संग्रह बनाएँ
इंडेक्स का उपयोग करने से पहले, हमें अपने MongoDB में एक नया संग्रह बनाना होगा। हमने पहले ही एक बना लिया है और 'डमी' नाम से 10 दस्तावेज़ डाल दिए हैं। खोज() MongoDB फ़ंक्शन नीचे MongoDB शेल स्क्रीन पर 'डमी' संग्रह से सभी रिकॉर्ड प्रदर्शित करता है।
परीक्षण> db.Dummy.find() 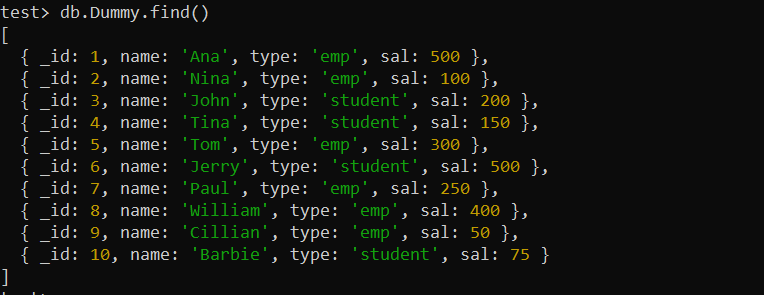
अनुक्रमणिका प्रकार चुनें
इंडेक्स स्थापित करने से पहले, आपको पहले उन कॉलमों को निर्धारित करना होगा जिनका आमतौर पर क्वेरी मानदंड में उपयोग किया जाएगा। इंडेक्स उन कॉलमों पर अच्छा प्रदर्शन करते हैं जिन्हें अक्सर फ़िल्टर किया जाता है, सॉर्ट किया जाता है या खोजा जाता है। बड़ी कार्डिनैलिटी (कई अलग-अलग मान) वाले फ़ील्ड अक्सर उत्कृष्ट अनुक्रमण विकल्प होते हैं। यहां विभिन्न सूचकांक प्रकारों के लिए कुछ कोड उदाहरण दिए गए हैं।
उदाहरण 01: एकल फ़ील्ड सूचकांक
यह संभवतः सूचकांक का सबसे बुनियादी प्रकार है, जो उस कॉलम पर क्वेरी गति को बढ़ाने के लिए एकल कॉलम को अनुक्रमित करता है। इस प्रकार के सूचकांक का उपयोग उन प्रश्नों के लिए किया जाता है जिनमें आप संग्रह रिकॉर्ड को क्वेरी करने के लिए एकल कुंजी फ़ील्ड का उपयोग करते हैं। मान लें कि आप नीचे दिए गए खोज फ़ंक्शन के भीतर संग्रह 'डमी' के रिकॉर्ड को क्वेरी करने के लिए 'प्रकार' फ़ील्ड का उपयोग करते हैं। यह कमांड पूरे संग्रह को देखेगा, जिससे बड़े संग्रहों को संसाधित होने में लंबा समय लग सकता है। इसलिए, हमें इस क्वेरी के प्रदर्शन को अनुकूलित करने की आवश्यकता है।
परीक्षण> db.Dummy.find({प्रकार: 'एम्प' })
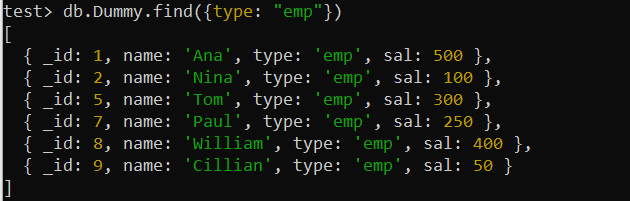
उपरोक्त डमी संग्रह के रिकॉर्ड 'प्रकार' फ़ील्ड का उपयोग करके पाए गए हैं, जिसमें एक शर्त शामिल है। इसलिए, खोज क्वेरी को अनुकूलित करने के लिए एकल-कुंजी सूचकांक का उपयोग यहां किया जा सकता है। इसलिए, हम 'डमी' संग्रह के 'प्रकार' फ़ील्ड पर एक इंडेक्स बनाने के लिए MongoDB के createIndex() फ़ंक्शन का उपयोग करेंगे। इस क्वेरी का उपयोग करने का उदाहरण शेल पर 'type_1' नामक एकल-कुंजी इंडेक्स के सफल निर्माण को प्रदर्शित करता है।
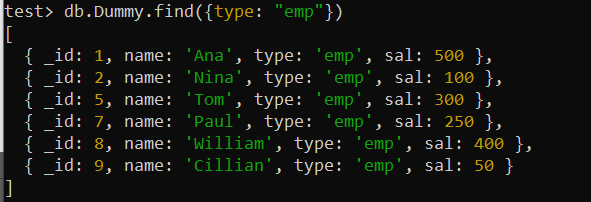
परीक्षण> db.Dummy.createIndex({ प्रकार: 1 })एक बार 'प्रकार' फ़ील्ड का उपयोग करने के बाद खोज() क्वेरी का उपयोग करें। ऑपरेशन अब पहले से उपयोग किए गए खोज() फ़ंक्शन की तुलना में काफी तेज़ होगा क्योंकि इंडेक्स मौजूद है क्योंकि मोंगोडीबी अनुरोधित नौकरी शीर्षक के साथ रिकॉर्ड्स को तेज़ी से पुनर्प्राप्त करने के लिए इंडेक्स का उपयोग कर सकता है।
परीक्षण> db.Dummy.find({प्रकार: 'एम्प' })
उदाहरण 02: यौगिक सूचकांक
हम कुछ परिस्थितियों में विभिन्न मानदंडों के आधार पर वस्तुओं की तलाश करना चाह सकते हैं। इन क्षेत्रों के लिए एक कंपाउंड इंडेक्स लागू करने से क्वेरी प्रदर्शन को बेहतर बनाने में मदद मिल सकती है। मान लीजिए, इस बार, आप क्वेरी प्रदर्शित होने पर अलग-अलग खोज स्थितियों वाले कई फ़ील्ड का उपयोग करके 'डमी' संग्रह से खोजना चाहते हैं। यह क्वेरी उस संग्रह से रिकॉर्ड्स की खोज कर रही है जहां 'प्रकार' फ़ील्ड 'एम्प' पर सेट है और 'सैल' फ़ील्ड 350 से अधिक है।
$gte लॉजिकल ऑपरेटर का उपयोग 'sal' फ़ील्ड में शर्त लागू करने के लिए किया गया है। पूरे संग्रह की खोज के बाद कुल दो रिकॉर्ड लौटाए गए, जिनमें 10 रिकॉर्ड शामिल हैं।
परीक्षण> db.Dummy.find({प्रकार: 'एम्प' , साल: {$gte: 350 } }) 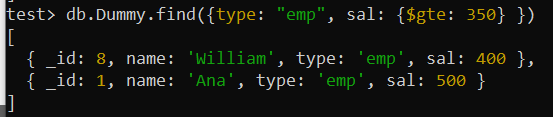
आइए उपरोक्त क्वेरी के लिए एक कंपाउंड इंडेक्स बनाएं। इस यौगिक सूचकांक में 'प्रकार' और 'साल' फ़ील्ड हैं। संख्याएँ '1' और '-1' 'प्रकार' और 'साल' फ़ील्ड के लिए क्रमशः आरोही और अवरोही क्रम का प्रतिनिधित्व करती हैं। कंपाउंड इंडेक्स के कॉलम का क्रम महत्वपूर्ण है और इसे क्वेरी पैटर्न के अनुरूप होना चाहिए। जैसा कि प्रदर्शित किया गया है, MongoDB ने इस यौगिक सूचकांक को 'type_1_sal_-1' नाम दिया है।
परीक्षण> db.Dummy.createIndex({ प्रकार: 1 , इच्छा:- 1 }) 
'प्रकार' फ़ील्ड मान 'एएमपी' और 'सैल' फ़ील्ड का मान 350 से अधिक के साथ रिकॉर्ड खोजने के लिए उसी खोज () क्वेरी का उपयोग करने के बाद, हमने क्रम में थोड़े से बदलाव के साथ समान आउटपुट प्राप्त किया है पिछले क्वेरी परिणाम की तुलना में। 'सैल' फ़ील्ड के लिए बड़ा मान रिकॉर्ड अब पहले स्थान पर है, जबकि सबसे छोटा उपरोक्त यौगिक सूचकांक में 'सैल' फ़ील्ड के लिए निर्धारित '-1' के अनुसार सबसे निचले स्थान पर है।
परीक्षण> db.Dummy.find({प्रकार: 'एम्प' , साल: {$gte: 350 } }) 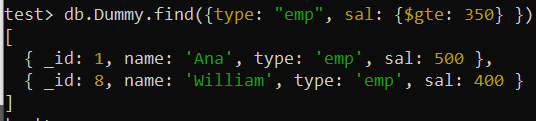
उदाहरण 03: पाठ अनुक्रमणिका
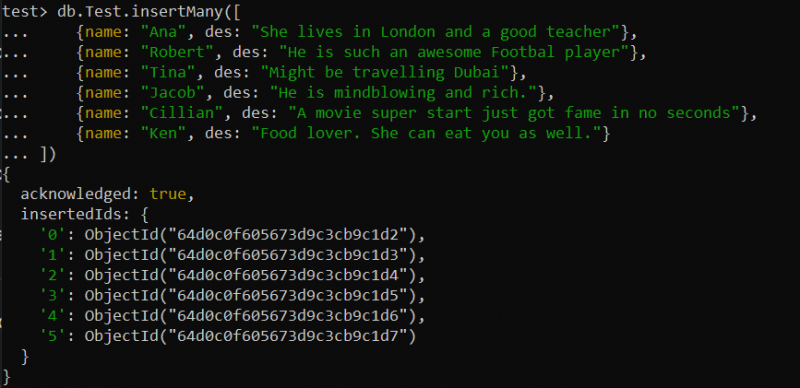
कभी-कभी, आपको ऐसी स्थिति का सामना करना पड़ सकता है जिसमें आपको बड़े डेटा सेट से निपटना चाहिए, जैसे उत्पादों, सामग्रियों आदि के बड़े विवरण। एक टेक्स्ट इंडेक्स एक बड़े टेक्स्ट फ़ील्ड पर पूर्ण-टेक्स्ट खोज करने के लिए उपयोगी हो सकता है। उदाहरण के लिए, हमने अपने परीक्षण डेटाबेस में 'टेस्ट' नामक एक नया संग्रह बनाया है। नीचे दी गई खोज() क्वेरी के अनुसार इन्सर्टमैनी() फ़ंक्शन का उपयोग करके इस संग्रह में कुल 6 रिकॉर्ड डाले गए।
परीक्षण> db.Test.insertMany([{नाम: 'एना' , की: 'वह लंदन में रहती है और एक अच्छी शिक्षिका है' },
{नाम: 'रॉबर्ट' , की: 'वह बहुत शानदार फुटबॉल खिलाड़ी है' },
{नाम: 'से' , की: 'हो सकता है दुबई की यात्रा कर रहा होऊं' },
{नाम: 'जैकब' , की: 'वह दिमागदार और अमीर है।' },
{नाम: 'सिलियन' , की: 'एक फिल्म की सुपर शुरुआत ने कुछ ही सेकंड में प्रसिद्धि पा ली' },
{नाम: 'केन' , की: 'खाने की शौकीन। वह तुम्हें भी खा सकती है।' }
])
अब, हम MongoDB के createIndex() फ़ंक्शन का उपयोग करते हुए, इस संग्रह के 'डेस' फ़ील्ड पर एक टेक्स्ट इंडेक्स बनाएंगे। फ़ील्ड मान में कीवर्ड 'टेक्स्ट' एक इंडेक्स का प्रकार प्रदर्शित करता है, जो एक 'टेक्स्ट' इंडेक्स है। सूचकांक नाम, des_text, स्वचालित रूप से जेनरेट किया गया है।
परीक्षण> db.Test.createIndex({ des: 'मूलपाठ' })अब, 'des_text' इंडेक्स के माध्यम से संग्रह पर 'टेक्स्ट-सर्च' करने के लिए फाइंड() फ़ंक्शन का उपयोग किया गया है। $search ऑपरेटर का उपयोग संग्रह रिकॉर्ड में 'भोजन' शब्द की खोज करने और उस विशेष रिकॉर्ड को प्रदर्शित करने के लिए किया गया था।
परीक्षण> db.Test.find({ $पाठ: { $खोज: 'खाना' }}); 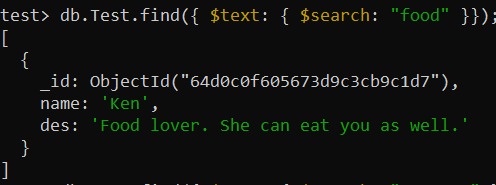
अनुक्रमणिका सत्यापित करें:
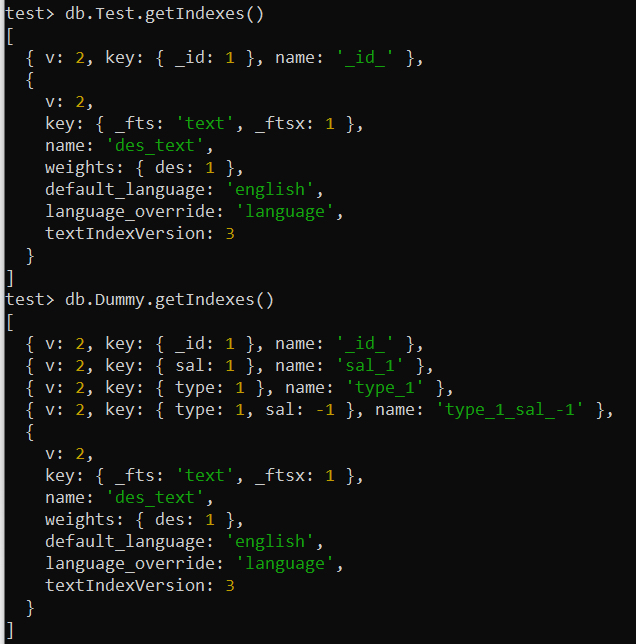
आप अपने MongoDB में विभिन्न संग्रहों के सभी लागू इंडेक्स की जांच और सूची बना सकते हैं। इसके लिए, अपने MongoDB शेल स्क्रीन में संग्रह के नाम के साथ getIndexes() विधि का उपयोग करें। हमने इस कमांड का उपयोग 'टेस्ट' और 'डमी' संग्रह के लिए अलग से किया है। यह आपकी स्क्रीन पर अंतर्निहित और उपयोगकर्ता-परिभाषित इंडेक्स के संबंध में सभी आवश्यक जानकारी दिखाता है।
परीक्षण> db.Test.getIndexes()परीक्षण> db.Dummy.getIndexes()
ड्रॉप इंडेक्स:
यह उन इंडेक्स को हटाने का समय है जो पहले ड्रॉपइंडेक्स() फ़ंक्शन का उपयोग करके संग्रह के लिए बनाए गए थे, साथ ही उसी फ़ील्ड नाम के साथ जिस पर इंडेक्स लागू किया गया था। नीचे दी गई क्वेरी से पता चलता है कि एकल सूचकांक हटा दिया गया है।
परीक्षण> db.Dummy.dropIndex({प्रकार: 1 }) 
इसी तरह, कंपाउंड इंडेक्स को गिराया जा सकता है।
परीक्षण> db.Dummy.drop सूचकांक ({प्रकार: 1 , इच्छा: 1 }) 
निष्कर्ष
MongoDB से डेटा की पुनर्प्राप्ति को तेज़ करके, प्रश्नों की दक्षता बढ़ाने के लिए अनुक्रमण आवश्यक है। इंडेक्स की कमी के कारण, MongoDB को मिलान रिकॉर्ड के लिए पूरे संग्रह की खोज करनी होगी, जो सेट का आकार बढ़ने के साथ कम प्रभावी हो जाता है। इंडेक्स डेटाबेस संरचना का उपयोग करके सही रिकॉर्ड को तेजी से खोजने की MongoDB की क्षमता उपयुक्त इंडेक्सिंग का उपयोग करने पर प्रश्नों के प्रसंस्करण को गति देती है।