यह मार्गदर्शिका लैंगचेन में इकाई मेमोरी का उपयोग करने की प्रक्रिया का वर्णन करेगी।
लैंगचेन में एंटिटी मेमोरी का उपयोग कैसे करें?
इकाई का उपयोग मानव द्वारा पूछे जाने पर प्रश्नों/संकेतों का उपयोग करके निकालने के लिए स्मृति में संग्रहीत प्रमुख तथ्यों को रखने के लिए किया जाता है। लैंगचेन में इकाई मेमोरी का उपयोग करने की प्रक्रिया सीखने के लिए, बस निम्नलिखित गाइड पर जाएँ:
चरण 1: मॉड्यूल स्थापित करें
सबसे पहले, इसकी निर्भरता प्राप्त करने के लिए पाइप कमांड का उपयोग करके लैंगचेन मॉड्यूल स्थापित करें:
पाइप लैंगचैन स्थापित करें
उसके बाद, एलएलएम और चैट मॉडल के निर्माण के लिए इसकी लाइब्रेरी प्राप्त करने के लिए ओपनएआई मॉड्यूल स्थापित करें:
पिप इंस्टाल ओपनाई
OpenAI वातावरण सेटअप करें एपीआई कुंजी का उपयोग करना जिसे ओपनएआई खाते से निकाला जा सकता है:
आयात आप
आयात पास ले लो
आप . लगभग [ 'OPENAI_API_KEY' ] = पास ले लो . पास ले लो ( 'ओपनएआई एपीआई कुंजी:' )
चरण 2: एंटिटी मेमोरी का उपयोग करना
इकाई मेमोरी का उपयोग करने के लिए, OpenAI() विधि का उपयोग करके एलएलएम बनाने के लिए आवश्यक लाइब्रेरी आयात करें:
से लैंगचैन. एलएमएस आयात ओपनएआईसे लैंगचैन. याद आयात कन्वर्सेशनएंटिटीमेमोरी
एलएलएम = ओपनएआई ( तापमान = 0 )
उसके बाद, परिभाषित करें याद इनपुट और आउटपुट वेरिएबल का उपयोग करके मॉडल को प्रशिक्षित करने के लिए ConversationEntityMemory() विधि का उपयोग करके वेरिएबल:
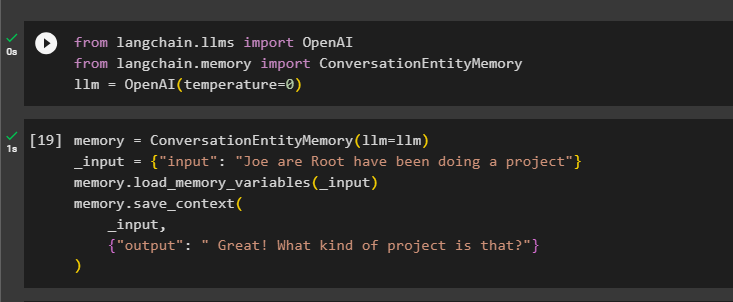
याद = कन्वर्सेशनएंटिटीमेमोरी ( एलएलएम = एलएलएम )_इनपुट = { 'इनपुट' : 'जो रूट एक प्रोजेक्ट कर रहे हैं' }
याद। लोड_मेमोरी_वेरिएबल्स ( _इनपुट )
याद। save_context (
_इनपुट ,
{ 'आउटपुट' : 'बहुत बढ़िया! वह किस तरह का प्रोजेक्ट है?' }
)
अब, क्वेरी/प्रॉम्प्ट का उपयोग करके मेमोरी का परीक्षण करें इनपुट लोड_मेमोरी_वेरिएबल्स() विधि को कॉल करके वैरिएबल:
याद। लोड_मेमोरी_वेरिएबल्स ( { 'इनपुट' : 'रूट कौन है' } ) 
अब, कुछ और जानकारी दें ताकि मॉडल मेमोरी में कुछ और इकाइयाँ जोड़ सके:
याद = कन्वर्सेशनएंटिटीमेमोरी ( एलएलएम = एलएलएम , वापसी_संदेश = सत्य )_इनपुट = { 'इनपुट' : 'जो रूट एक प्रोजेक्ट कर रहे हैं' }
याद। लोड_मेमोरी_वेरिएबल्स ( _इनपुट )
याद। save_context (
_इनपुट ,
{ 'आउटपुट' : 'बहुत बढ़िया! यह किस तरह का प्रोजेक्ट है' }
)
मेमोरी में संग्रहीत इकाइयों का उपयोग करके आउटपुट प्राप्त करने के लिए निम्नलिखित कोड निष्पादित करें। के माध्यम से यह संभव है इनपुट संकेत युक्त:
याद। लोड_मेमोरी_वेरिएबल्स ( { 'इनपुट' : 'कौन है जो' } ) 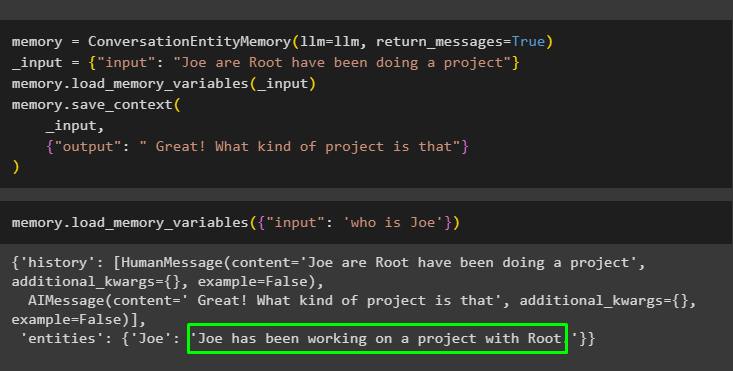
चरण 3: एक श्रृंखला में एंटिटी मेमोरी का उपयोग करना
श्रृंखला बनाने के बाद इकाई मेमोरी का उपयोग करने के लिए, बस निम्नलिखित कोड ब्लॉक का उपयोग करके आवश्यक लाइब्रेरी आयात करें:
से लैंगचैन. चेन आयात वार्तालाप शृंखलासे लैंगचैन. याद आयात कन्वर्सेशनएंटिटीमेमोरी
से लैंगचैन. याद . तत्पर आयात ENTITY_MEMORY_CONVERSATION_TEMPLATE
से pydantic आयात बेसमॉडल
से टाइपिंग आयात सूची , हुक्म , कोई
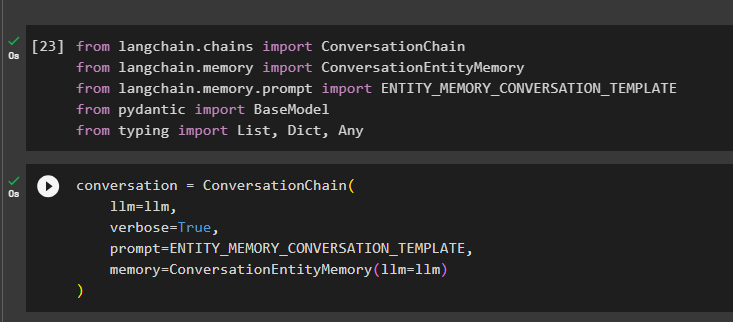
एलएलएम जैसे तर्कों का उपयोग करके कन्वर्सेशनचेन() विधि का उपयोग करके वार्तालाप मॉडल बनाएं:
बातचीत = वार्तालाप शृंखला (एलएलएम = एलएलएम ,
वाचाल = सत्य ,
तत्पर = ENTITY_MEMORY_CONVERSATION_TEMPLATE ,
याद = कन्वर्सेशनएंटिटीमेमोरी ( एलएलएम = एलएलएम )
)
प्रॉम्प्ट या क्वेरी के साथ आरंभ किए गए इनपुट के साथ वार्तालाप.भविष्यवाणी() विधि को कॉल करें:
बातचीत। भविष्यवाणी करना ( इनपुट = 'जो रूट एक प्रोजेक्ट कर रहे हैं' ) 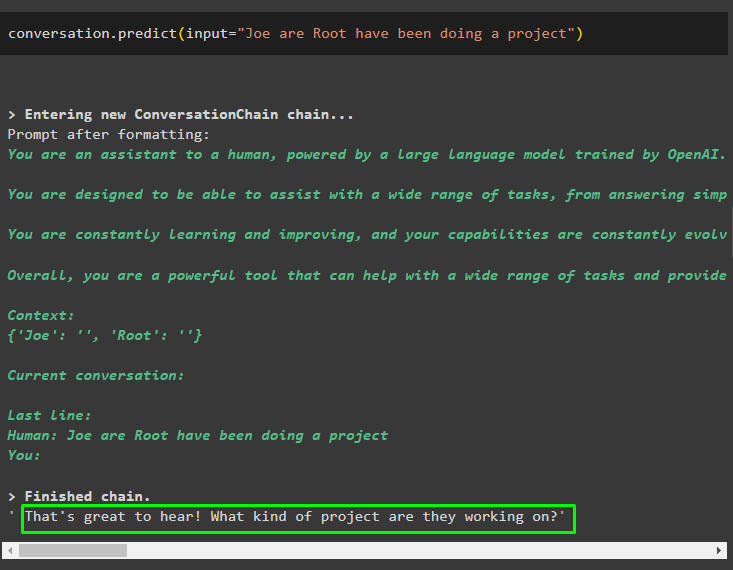
अब, प्रत्येक इकाई के बारे में जानकारी का वर्णन करने वाला अलग आउटपुट प्राप्त करें:
बातचीत। याद . इकाई_स्टोर . इकट्ठा करना 
इनपुट देने के लिए मॉडल से आउटपुट का उपयोग करें ताकि मॉडल इन संस्थाओं के बारे में अधिक जानकारी संग्रहीत कर सके:
बातचीत। भविष्यवाणी करना ( इनपुट = 'वे लैंगचैन में अधिक जटिल मेमोरी संरचनाएं जोड़ने का प्रयास कर रहे हैं' ) 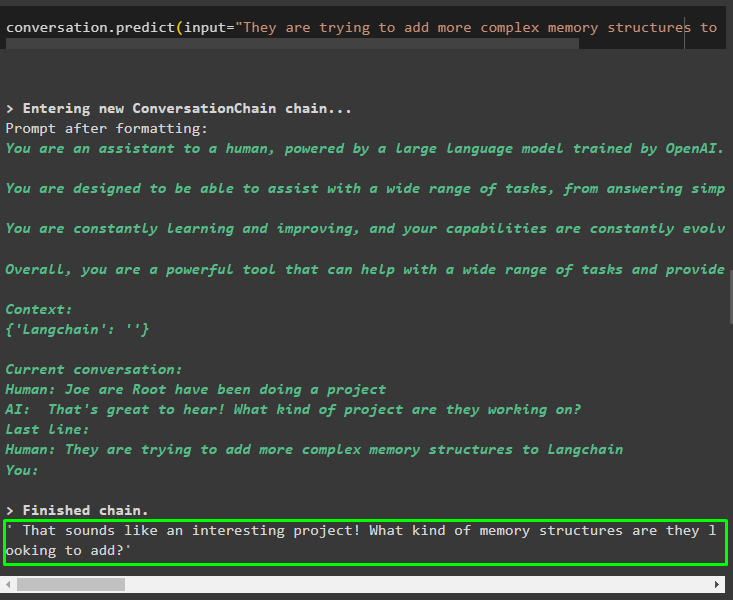
मेमोरी में संग्रहीत जानकारी देने के बाद, संस्थाओं के बारे में विशिष्ट जानकारी निकालने के लिए बस प्रश्न पूछें:
बातचीत। भविष्यवाणी करना ( इनपुट = 'आप जो और रूट के बारे में क्या जानते हैं' ) 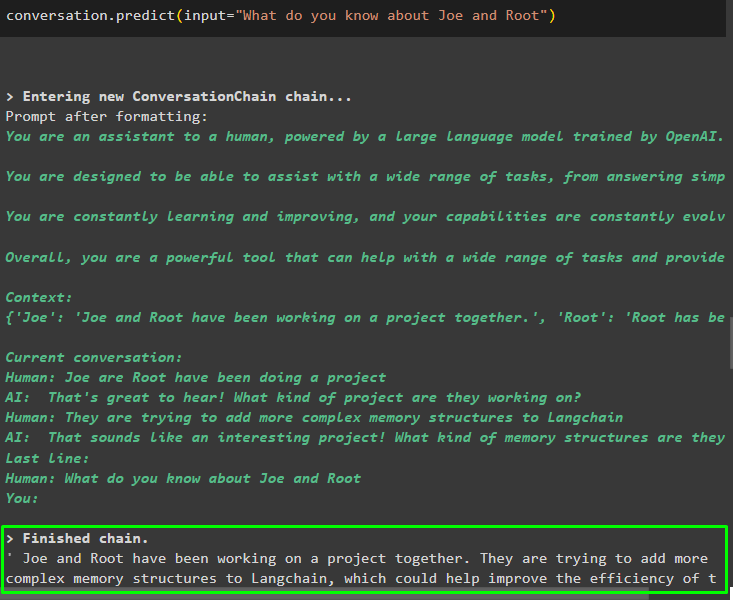
चरण 4: मेमोरी स्टोर का परीक्षण
उपयोगकर्ता निम्नलिखित कोड का उपयोग करके उनमें संग्रहीत जानकारी प्राप्त करने के लिए सीधे मेमोरी स्टोर का निरीक्षण कर सकता है:
से छपाई आयात छपाईछपाई ( बातचीत। याद . इकाई_स्टोर . इकट्ठा करना )
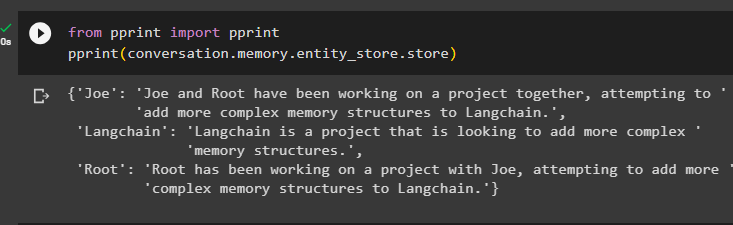
मेमोरी में संग्रहीत करने के लिए अधिक जानकारी प्रदान करें क्योंकि अधिक जानकारी अधिक सटीक परिणाम देती है:
बातचीत। भविष्यवाणी करना ( इनपुट = 'रूट ने HJRS नामक एक व्यवसाय की स्थापना की है' ) 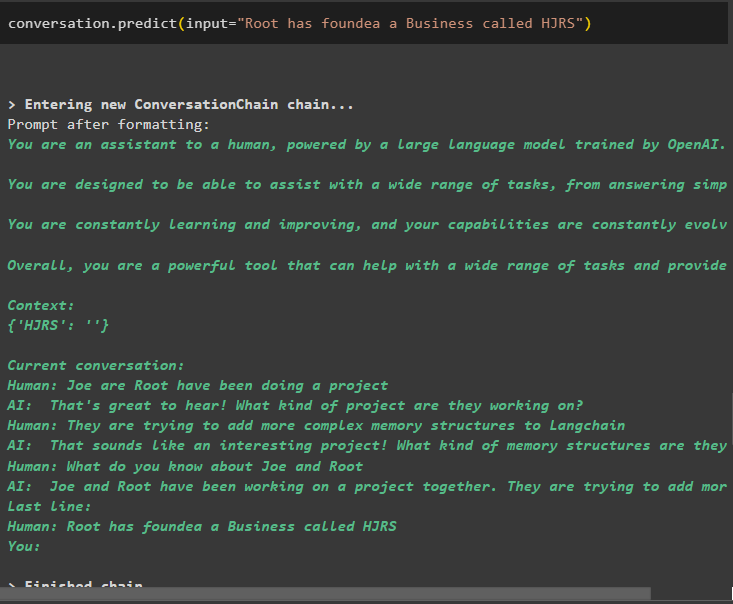
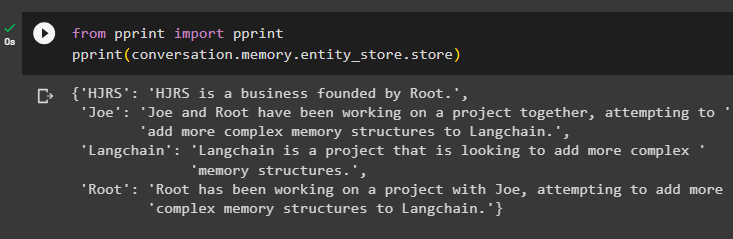
इकाइयों के बारे में अधिक जानकारी जोड़ने के बाद मेमोरी स्टोर से जानकारी निकालें:
से छपाई आयात छपाईछपाई ( बातचीत। याद . इकाई_स्टोर . इकट्ठा करना )
मेमोरी में HJRS, जो, लैंगचेन और रूट जैसी कई संस्थाओं के बारे में जानकारी है:
अब इनपुट वेरिएबल में परिभाषित क्वेरी या प्रॉम्प्ट का उपयोग करके किसी विशिष्ट इकाई के बारे में जानकारी निकालें:
बातचीत। भविष्यवाणी करना ( इनपुट = 'आप रूट के बारे में क्या जानते हैं' ) 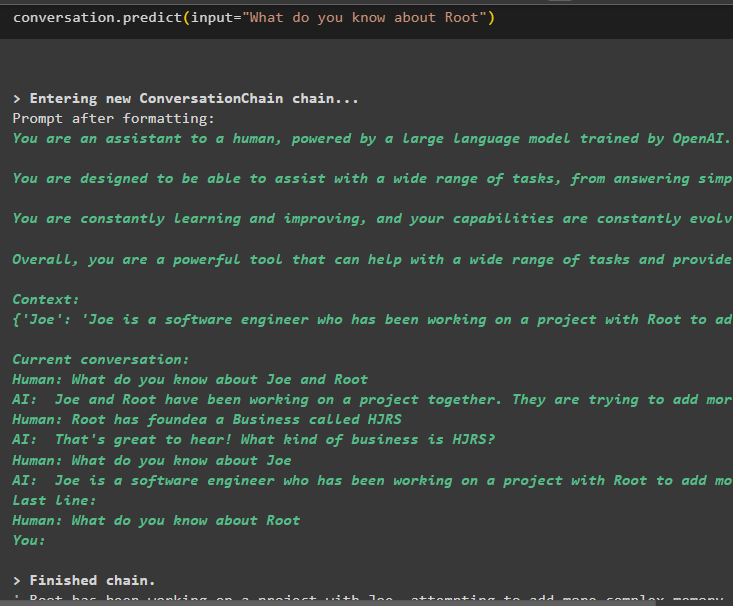
यह सब लैंगचेन फ्रेमवर्क का उपयोग करके इकाई मेमोरी का उपयोग करने के बारे में है।
निष्कर्ष
लैंगचेन में इकाई मेमोरी का उपयोग करने के लिए, ओपनएआई वातावरण स्थापित करने के बाद मॉडल बनाने के लिए आवश्यक लाइब्रेरी आयात करने के लिए बस आवश्यक मॉड्यूल स्थापित करें। उसके बाद, एलएलएम मॉडल बनाएं और इकाइयों के बारे में जानकारी प्रदान करके मेमोरी में इकाइयों को स्टोर करें। उपयोगकर्ता इन संस्थाओं का उपयोग करके जानकारी भी निकाल सकता है और संस्थाओं के बारे में उत्तेजित जानकारी के साथ श्रृंखलाओं में इन यादों का निर्माण कर सकता है। इस पोस्ट में लैंगचेन में इकाई मेमोरी का उपयोग करने की प्रक्रिया के बारे में विस्तार से बताया गया है।