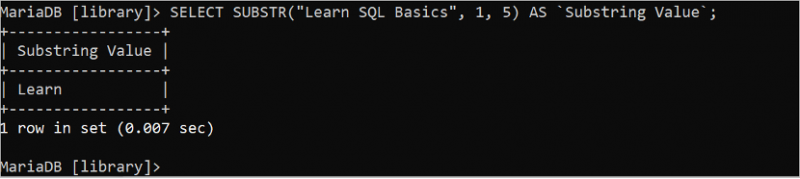
निम्नलिखित चयन कथन 'एसक्यूएल मूल बातें सीखें' स्ट्रिंग से पहले पांच वर्णों को काटता है और प्रिंट करता है जहां प्रारंभिक स्थिति 1 है और लंबाई 5 है:
चुनना सबस्ट्र ( 'SQL मूल बातें सीखें' , 1 , 5 ) जैसा `सबस्ट्रिंग वैल्यू` ;'एसक्यूएल मूल बातें सीखें' स्ट्रिंग के पहले पांच अक्षर 'सीखें' हैं जो आउटपुट में मुद्रित होते हैं।
निम्नलिखित चयन कथन SQL को 'SQL मूल बातें सीखें' स्ट्रिंग से काटता है और प्रिंट करता है जहां प्रारंभिक स्थिति 7 है और लंबाई 3 है:
चुनना सबस्ट्र ( 'SQL मूल बातें सीखें' , 7 , 3 ) जैसा `सबस्ट्रिंग वैल्यू` ;पिछली क्वेरी निष्पादित करने के बाद निम्नलिखित आउटपुट दिखाई देता है:

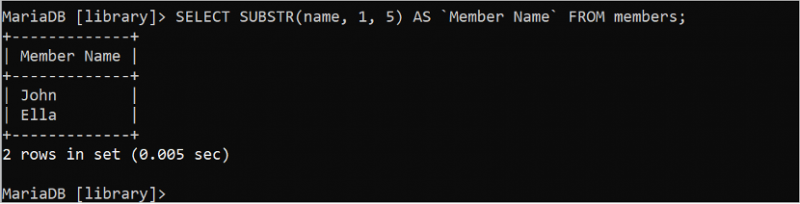
निम्नलिखित चयन कथन 'सदस्यों' तालिका के नाम फ़ील्ड से पहले पांच वर्णों को काटता और प्रिंट करता है:
चुनना सबस्ट्र ( नाम , 1 , 5 ) जैसा `सदस्य का नाम` से सदस्य;आउटपुट 'सदस्य' तालिका के नाम फ़ील्ड के प्रत्येक मान के पहले पांच अक्षर दिखाता है।
संयोजन के बाद तालिका डेटा पढ़ें
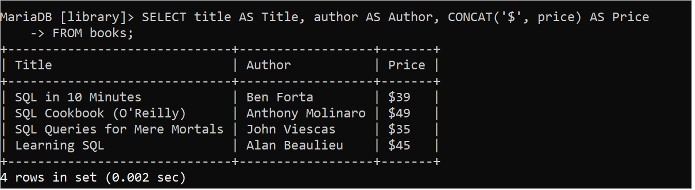
CONCAT() फ़ंक्शन का उपयोग किसी तालिका के एक या अधिक फ़ील्ड को संयोजित करके या स्ट्रिंग डेटा या तालिका के विशेष फ़ील्ड मान को जोड़कर आउटपुट उत्पन्न करने के लिए किया जाता है। निम्नलिखित SQL कथन 'पुस्तकें' तालिका के शीर्षक, लेखक और मूल्य फ़ील्ड के मानों को पढ़ता है, और CONCAT() फ़ंक्शन का उपयोग करके मूल्य फ़ील्ड के प्रत्येक मान के साथ '$' स्ट्रिंग मान जोड़ा जाता है।
चुनना शीर्षक जैसा शीर्षक , लेखक जैसा लेखक , concat ( '$' , कीमत ) जैसा कीमतसे पुस्तकें;
मूल्य फ़ील्ड के मान आउटपुट में '$' स्ट्रिंग के साथ संयोजित करके मुद्रित किए जाते हैं।
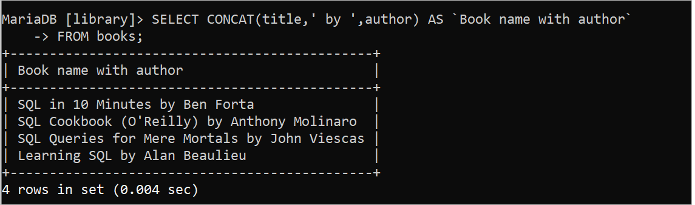
CONCAT() फ़ंक्शन का उपयोग करके 'किताबें' तालिका के शीर्षक और लेखक फ़ील्ड के मानों को 'द्वारा' स्ट्रिंग मान के साथ संयोजित करने के लिए निम्नलिखित SQL कथन चलाएँ:
चुनना concat ( शीर्षक , ' द्वारा ' , लेखक ) जैसा `लेखक के साथ पुस्तक का नाम`से पुस्तकें;
पिछली SELECT क्वेरी को निष्पादित करने के बाद निम्नलिखित आउटपुट दिखाई देता है:
गणितीय गणना के बाद तालिका डेटा पढ़ें
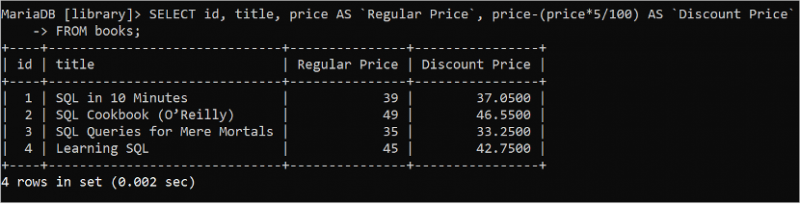
SELECT स्टेटमेंट का उपयोग करके तालिका के मान प्राप्त करते समय कोई भी गणितीय गणना की जा सकती है। 5% छूट की गणना के बाद आईडी, शीर्षक, मूल्य और रियायती मूल्य मूल्य को पढ़ने के लिए निम्नलिखित SQL कथन चलाएँ।
चुनना पहचान , शीर्षक , कीमत जैसा `नियमित कीमत` , कीमत - ( कीमत * 5 / 100 ) जैसा `छूट मूल्य`से पुस्तकें;
निम्नलिखित आउटपुट प्रत्येक पुस्तक का नियमित मूल्य और छूट मूल्य दर्शाता है:
तालिका का एक दृश्य बनाएं
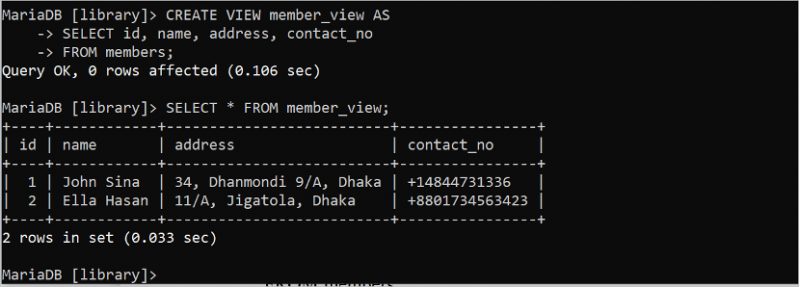
VIEW का उपयोग क्वेरी को सरल बनाने और डेटाबेस को अतिरिक्त सुरक्षा प्रदान करने के लिए किया जाता है। यह एक वर्चुअल टेबल की तरह काम करता है जो एक या अधिक टेबल से उत्पन्न होता है। 'सदस्य' तालिका के आधार पर एक सरल दृश्य बनाने और निष्पादित करने की विधि निम्नलिखित उदाहरण में दिखाई गई है। दृश्य को SELECT कथन का उपयोग करके निष्पादित किया जाता है। निम्नलिखित SQL कथन आईडी, नाम, पता और contact_no फ़ील्ड के साथ 'सदस्य' तालिका का एक दृश्य बनाता है। SELECT स्टेटमेंट member_view को निष्पादित करता है।
बनाएं देखना सदस्य_दृश्य जैसाचुनना पहचान , नाम , पता , संपर्क नंबर
से सदस्य;
चुनना * से सदस्य_दृश्य;
दृश्य बनाने और निष्पादित करने के बाद निम्नलिखित आउटपुट दिखाई देता है:
विशेष स्थिति के आधार पर तालिका को अद्यतन करें
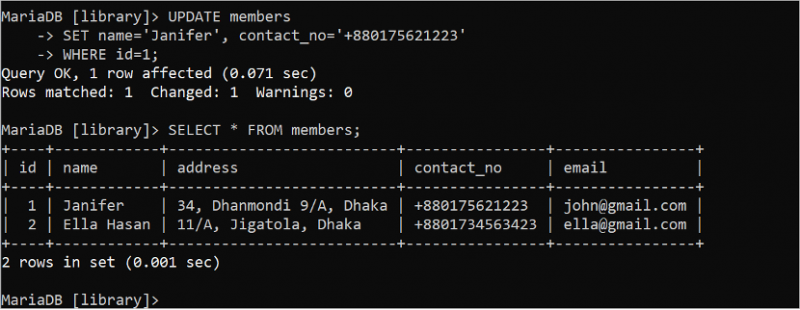
अद्यतन कथन का उपयोग तालिका की सामग्री को अद्यतन करने के लिए किया जाता है। यदि किसी भी अद्यतन क्वेरी को WHERE क्लॉज के बिना निष्पादित किया जाता है, तो अद्यतन क्वेरी में उपयोग किए जाने वाले सभी फ़ील्ड अपडेट हो जाते हैं। इसलिए, उचित WHERE क्लॉज़ के साथ UPDATE स्टेटमेंट का उपयोग करना आवश्यक है। नाम और contact_no फ़ील्ड को अद्यतन करने के लिए निम्नलिखित अद्यतन कथन चलाएँ जहाँ id फ़ील्ड का मान 1 है। इसके बाद, यह जाँचने के लिए SELECT कथन निष्पादित करें कि डेटा ठीक से अपडेट किया गया है या नहीं।
अद्यतन सदस्योंतय करना नाम = 'जेनिफर' , संपर्क नंबर = '+880175621223'
कहाँ पहचान = 1 ;
चुनना * से सदस्य;
निम्नलिखित आउटपुट दिखाता है कि अद्यतन कथन सफलतापूर्वक निष्पादित किया गया है। नाम फ़ील्ड का मान 'जेनिफ़र' में बदल दिया गया है और संपर्क_नो फ़ील्ड को रिकॉर्ड के '+880175621223' में बदल दिया गया है जिसमें अद्यतन क्वेरी का उपयोग करके 1 का आईडी मान शामिल है:
विशेष स्थिति के आधार पर तालिका डेटा हटाएँ
DELETE स्टेटमेंट का उपयोग विशिष्ट सामग्री या तालिका की सभी सामग्री को हटाने के लिए किया जाता है। यदि कोई DELETE क्वेरी WHERE क्लॉज के बिना निष्पादित की जाती है, तो सभी फ़ील्ड हटा दिए जाते हैं। इसलिए, उचित WHERE क्लॉज के साथ UPDATE स्टेटमेंट का उपयोग करना आवश्यक है। पुस्तकें तालिका से सभी डेटा को हटाने के लिए निम्नलिखित DELETE स्टेटमेंट चलाएँ जहाँ id मान 4 है। इसके बाद, यह जाँचने के लिए SELECT स्टेटमेंट निष्पादित करें कि डेटा ठीक से डिलीट हुआ है या नहीं।
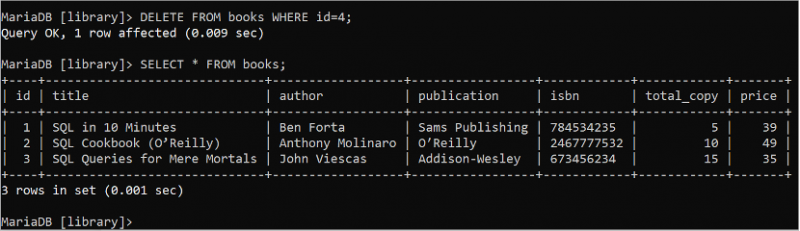
मिटाना से पुस्तकें कहाँ पहचान = 4 ;चुनना * से पुस्तकें;
निम्नलिखित आउटपुट दिखाता है कि DELETE कथन सफलतापूर्वक निष्पादित किया गया है। 4 वां DELETE क्वेरी का उपयोग करके पुस्तक तालिका का रिकॉर्ड हटा दिया जाता है:
तालिका से सभी रिकॉर्ड हटाएँ
'पुस्तकें' तालिका से सभी रिकॉर्ड हटाने के लिए निम्नलिखित DELETE कथन चलाएँ जहाँ WHERE क्लॉज़ हटा दिया गया है। इसके बाद, तालिका सामग्री की जांच करने के लिए SELECT क्वेरी निष्पादित करें।
मिटाना से पुस्तक_उधार_जानकारी;चुनना * से पुस्तक_उधार_जानकारी;
निम्नलिखित आउटपुट दिखाता है कि DELETE क्वेरी निष्पादित करने के बाद 'पुस्तकें' तालिका खाली है:

यदि किसी तालिका में एक ऑटो-इंक्रीमेंट विशेषता होती है और तालिका से सभी रिकॉर्ड हटा दिए जाते हैं, तो तालिका को खाली करने के बाद एक नया रिकॉर्ड डालने पर ऑटो-इंक्रीमेंट फ़ील्ड अंतिम वृद्धि से गिनती शुरू कर देती है। इस समस्या को TRUNCATE स्टेटमेंट का उपयोग करके हल किया जा सकता है। इसका उपयोग तालिका से सभी रिकॉर्ड हटाने के लिए भी किया जाता है लेकिन तालिका से सभी रिकॉर्ड हटाने के बाद ऑटो-इंक्रीमेंट फ़ील्ड की गिनती 1 से शुरू होती है। TRUNCATE कथन का SQL निम्नलिखित में दिखाया गया है:
काट-छांट पुस्तक_उधार_जानकारी;टेबल गिराओ
एक या अधिक तालिकाओं को जाँच करके या बिना यह जाँचे कि तालिका मौजूद है या नहीं, गिराई जा सकती है। निम्नलिखित DROP कथन 'book_borrow_info' तालिका को हटा देते हैं और 'तालिकाएँ दिखाएं' कथन जाँचता है कि तालिका सर्वर पर मौजूद है या नहीं।
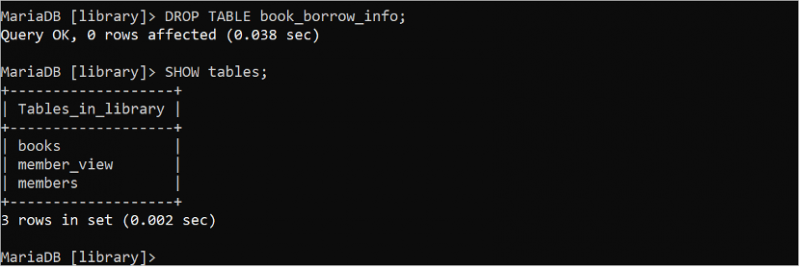
बूँद मेज पुस्तक_उधार_जानकारी;दिखाना तालिकाएं ;
आउटपुट से पता चलता है कि 'book_borrow_info' तालिका हटा दी गई है।
तालिका सर्वर पर मौजूद है या नहीं इसकी जाँच करने के बाद उसे हटाया जा सकता है। यदि ये तालिकाएँ सर्वर में मौजूद हैं तो पुस्तकों और सदस्यों की तालिका को हटाने के लिए निम्नलिखित DROP कथन चलाएँ। इसके बाद, 'तालिकाएँ दिखाएं' कथन जाँचता है कि तालिकाएँ सर्वर पर मौजूद हैं या नहीं।
बूँद मेज अगर मौजूद पुस्तकें , सदस्य;दिखाना तालिकाएं ;
निम्न आउटपुट दिखाता है कि तालिकाएँ सर्वर से हटा दी गई हैं:

डेटाबेस छोड़ें
सर्वर से 'लाइब्रेरी' डेटाबेस को हटाने के लिए निम्नलिखित SQL कथन चलाएँ:
बूँद डेटाबेस पुस्तकालय;आउटपुट दिखाता है कि डेटाबेस हटा दिया गया है।

निष्कर्ष
MariaDB सर्वर के डेटाबेस को बनाने, एक्सेस करने, संशोधित करने और हटाने के लिए अधिकतर उपयोग किए जाने वाले SQL क्वेरी उदाहरण इस ट्यूटोरियल में एक डेटाबेस और तीन तालिकाएँ बनाकर दिखाए गए हैं। नए डेटाबेस उपयोगकर्ता को SQL मूल बातें ठीक से सीखने में मदद करने के लिए विभिन्न SQL कथनों के उपयोग को बहुत सरल उदाहरणों के साथ समझाया गया है। जटिल प्रश्नों का उपयोग यहां छोड़ दिया गया है। नए डेटाबेस उपयोगकर्ता इस ट्यूटोरियल को ठीक से पढ़ने के बाद किसी भी डेटाबेस के साथ काम करना शुरू कर सकेंगे।