यह मार्गदर्शिका लैंगचेन में वार्तालाप ज्ञान ग्राफ का उपयोग करने की प्रक्रिया का वर्णन करेगी।
लैंगचेन में वार्तालाप ज्ञान ग्राफ़ का उपयोग कैसे करें?
वार्तालापकेजीमेमोरी लाइब्रेरी का उपयोग मेमोरी को फिर से बनाने के लिए किया जा सकता है जिसका उपयोग इंटरैक्शन के संदर्भ को प्राप्त करने के लिए किया जा सकता है। लैंगचेन में वार्तालाप ज्ञान ग्राफ का उपयोग करने की प्रक्रिया सीखने के लिए, बस सूचीबद्ध चरणों से गुजरें:
चरण 1: मॉड्यूल स्थापित करें
सबसे पहले, लैंगचेन मॉड्यूल स्थापित करके वार्तालाप ज्ञान ग्राफ का उपयोग करने की प्रक्रिया शुरू करें:
पाइप लैंगचैन स्थापित करें
ओपनएआई मॉड्यूल स्थापित करें जिसे बड़े भाषा मॉडल के निर्माण के लिए अपनी लाइब्रेरी प्राप्त करने के लिए पिप कमांड का उपयोग करके स्थापित किया जा सकता है:
पिप इंस्टाल ओपनाई
अब, पर्यावरण स्थापित करें OpenAI API कुंजी का उपयोग करना जिसे उसके खाते से उत्पन्न किया जा सकता है:
आयात आप
आयात पास ले लो
आप . लगभग [ 'OPENAI_API_KEY' ] = पास ले लो . पास ले लो ( 'ओपनएआई एपीआई कुंजी:' )
चरण 2: एलएलएम के साथ मेमोरी का उपयोग करना
एक बार मॉड्यूल स्थापित हो जाने के बाद, लैंगचेन मॉड्यूल से आवश्यक लाइब्रेरी आयात करके एलएलएम के साथ मेमोरी का उपयोग शुरू करें:
से लैंगचैन. याद आयात वार्तालापकेजीमेमोरीसे लैंगचैन. एलएमएस आयात ओपनएआई
OpenAI() विधि का उपयोग करके एलएलएम बनाएं और मेमोरी का उपयोग करके कॉन्फ़िगर करें वार्तालापकेजीमेमोरी () तरीका। उसके बाद, इस डेटा पर मॉडल को प्रशिक्षित करने के लिए उनके संबंधित प्रतिक्रिया के साथ एकाधिक इनपुट का उपयोग करके प्रॉम्प्ट टेम्पलेट्स को सहेजें:
एलएलएम = ओपनएआई ( तापमान = 0 )याद = वार्तालापकेजीमेमोरी ( एलएलएम = एलएलएम )
याद। save_context ( { 'इनपुट' : 'जॉन को नमस्ते कहो' } , { 'आउटपुट' : 'जॉन! कौन' } )
याद। save_context ( { 'इनपुट' : 'वह एक दोस्त है' } , { 'आउटपुट' : 'ज़रूर' } )
को लोड करके मेमोरी का परीक्षण करें मेमोरी_वेरिएबल्स () उपरोक्त डेटा से संबंधित क्वेरी का उपयोग करने वाली विधि:
याद। लोड_मेमोरी_वेरिएबल्स ( { 'इनपुट' : 'जॉन कौन है' } ) 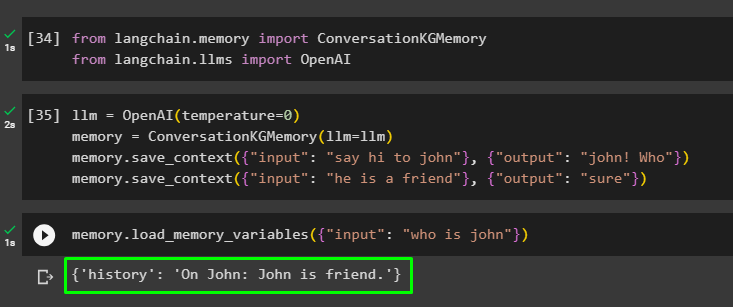
ConversationKGMemory() विधि का उपयोग करके मेमोरी को कॉन्फ़िगर करें वापसी_संदेश इनपुट का इतिहास भी प्राप्त करने का तर्क:
याद = वार्तालापकेजीमेमोरी ( एलएलएम = एलएलएम , वापसी_संदेश = सत्य )याद। save_context ( { 'इनपुट' : 'जॉन को नमस्ते कहो' } , { 'आउटपुट' : 'जॉन! कौन' } )
याद। save_context ( { 'इनपुट' : 'वह एक दोस्त है' } , { 'आउटपुट' : 'ज़रूर' } )
बस क्वेरी के रूप में इसके मूल्य के साथ इनपुट तर्क प्रदान करके मेमोरी का परीक्षण करें:
याद। लोड_मेमोरी_वेरिएबल्स ( { 'इनपुट' : 'जॉन कौन है' } ) 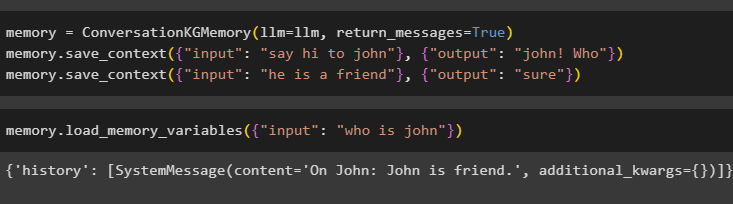
अब, उस प्रश्न को पूछकर स्मृति का परीक्षण करें जिसका उल्लेख प्रशिक्षण डेटा में नहीं है, और मॉडल को प्रतिक्रिया के बारे में कोई जानकारी नहीं है:
याद। get_current_entities ( 'जॉन का पसंदीदा रंग क्या है' )उपयोग ज्ञान_तीन_पाओ () पहले पूछे गए प्रश्न का उत्तर देकर विधि:
याद। ज्ञान_तीन_पाओ ( 'उसका पसंदीदा रंग लाल है' ) 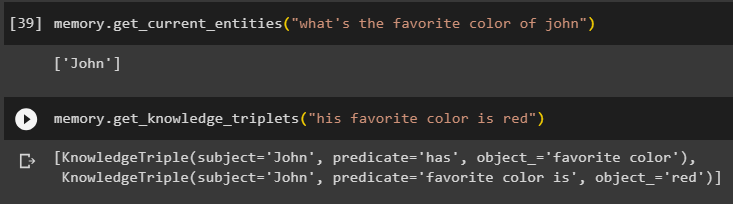
चरण 3: श्रृंखला में मेमोरी का उपयोग करना
अगला चरण OpenAI() पद्धति का उपयोग करके एलएलएम मॉडल बनाने के लिए श्रृंखलाओं के साथ वार्तालाप मेमोरी का उपयोग करता है। उसके बाद, वार्तालाप संरचना का उपयोग करके प्रॉम्प्ट टेम्पलेट को कॉन्फ़िगर करें और मॉडल द्वारा आउटपुट प्राप्त करते समय टेक्स्ट प्रदर्शित किया जाएगा:
एलएलएम = ओपनएआई ( तापमान = 0 )से लैंगचैन. संकेतों . तत्पर आयात संकेत टेम्पलेट
से लैंगचैन. चेन आयात वार्तालाप शृंखला
खाका = '''यह मानव और मशीन के बीच बातचीत का टेम्पलेट है
यह सिस्टम एक एआई मॉडल है जो कई पहलुओं के बारे में बात कर सकता है या जानकारी निकाल सकता है
यदि उसे प्रश्न समझ में नहीं आता है या उसके पास उत्तर नहीं है, तो वह बस ऐसा कह देता है
सिस्टम 'विशिष्ट' अनुभाग में संग्रहीत डेटा निकालता है और मतिभ्रम नहीं करता है
विशिष्ट:
{इतिहास}
बातचीत:
मानव: {इनपुट}
ऐ:'''
#संकेत प्रदान करने और एआई सिस्टम से प्रतिक्रिया प्राप्त करने के लिए टेम्पलेट या संरचना कॉन्फ़िगर करें
तत्पर = संकेत टेम्पलेट ( इनपुट_चर = [ 'इतिहास' , 'इनपुट' ] , खाका = खाका )
बातचीत_साथ_किलो = वार्तालाप शृंखला (
एलएलएम = एलएलएम , वाचाल = सत्य , तत्पर = तत्पर , याद = वार्तालापकेजीमेमोरी ( एलएलएम = एलएलएम )
)
एक बार मॉडल बन जाने के बाद, बस कॉल करें बातचीत_साथ_किलो उपयोगकर्ता द्वारा पूछे गए प्रश्न के साथ पूर्वानुमान () विधि का उपयोग करने वाला मॉडल:
बातचीत_साथ_किलो. भविष्यवाणी करना ( इनपुट = 'नमस्ते क्या हुआ?' ) 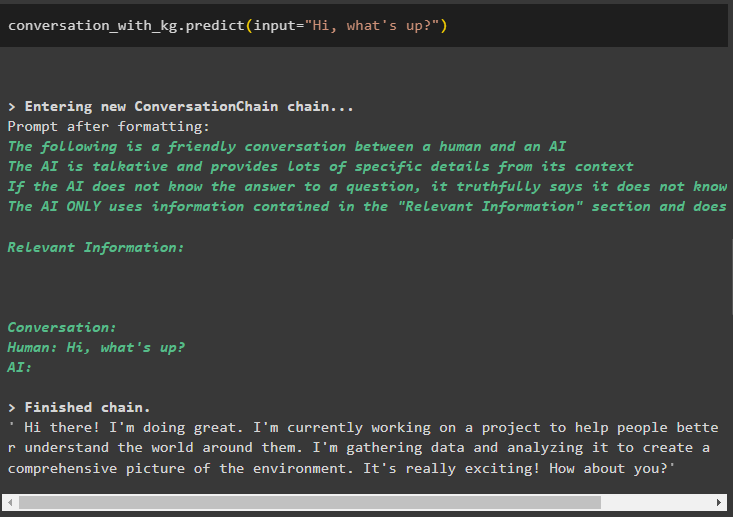
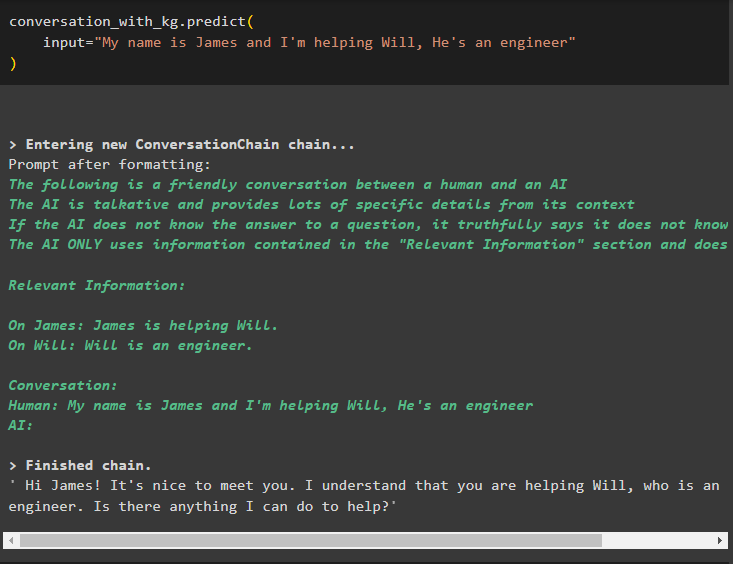
अब, विधि के लिए इनपुट तर्क के रूप में जानकारी देकर वार्तालाप मेमोरी का उपयोग करके मॉडल को प्रशिक्षित करें:
बातचीत_साथ_किलो. भविष्यवाणी करना (इनपुट = 'मेरा नाम जेम्स है और मैं विल की मदद कर रहा हूं, वह एक इंजीनियर है'
)
यहां डेटा से जानकारी निकालने के लिए प्रश्न पूछकर मॉडल का परीक्षण करने का समय है:
बातचीत_साथ_किलो. भविष्यवाणी करना ( इनपुट = 'कौन है विल' ) 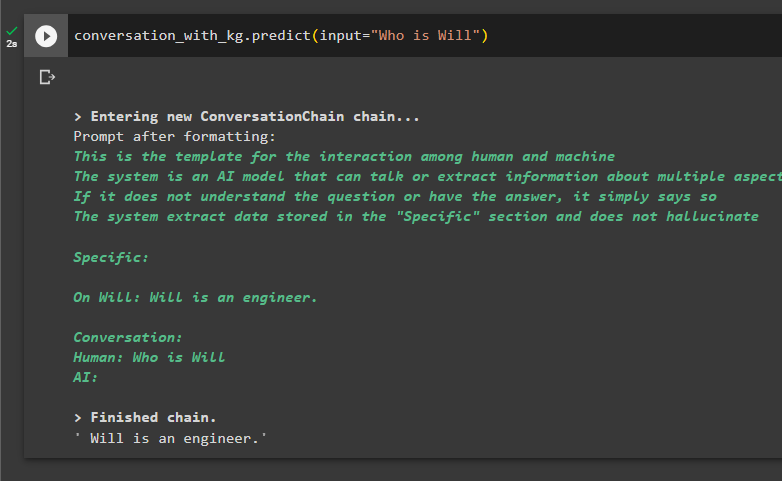
यह सब लैंगचेन में वार्तालाप ज्ञान ग्राफ का उपयोग करने के बारे में है।
निष्कर्ष
लैंगचेन में वार्तालाप ज्ञान ग्राफ का उपयोग करने के लिए, कन्वर्सेशनKGMemory() विधि का उपयोग करने के लिए लाइब्रेरी आयात करने के लिए मॉड्यूल या फ्रेमवर्क स्थापित करें। उसके बाद, चेन बनाने और कॉन्फ़िगरेशन में दिए गए प्रशिक्षण डेटा से जानकारी निकालने के लिए मेमोरी का उपयोग करके मॉडल बनाएं। इस गाइड में लैंगचेन में वार्तालाप ज्ञान ग्राफ का उपयोग करने की प्रक्रिया के बारे में विस्तार से बताया गया है।