पांडा सेट_ऑप्शन विधि
आज, हम देखेंगे कि 'pd.set_option ()' फ़ंक्शन को आपके स्पाइडर टूल में प्रस्तुत करते समय पंडों डेटाफ़्रेम में सभी कॉलम प्रदर्शित करने के लिए कैसे उपयोग किया जाए। 'Pd.set_option ()' का उपयोग करने के लिए, हम दिए गए सिंटैक्स का पालन करते हैं:

आइए पायथन कार्यक्रम के व्यावहारिक कार्यान्वयन की सहायता से अवधारणा सीखना शुरू करें।
उदाहरण: सभी स्तंभों को प्रदर्शित करने के लिए पंडों की सेट_ऑप्शन विधि का उपयोग करना
यह प्रदर्शन पंडों 'set_option ()' का उपयोग करके डेटाफ्रेम में सभी कॉलम प्रदर्शित करने के लिए एक गाइड है। हम इस पायथन पद्धति के कार्यान्वयन के लिए हर कदम का विवरण स्पष्ट करेंगे।
पायथन लिपि के व्यावहारिक कार्यान्वयन के लिए पहली आवश्यकता यह है कि आप अपने कार्यक्रम को निष्पादित करने के लिए सबसे अच्छे उपकरण का पता लगाएं। हमारे चित्रण के लिए हमने जिस टूल का उपयोग किया है वह 'स्पाइडर' टूल है। हमने टूल लॉन्च किया और पायथन लिपि पर काम करना शुरू किया।
कोड के साथ शुरू करते हुए, हमें शुरू में उन पूर्वापेक्षित पुस्तकालयों को आयात करने की आवश्यकता है जिनकी हमें इस कार्यक्रम में आवश्यकता है। पहली लाइब्रेरी जिसे हमने अपनी पायथन फाइल में लोड किया है, वह पंडों की लाइब्रेरी है क्योंकि हम यहां जिन कार्यों का उपयोग करते हैं, वे पंडों द्वारा प्रदान किए जाते हैं। हमने इस पुस्तकालय को 'पीडी' के रूप में उपनाम दिया है। दूसरी लाइब्रेरी जिसे हमने लोड किया है वह है NumPy लाइब्रेरी। NumPy (न्यूमेरिकल पायथन) एक संख्यात्मक कंप्यूटिंग पैकेज है जिसे पायथन प्रोग्रामिंग पर विकसित किया गया है। कोड का आयात NumPy अनुभाग पायथन को आपकी वर्तमान पायथन फ़ाइल में NumPy मॉड्यूल को एकीकृत करने का निर्देश देता है। स्क्रिप्ट का 'एज़ एनपी' भाग तब पायथन को 'एनपी' संक्षिप्त नाम NumPy को असाइन करने का निर्देश देता है। यह आपको NumPy के बजाय 'np.function_name' दर्ज करके NumPy विधियों का उपयोग करने में सक्षम बनाता है।
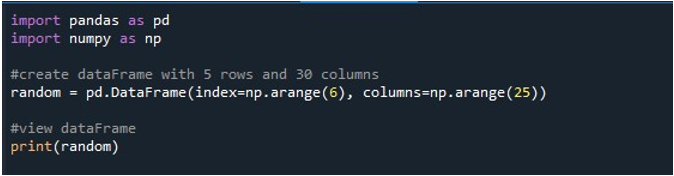
अब, हम मुख्य कोड से शुरू करते हैं। हमारे कार्यक्रम के लिए सबसे महत्वपूर्ण और मूलभूत आवश्यकता पंडों का डेटाफ़्रेम है। इसलिए, हम इसमें शामिल सभी कॉलम प्रदर्शित करते हैं। अब, यह पूरी तरह आप पर निर्भर है कि आप निर्दिष्ट मानों के साथ डेटाफ़्रेम बनाना चाहते हैं या यदि आपको CSV फ़ाइल आयात करने की आवश्यकता है। इस उदाहरण के लिए हमने जो चुना वह NaN मानों के साथ एक DataFrame बना रहा है। हमने डेटाफ़्रेम बनाने के लिए 'pd.DataFrame ()' विधि का उपयोग किया। यहां, हमने दो पैरामीटर प्रदान किए हैं - 'इंडेक्स' और 'कॉलम'। 'इंडेक्स' तर्क पंक्तियों को संदर्भित करता है जिसका अर्थ है कि हम डेटाफ़्रेम के लिए पंक्तियों को सेट करते हैं।
हमने 'इंडेक्स' पैरामीटर और NumPy फ़ंक्शन 'np.arange() को '6' के मान गणना के साथ असाइन किया है। यह DataFrame के लिए छह पंक्तियाँ उत्पन्न करता है। यह सभी प्रविष्टियों को NaN मानों से भरता है क्योंकि हमने इसे कोई मान प्रदान नहीं किया है। 'कॉलम' तर्क, जैसा कि नाम निर्दिष्ट करता है, डेटाफ़्रेम के लिए कॉलम सेट करने के लिए उपयोग किया जाता है। इसे कॉलम के लिए '25' मान गणना के साथ 'np.arange ()' फ़ंक्शन भी सौंपा गया है। इस प्रकार, यह DataFrame के लिए 25 कॉलम बनाता है।
नतीजतन, जब हम 'pd.DataFrame ()' फ़ंक्शन को कॉल करते हैं, तो हमारे पास 25 कॉलम और शून्य मानों से भरी 6 पंक्तियों वाला डेटाफ़्रेम होता है। इस डेटाफ़्रेम को संरक्षित करने की आवश्यकता के लिए, हमें एक डेटाफ़्रेम ऑब्जेक्ट बनाने की आवश्यकता है जो इसकी सामग्री को संग्रहीत करता है। इसलिए, हमने एक DataFrame ऑब्जेक्ट 'रैंडम' बनाया और इसे 'pd.DataFrame ()' विधि से प्राप्त होने वाले परिणाम को असाइन किया। अब, आप निश्चित रूप से DataFrame को जनरेट होते देखना चाहते हैं। पायथन हमें स्क्रीन पर आउटपुट देखने की एक विधि प्रदान करता है जो 'प्रिंट ()' फ़ंक्शन है। हमने डेटाफ़्रेम ऑब्जेक्ट 'यादृच्छिक' को इसके पैरामीटर के रूप में पास करके इस पद्धति को लागू किया।
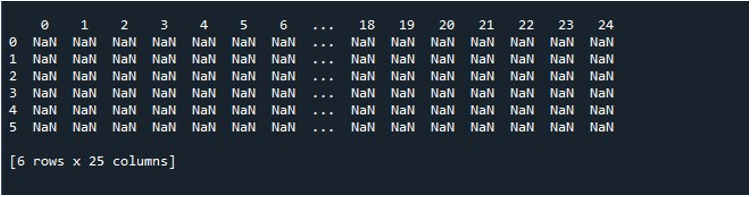
जब हम इस कोड स्निपेट को निष्पादित करते हैं, तो हमें टर्मिनल पर प्रदर्शित NaN मानों के साथ हमारा DataFrame मिलता है। यहां, हम देख सकते हैं कि पहले कॉलम में से कुछ और अंत से केवल कुछ ही दिखाई दे रहे हैं। बीच के सभी कॉलम काट दिए गए हैं। डिफ़ॉल्ट रूप से, यह विशाल डेटासेट प्रदर्शित करके उपयोगकर्ता के लिए निराशा पैदा करने से बचने के लिए कुछ पंक्तियों और स्तंभों को छुपाता है।
आप पंडों के 'लेन ()' फ़ंक्शन का उपयोग करके डेटाफ़्रेम में कुल स्तंभों की संख्या भी देख सकते हैं। अपने 'स्पाइडर' टूल के कंसोल पर 'लेन ()' फ़ंक्शन लिखें। '.columns' गुण के साथ उसके कोष्ठकों के बीच DataFrame का नाम लिखें। यह हमें आपके DataFrame में कॉलम की कुल लंबाई देता है।

यह हमारे DataFrame की लंबाई लौटाता है जो कि 25 है।
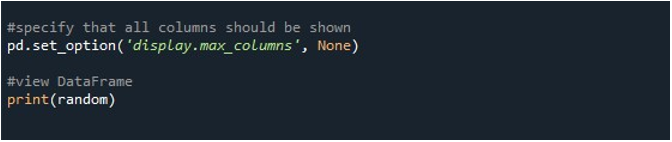
अब, अगला और मुख्य कार्य आउटपुट प्रदर्शित करने के लिए डिफ़ॉल्ट विकल्प को बदलना है। ऐसी परिस्थितियाँ हो सकती हैं जहाँ आप संपूर्ण डेटाफ़्रेम को टर्मिनल पर देखना चाहते हैं। डिफ़ॉल्ट मानों के कारण, कई प्रविष्टियाँ काट दी जाती हैं जो उपयोगकर्ता के लिए निराशा का कारण बनती हैं। आप यहां सीखेंगे कि इस मुद्दे को कैसे दूर किया जाए। डिफ़ॉल्ट प्रदर्शन सेटिंग्स को बदलने के लिए पांडा हमें 'pd.set_option ()' फ़ंक्शन प्रदान करता है। कंसोल पर डेटाफ़्रेम प्रदर्शित करने के ठीक बाद, हम 'pd.set_option ()' विधि को लागू करते हैं। हम इस फ़ंक्शन के कोष्ठक के बीच पैरामीटर निर्दिष्ट करते हैं जिसे हमें DataFrame के सभी कॉलम प्रदर्शित करने के लिए उपयोग करने की आवश्यकता होती है।
यहां, हमने अपने डेटाफ़्रेम में अधिकतम कॉलम प्रदर्शित करने के लिए 'display.max_columns' का उपयोग किया है। हम इस पैरामीटर के लिए मान भी परिभाषित कर सकते हैं, यानी अधिकतम कॉलम जो आप प्रदर्शित करना चाहते हैं। दूसरी ओर, हम 'display.max_columns' को 'कोई नहीं' पर सेट करते हैं, जो डेटाफ़्रेम के सभी स्तंभों को अधिकतम लंबाई के साथ प्रदर्शित करता है। अंत में, हमने टर्मिनल पर दिखाई देने वाले सभी कॉलम के साथ परिणामी डेटाफ़्रेम को प्रदर्शित करने के लिए 'प्रिंट ()' फ़ंक्शन को नियोजित किया।
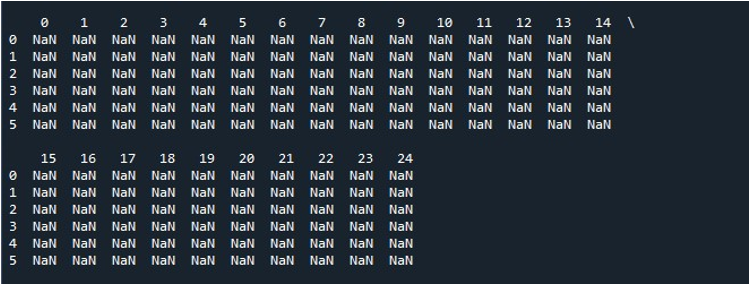
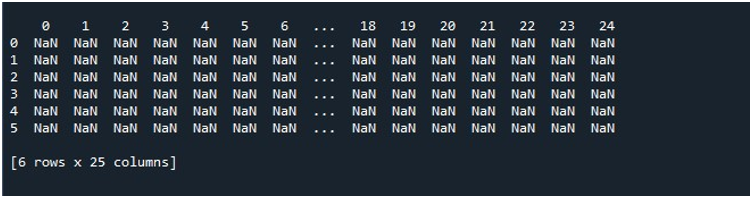
जब हम 'स्पाइडर' टूल पर 'रन फाइल' विकल्प को हिट करते हैं, तो हम प्रदर्शित होने वाले डेटाफ्रेम को देख सकते हैं। इस डेटाफ़्रेम में छह पंक्तियाँ हैं और इसमें रखे गए स्तंभों की संख्या 25 है। ऐसे कोई स्तंभ नहीं हैं जिन्हें छोटा किया गया हो क्योंकि 'pd.set_option ()' अधिकतम स्तंभ लंबाई वाले फ़ंक्शन को अभी सक्षम किया गया है।
हम डिस्प्ले विकल्प को रीसेट भी कर सकते हैं क्योंकि एक बार जब हम डिस्प्ले की लंबाई को अधिकतम पर सेट कर देते हैं, तो यह डेटाफ्रेम को उस विशेष पायथन फ़ाइल के सभी कॉलमों के साथ प्रदर्शित करना जारी रखता है। इसके लिए हम पंडों 'pd.reset_option ()' का उपयोग करते हैं। हम इस फ़ंक्शन को लागू करते हैं और इस फ़ंक्शन के पैरामीटर के रूप में 'display.max_columns' प्रदान करते हैं।

यह हमें प्रदान किए गए डेटाफ़्रेम के लिए प्रारंभिक प्रदर्शन सेटिंग्स प्राप्त करता है।
निष्कर्ष
टर्मिनल पर एक विशाल डेटासेट के साथ पूरा आउटपुट देखने के लिए कभी-कभी हमें परेशानी होती है जब टूल की डिफ़ॉल्ट सेटिंग्स उपयोगकर्ता की जरूरतों के विपरीत आती हैं। इस झटके को हल करने के लिए, पंडों ने हमें 'pd.set_option ()' विधि दी। इस लर्निंग गाइड में, हमने आपको इस पद्धति और इसे नियोजित करने की आवश्यकता से परिचित कराया। हमने व्यावहारिक रूप से संकलित और निष्पादित पायथन नमूना कोड के साथ विषय का प्रदर्शन किया। हमने 'स्पाइडर' पर किए गए चित्रण के परिणामों का प्रतिपादन किया। हमने समझाया कि डिफ़ॉल्ट सेटिंग्स को बदलने के साथ-साथ सभी सेटिंग्स को प्रारंभिक पर रीसेट करके कंसोल पर डेटाफ़्रेम के सभी कॉलम कैसे प्रदर्शित करें। मॉड्यूल के व्यावहारिक कार्यान्वयन पर पूरी तरह से ध्यान केंद्रित करने से आप जब भी ऐसी परेशानी का सामना करते हैं तो इसका उपयोग करने में सक्षम होते हैं।