पांडा इतने बार-बार अनुप्रयोग होते हैं कि उन चीजों की गणना करना अधिक उपयोगी हो सकता है जिन्हें वे पूरा नहीं कर सकते हैं, न कि वे जो कर सकते हैं। आपका डेटा व्यावहारिक रूप से इस उपकरण में रहता है। पंडों की मदद से आप डेटा को साफ करके, उसे रूपांतरित करके और उसका विश्लेषण करके उसके बारे में जान सकते हैं। 'लैम्ब्डा' सामान्य भाषा में किसी फ़ंक्शन को परिभाषित करने का एक वैकल्पिक तरीका है। 'लैम्ब्डा' का उपयोग करके, आप सीधे एक फ़ंक्शन को परिभाषित कर सकते हैं। इसका तात्पर्य है कि आप कुछ डेटा पर फ़ंक्शन लागू करने के लिए पायथन कोड के एक वाक्य का उपयोग कर सकते हैं। जबकि एक अभिव्यक्ति एक से अधिक पैरामीटर ले सकती है, एक 'लैम्ब्डा' फ़ंक्शन एक तक सीमित है। अभिव्यक्ति का मूल्यांकन किया जाता है और एक परिणाम दिया जाता है। पायथन के पांडा विभिन्न प्रकार के डेटा अनुसंधान मुद्दों को संबोधित करने के लिए 'लैम्ब्डा' फ़ंक्शन का उपयोग करते हैं। पांडा डेटाफ़्रेम में, हम पंक्तियों और स्तंभों दोनों के लिए 'लैम्ब्डा' फ़ंक्शन का उपयोग कर सकते हैं।
'लैम्ब्डा' एक उच्च स्केलेबल प्रौद्योगिकी कंपनी पर आपके कार्यक्रम को निष्पादित करता है और सभी कंप्यूटर परिसंपत्ति प्रशासन का प्रबंधन करता है। इसमें अद्यतन परिनियोजन, क्षमता प्रावधान, स्वचालित स्केलिंग, कोड विश्लेषण और रिकॉर्डिंग, और सर्वर और ऑपरेटिंग रखरखाव शामिल हैं। केवल एक जोड़ के साथ एक छोटी क्षमता पंडों का 'लैम्ब्डा' फ़ंक्शन है। 'लैम्ब्डा' क्षमताएं उन स्थितियों में समान रूप से कार्य कर सकती हैं जहां उनका नाम नहीं है। 'लैम्ब्डा' फ़ंक्शन के कीवर्ड के लिए है। फ़ंक्शन का मुख्य भाग जिसे कार्यान्वित करने की आवश्यकता है, दूसरे x द्वारा इंगित किया गया है। कीवर्ड 'लैम्ब्डा' होना चाहिए और आवश्यक है, लेकिन तर्क और शरीर परिस्थितियों के अनुसार भिन्न हो सकते हैं। लैम्ब्डा फ़ंक्शन के साथ रिटर्निंग फ़ंक्शन ऑब्जेक्ट संभव है।
लैम्ब्डा फ़ंक्शन के लिए सिंटैक्स:

उदाहरण 1: असाइन () विधि को लागू करके एक नए कॉलम में लैम्ब्डा विधि को निष्पादित करने के लिए डेटाफ़्रेम का उपयोग करना
विविध सूचना प्रसंस्करण मुद्दों से निपटने के लिए पंडों द्वारा 'लैम्ब्डा' दृष्टिकोण का उपयोग किया जाता है। एक संक्षिप्त कार्य, 'लैम्ब्डा' विधि का उपयोग गुमनाम रूप से भी किया जा सकता है, जिसका अर्थ है कि इसे किसी नाम की आवश्यकता नहीं है। 'लैम्ब्डा' विधि का उपयोग न्यूनतम कार्यक्रम लिखने और सरल मुद्दों को हल करने के लिए किया जा सकता है। उच्च-क्रम के कार्यों का समर्थन करने वाली भाषाओं में, 'लैम्ब्डा' अभिव्यक्ति या 'लैम्ब्डा' तकनीक केवल निर्देशों का हिस्सा है जिसे चर के लिए आवंटित किया जा सकता है, एक तर्क के रूप में पारित किया जा सकता है, या फ़ंक्शन कॉल से पुनर्प्राप्त किया जा सकता है। वे लंबे समय से प्रोग्रामिंग का एक घटक रहे हैं। इस लेख के पहले उदाहरण से शुरू करते हुए, कोड के निष्पादन के लिए मूल शर्त आवश्यक पुस्तकालयों को लोड करना है। 'पंडों' पुस्तकालय वह है जिसकी हमें आवश्यकता है। इसे लोड करने के लिए, हमें 'pd के रूप में आयात पांडा' लाइन बनानी होगी। अब हम अपने डेटा फ्रेम का निर्माण करेंगे।
इस उदाहरण में, हमारे डेटा फ़्रेम को 'छात्र' कहा जाता है। हमारे डेटा फ्रेम को तब दो अतिरिक्त कॉलम मिलते हैं। पहले कॉलम का नाम 'नाम' और दूसरे का नाम 'मार्क्स' है। दो स्तंभों में से प्रत्येक में कुछ मान होते हैं। हमारे पास पहले कॉलम 'एल्विन', 'वाटसन', 'थॉमस' और 'नूह' के लिए निम्नलिखित मान हैं और दूसरे कॉलम 'मार्क्स' के मान हैं। हमारे पास '400', '360', '430' और '290' हैं। अब, यह 'pd.DataFrame' का उपयोग करके हमारे डेटाफ़्रेम को उत्पन्न करेगा।
फिर हम अपने कोड के बड़े हिस्से तक पहुँचते हैं, जहाँ हम एक नया सिंगल कॉलम बनाने के लिए 'लैम्ब्डा' के साथ 'असाइन ()' विधि का उपयोग करते हैं। 'लैम्ब्डा' फ़ंक्शन 'डेटाफ्रेम.असाइन ()' विधि के माध्यम से केवल एक कॉलम पर लागू होता है। लैम्ब्डा सामान्य भाषा में कार्यों का वर्णन करने का एक अतिरिक्त तरीका है। लैम्ब्डा का उपयोग करके, आप सीधे एक फ़ंक्शन को परिभाषित कर सकते हैं। इसका तात्पर्य है कि आप कुछ डेटा पर फ़ंक्शन लागू करने के लिए पायथन कोड की एक पंक्ति का उपयोग कर सकते हैं। अब हम 'असाइन ()' विधि का उपयोग करके अपने डेटाफ्रेम में एक नया कॉलम 'प्रतिशत' असाइन करते हैं।
कॉलम 'मार्क' पर 'लैम्ब्डा' प्रक्रिया का उपयोग किया गया था। छात्रों के प्रतिशत की गणना लैम्ब्डा फ़ंक्शन का उपयोग करके की जाती है और फिर उन्हें एक नए कॉलम में रखा जाता है, जो 'प्रतिशत' है। 'लैम्ब्डा' का उपयोग करके प्रतिशत निर्धारित करने के लिए हम जिस सूत्र का उपयोग करते हैं, वह है 'अंक या कुल अंक, जो कि 500 है और 100 से गुणा किया जाता है,' जो छात्र के सटीक प्रतिशत का उत्पादन करेगा और इसे डेटाफ्रेम के 'प्रतिशत' कॉलम में प्रदर्शित करेगा। 'प्रिंट (डेटाफ़्रेम)' अब स्क्रीन पर डेटाफ़्रेम प्रदर्शित करेगा।
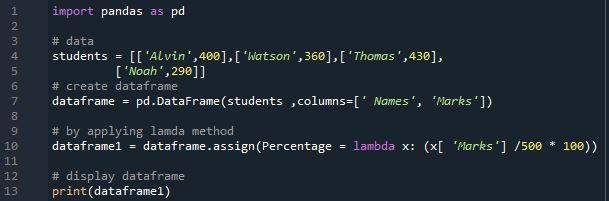
हम इस कोड का परिणाम देख सकते हैं। इस छवि में तीन स्तंभों वाला डेटाफ़्रेम दिखाई देता है। पहले कॉलम में छात्र का नाम होता है, और दूसरे कॉलम में छात्र के ग्रेड होते हैं। तीसरे कॉलम के 'प्रतिशत' के निर्माण के लिए 'असाइन ()' विधि और 'लैम्ब्डा' फ़ंक्शन का उपयोग करके हम छात्र के प्रतिशत का निर्धारण कर सकते हैं और फिर उन प्रतिशत को तीसरे कॉलम में जोड़ सकते हैं, जिसे डेटा फ्रेम में 'प्रतिशत' नाम दिया गया है। . सूत्र का उपयोग करके प्रतिशत कॉलम के लिए प्राप्त किए गए मान '80', '72', '86' और '58' थे। इस डेटाफ़्रेम में अनुक्रमणिका का आकार '4' है।
उदाहरण 2: एकाधिक कॉलम में असाइन () विधि का उपयोग करने के लिए लैम्ब्डा फ़ंक्शन को कार्यान्वित करना
पांडा डेटाफ़्रेम की असाइन () तकनीक हमें कई स्तंभों पर लैम्ब्डा फ़ंक्शन का उपयोग करने की अनुमति देती है। हर बार एक नए फ़ंक्शन की आवश्यकता होती है, जैसे लैम्ब्डा फ़ंक्शन या सॉर्ट फ़ंक्शन, हम इसे जोड़ने के लिए स्वतंत्र हैं। पंडों के डेटा फ्रेम के कॉलम और पंक्तियों को लैम्ब्डा फ़ंक्शन के साथ माना जा सकता है। इस परिदृश्य में, हम एक डेटाफ़्रेम जनरेट करके शुरू करते हैं। 'छात्र परिणाम' डेटाफ़्रेम का नाम है। इस डेटाफ्रेम में हमारे पास चार कॉलम हैं। हमारे पास पहला कॉलम 'नाम' है। दूसरा कॉलम 'पायथन' है। तीसरे कॉलम का नाम 'Data_struct' है। चौथे का नाम 'कैलकुलस' है।
इन स्तंभों में, हमने कुछ मान सूचीबद्ध किए हैं। कॉलम 'नाम' के लिए, हमारे पास कुछ छात्रों के नाम 'विलो', 'एलिस', 'एडवर्ड' और 'एमेलिया' की सूची है। अजगर '96', '40', '98' और '98' के चिह्नों को दूसरे कॉलम में रखे गए मानों द्वारा दर्शाया गया है। तीसरे कॉलम में मान '86', '56', '73' और '90' हैं और चौथे कॉलम के लिए हमारे पास '90', '33', '88' और '78' हैं। अब डेटाफ़्रेम उत्पन्न करने के लिए 'pd.DataFrame' का उपयोग करें।
अब, हम 'असाइन' विधि का उपयोग करके अपने डेटा फ्रेम में एक नया कॉलम जोड़ते हैं। नए कॉलम का शीर्षक 'कुल अंक' है। नए कॉलम का नाम “Total_marks” है। समग्र अंक प्राप्त करने के लिए, हमने कई विषय स्तंभों पर 'लैम्ब्डा' फ़ंक्शन का उपयोग किया, जिसमें पायथन, डेटा संरचना और कैलकुलस शामिल हैं। यह फ़ंक्शन तीनों विषयों के अंकों को जोड़ देगा और उन्हें 'Total_marks' कॉलम में प्रदर्शित करेगा। 'प्रिंट (डेटाफ़्रेम)' अंत में स्क्रीन पर डेटाफ़्रेम प्रदर्शित करेगा।
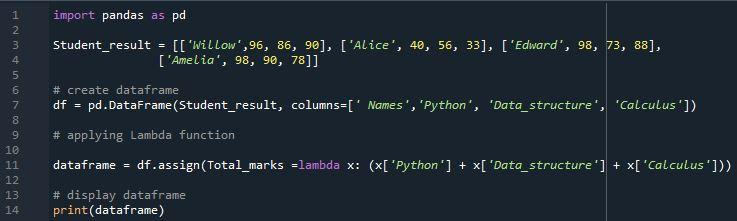
इस बार हमें यह परिणाम मिला है। कई स्तंभों में उपयोग किए जाने पर 'लैम्ब्डा' फ़ंक्शन एक उत्कृष्ट परिणाम प्रदान करेगा। हम 'असाइन करें' पद्धति का उपयोग करके अपने डेटाफ़्रेम में एक नया कॉलम 'Total_marks' असाइन करते हैं ताकि हम उस कॉलम में छात्र का कुल परिणाम प्रदर्शित कर सकें। अंत में, हम देख सकते हैं कि 'कुल अंक' कॉलम तीनों विषयों के कुल परिणाम प्रदर्शित करता है। कुल अंकों के कॉलम की संख्या की गणना लैम्ब्डा “272”, “129”, “259” और “266” का उपयोग करके तीन कॉलम से मान जोड़कर की गई थी।
निष्कर्ष
पायथन प्रोग्रामिंग भाषा में, एक लैम्ब्डा फ़ंक्शन एक अनाम, एक-पंक्ति फ़ंक्शन है जो एक तर्क और अनंत संख्या में पैरामीटर लेता है। वे कई तर्क दे सकते हैं, लेकिन उनमें से केवल एक ही व्यक्त किया जाएगा। लैम्ब्डा कार्य एक क्षमता वस्तु को पुनर्स्थापित करता है जिसे किसी भी कारक को सौंपा जा सकता है और इसमें कोई दावा नहीं किया जा सकता है। पहले मामले में, 'लैम्ब्डा' का उपयोग प्रतिशत निर्धारित करने के लिए किया गया था, और दूसरे उदाहरण में, छात्रों के लिए 'कुल अंक' की गणना की गई थी। इस आलेख में विशिष्ट 'लैम्ब्डा' कार्यों के वाक्यविन्यास, उपयोग और उदाहरण शामिल हैं।