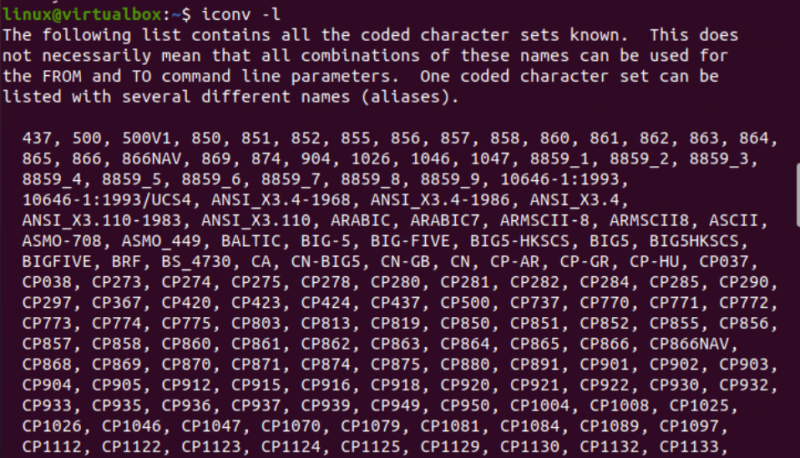
आइए अब इसके टर्मिनल कंसोल में Linux की iconv उपयोगिता को देखें। इसलिए, हम अपने टर्मिनल स्क्रीन पर सभी ज्ञात और सबसे अधिक उपयोग किए जाने वाले कोडित वर्ण सेट प्रदर्शित करने के लिए '-l' ध्वज के साथ 'iconv' निर्देश निष्पादित कर रहे हैं। यह उनके उपनामों के साथ कोडित वर्ण सेट प्रदर्शित करेगा। आप थोड़ा नीचे स्क्रॉल करने के बाद कोडित वर्ण सेट की एक लंबी सूची देख सकते हैं।
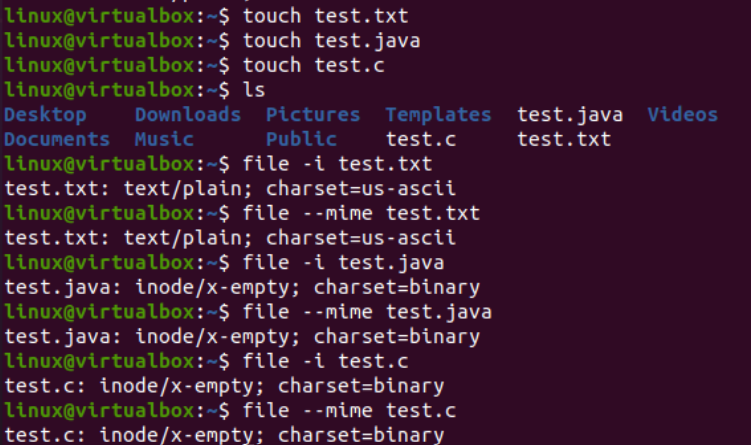
अब, लिनक्स में iconv कमांड के कार्यान्वयन के साथ आरंभ करने का समय आ गया है। सबसे पहले, हमें एक प्रकार की फाइल को दूसरे प्रकार की फाइल में बदलने के लिए हमारे सिस्टम में विभिन्न प्रकार की फाइलों की आवश्यकता होती है। इस प्रकार, हम तीन अलग-अलग फाइलें, यानी जावा टाइप, सी टाइप और टेक्स्ट टाइप बनाने के लिए कंसोल टर्मिनल पर 'टच' क्वेरी का उपयोग कर रहे हैं। वर्तमान निर्देशिका सामग्री को सूचीबद्ध करते हुए, आपको इसमें नई जनरेट की गई फ़ाइलें मिलेंगी।
इसके बाद, हम प्रत्येक फ़ाइल के नाम के साथ 'फ़ाइल' क्वेरी का उपयोग करके प्रत्येक फ़ाइल के प्रकार को अलग से देखेंगे। प्रत्येक फ़ाइल के लिए अलग से सेट किए गए कोडिंग वर्ण के प्रकार को प्रदर्शित करने के लिए इस क्वेरी को '-I' विकल्प की आवश्यकता होती है। यदि आप '-I' विकल्प का उपयोग करना भूल गए हैं, तो इसके बजाय '-माइम' ध्वज का उपयोग करें। दोनों '-I' और '-माइम' झंडे समान काम करते हैं।
अब, 'txt' प्रकार की फ़ाइल के लिए 'फ़ाइल' निर्देश निष्पादित करने के बाद, हमें 'US-ASCII' वर्ण प्रकार एन्कोडिंग मिला। जावा और सी फाइलों के लिए एक ही निर्देश का उपयोग करते समय, यह दर्शाता है कि दोनों फाइलों में 'बाइनरी' वर्ण प्रकार एन्कोडिंग है। साथ ही इस निर्देश से पता चलता है कि ये तीनों फाइलें खाली हैं।
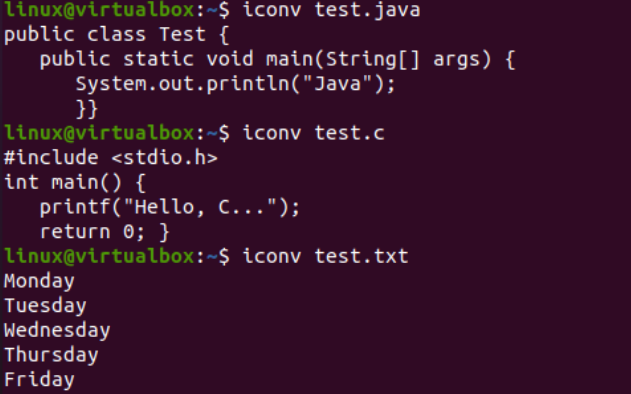
अब, हम एक विशिष्ट वर्ण सेट एन्कोडिंग फ़ाइल को दूसरे वर्ण सेट एन्कोडिंग में बदलने के लिए कंसोल पर iconv निर्देश के उपयोग का वर्णन करेंगे। इससे पहले, हमें अपनी फाइलों में कुछ कोड या डेटा जोड़ना होगा। इसलिए, हमने 'text.java' फ़ाइल के भीतर जावा कोड, 'text.c' फ़ाइल के भीतर C कोड, और 'test.txt' फ़ाइल में टेक्स्ट डेटा जोड़ा है। सभी तीन फाइलों की सामग्री को प्रदर्शित करने के लिए यहां कैट क्वेरी का उपयोग किया गया था, जैसा कि नीचे प्रस्तुत किया गया है:
अब जब हमने डेटा को सफलतापूर्वक जोड़ लिया है, तो हम एक बार फिर इन फाइलों के कैरेक्टर सेट एन्कोडिंग को देखेंगे। इसलिए, हमने शेल के भीतर '-I' ध्वज और फ़ाइल नामों, यानी, test.txt, test.java, और test.c के साथ एक ही फ़ाइल निर्देश की कोशिश की है। इन तीनों निर्देशों को तीनों फाइलों के लिए अलग-अलग चलाने से पता चलता है कि जावा और सी फाइलों के लिए कैरेक्टर सेट एन्कोडिंग को अपडेट कर दिया गया है, जबकि टेक्स्ट फाइल, यानी यूएस-एएससीआईआई के लिए वही रहता है। जावा और सी फाइलों की एन्कोडिंग पहले 'बाइनरी' थी; अब, यह 'यूएस-एएससीआईआई' है। साथ ही, यह दर्शाता है कि पाठ फ़ाइल में सादा पाठ डेटा होता है जबकि अन्य दो कोड फ़ाइलों में सामग्री के रूप में स्क्रिप्ट होती है।

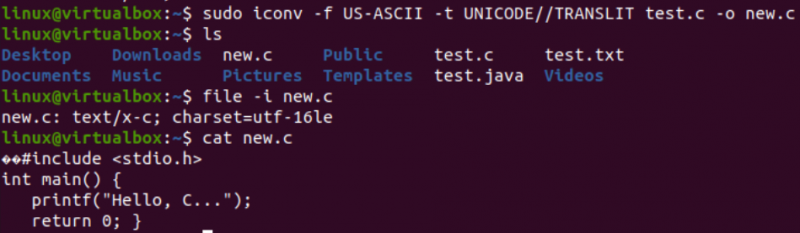
इस लेख के लिए आवश्यक वास्तविक कार्य को करने का समय आ गया है, अर्थात, शेल में iconv कमांड का उपयोग करके एक एन्कोडिंग को दूसरे में परिवर्तित करें। इस प्रकार, हम 'सुडो' विशेषाधिकारों के साथ शेल टर्मिनल के भीतर 'आइकनव' निर्देश का उपयोग कर रहे हैं। यह आदेश '-f' विकल्प 'से' के लिए खड़ा है, और '-t' विकल्प 'से' के लिए है, यानी, एक एन्कोडिंग से दूसरे में।
'-f' विकल्प के बाद, आपको अपनी फ़ाइल में पहले से मौजूद एन्कोडिंग को निर्दिष्ट करना होगा, अर्थात US-ASCII। जबकि '-t' विकल्प के बाद, आपको उस एन्कोडिंग को निर्दिष्ट करना होगा जिसे आप पुराने एन्कोडिंग, यानी यूनिकोड से बदलना चाहते हैं। आपको स्रोत के रूप में उपयोग की जाने वाली फ़ाइल का नाम निर्दिष्ट करना होगा - इसकी ऑब्जेक्ट छवि बनाने के लिए विकल्प के साथ। ऑब्जेक्ट छवि एक अन्य फ़ाइल होगी, अर्थात, 'new.c', उसी प्रकार की लेकिन नई एन्कोडिंग और समान डेटा के साथ।
निम्नलिखित निर्देश को निष्पादित करने के बाद, आपको उसी निर्देशिका में एक नई फ़ाइल मिलेगी, अर्थात 'ls' क्वेरी के अनुसार। अब, हम iconv निर्देश का उपयोग करके उत्पन्न एक नई फ़ाइल के वर्ण सेट एन्कोडिंग की जांच करेंगे। हम फिर से 'फ़ाइल' निर्देश का उपयोग '-I' विकल्प और नए फ़ाइल नाम, यानी new.c के साथ करेंगे।
आप देखेंगे कि इस नई फ़ाइल के लिए निर्धारित वर्ण एक पुरानी फ़ाइल के वर्ण सेट, यानी UTF-16LE वर्ण सेट से भिन्न है। ऐसा इसलिए है क्योंकि हमने अपनी new.c फ़ाइल के लिए iconv निर्देश का उपयोग करके US-ASCII एन्कोडिंग को UNICODE एन्कोडिंग में अनुवादित किया है। 'बिल्ली' क्वेरी ने फ़ाइल के भीतर समान सी कोड प्रदर्शित किया लेकिन कुछ यूनिकोड वर्णों के साथ शुरू किया, जैसा कि पहले ही प्रस्तुत किया गया है।
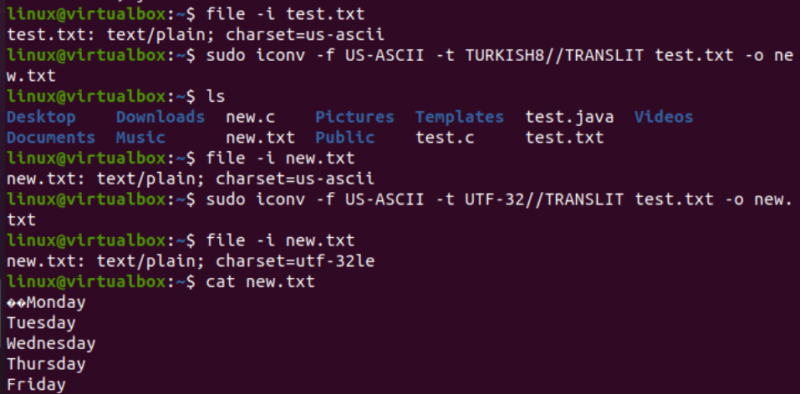
इसी तरह से, हम test.txt टेक्स्ट फ़ाइल की एन्कोडिंग को बदल देंगे। फ़ाइल निर्देश से पता चलता है कि इसमें यूएस-एएससीआईआई वर्ण सेट एन्कोडिंग है। test.txt फ़ाइल के एन्कोडिंग को US-ASCII से TURKISH8 में बदलने के लिए उसी प्रारूप के साथ iconv कमांड का उपयोग किया गया है। आप देखेंगे कि यह यूएस-एएससीआईआई को तुर्की में नहीं बदलता है।
इसके बाद, हमने उसी फ़ाइल के लिए US-ASCII से UTF-32 कैरेक्टर सेट एन्कोडिंग को कवर करने के लिए उसी कमांड का उपयोग किया। इस बार, यह काम करता है। ऐसा इसलिए है क्योंकि कभी-कभी एक एन्कोडिंग सेट को दूसरे में कनवर्ट करने में कोई समस्या हो सकती है, या अन्य एन्कोडिंग इसका समर्थन नहीं कर सकती है।
निष्कर्ष
इस लेख में इस बात पर चर्चा की गई है कि एक एन्कोडिंग वर्ण सेट को उनके उपनामों का उपयोग करके दूसरे में बदलने के लिए iconv Linux निर्देशों का उपयोग कैसे करें। इस तरह हमें अलग-अलग तरह की कुछ फाइलें बनानी पड़ीं।