पंडों आज डेटा वैज्ञानिकों द्वारा सारणीबद्ध डेटा का विश्लेषण करने के लिए उपयोग किए जाने वाले सबसे लोकप्रिय उपकरणों में से हैं। सारणीबद्ध सामग्री से निपटने के लिए, यह एक तेज और अधिक प्रभावी एपीआई प्रदान करता है। जब भी हम विश्लेषण के दौरान डेटा फ़्रेम देखते हैं, तो पांडा स्वचालित रूप से विभिन्न प्रदर्शन व्यवहारों को डिफ़ॉल्ट मानों पर सेट कर देता है। इन प्रदर्शन व्यवहारों में प्रदर्शित करने के लिए कितनी पंक्तियाँ और स्तंभ, प्रत्येक डेटा फ़्रेम में फ़्लोट की सटीकता, स्तंभ आकार आदि शामिल हैं। आवश्यकताओं के आधार पर, हमें कभी-कभी इन डिफ़ॉल्ट को संशोधित करने की आवश्यकता हो सकती है। डिफ़ॉल्ट व्यवहार को बदलने के लिए पंडों के पास कई तरह के दृष्टिकोण हैं। पंडों की 'विकल्प' विशेषता का लाभ उठाने से हमें इस व्यवहार को बदलने में मदद मिली।
पांडा अधिकतम पंक्तियाँ प्रदर्शित करते हैं
जब भी आप एक विशाल डेटा फ़्रेम को प्रिंट करने का प्रयास करते हैं जिसमें पूर्वनिर्धारित थ्रेशोल्ड से अधिक पंक्तियाँ और कॉलम होते हैं, तो आउटपुट को ट्रिम कर दिया जाएगा। डेटाफ़्रेम में सभी पंक्तियों को दिखाने के लिए, आप इस ट्यूटोरियल में पंडों के प्रदर्शन विकल्पों को संशोधित करना सीखेंगे। डिफ़ॉल्ट रूप से पांडा अपने द्वारा प्रदर्शित स्तंभों और पंक्तियों की संख्या पर एक सीमा लगाते हैं। हालांकि यह सामग्री पढ़ने के लिए उपयोगी हो सकता है, लेकिन यदि आपको जो जानकारी देखने की आवश्यकता है वह दिखाई नहीं देती है तो यह अक्सर निराशा का कारण बनता है। यहां, हम डेटाफ़्रेम के सभी स्तंभों को प्रदर्शित करने के लिए उनके सिंटैक्स के साथ नीचे दी गई विधियों का उपयोग करेंगे।
तार()

सेट_विकल्प ()

विकल्प_संदर्भ ()

हम प्रदान किए गए डेटाफ़्रेम में अधिकतम पंक्तियों को प्रदर्शित करने के लिए व्यावहारिक कार्यान्वयन के साथ इन सभी विधियों के उपयोग के बारे में जानेंगे।
उदाहरण # 1: पंडों का उपयोग to_string() विधि
यह प्रदर्शन हमें पांडा 'to_string ()' विधि का उपयोग करके टर्मिनल पर डेटाफ्रेम में अधिकतम पंक्तियों को प्रदर्शित करना सिखाएगा।
नमूना कार्यक्रमों के संकलन और निष्पादन के लिए, हमने 'स्पाइडर' टूल को चुना है। इस गाइड में, हम अपने सभी उदाहरणों के निष्पादन के लिए इस टूल का उपयोग करेंगे। हमने पायथन लिपि लिखना शुरू करने के लिए 'स्पाइडर' टूल लॉन्च किया है। कोड के साथ शुरुआत करते हुए, हमें सबसे पहले आवश्यक पुस्तकालयों को अपनी पायथन फ़ाइल में लोड करना होगा ताकि हमें इसकी सुविधाओं का उपयोग करने की अनुमति मिल सके। हमें यहां जिस मॉड्यूल लाइब्रेरी की आवश्यकता है वह है 'पंडों'। इसलिए, हमने इसे अपनी पायथन फ़ाइल में आयात किया और इसे 'पीडी' में बदल दिया।
चूंकि इस आलेख का मुख्य संचालन डेटाफ़्रेम की अधिकतम पंक्तियों को प्रदर्शित करना है, इसलिए हमें पहले डेटाफ़्रेम की आवश्यकता होती है। अब यह आप पर निर्भर है कि आप डेटाफ़्रेम जनरेट करना पसंद करते हैं या CSV फ़ाइल आयात करना चाहते हैं। हमने एक नमूना CSV फ़ाइल आयात की है। पायथन प्रोग्राम में CSV फ़ाइल पढ़ने के लिए, हमने पांडा 'pd.read_csv ()' फ़ंक्शन का उपयोग किया है। इस फ़ंक्शन के कोष्ठकों के बीच, हमने सीएसवी फ़ाइल प्रदान की है जिसे हम डिस्प्ले को पढ़ना चाहते हैं, जो कि 'इंडस्ट्री.सीएसवी' है। हमने प्रदान की गई CSV फ़ाइल को पढ़ने से उत्पन्न आउटपुट को संग्रहीत करने के लिए एक चर 'df' का निर्माण किया है। फिर, हमने डेटाफ़्रेम प्रदर्शित करने के लिए 'प्रिंट ()' विधि लागू की।
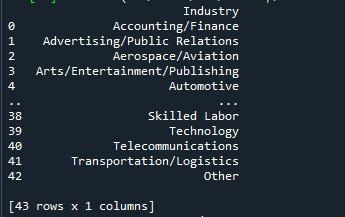
जब हम 'रन फाइल' विकल्प को हिट करके इस पायथन प्रोग्राम को चलाते हैं, तो कंसोल पर एक डेटाफ्रेम प्रदर्शित होता है। आप देख सकते हैं कि नीचे दिए गए परिणाम में 43 पंक्तियाँ हैं लेकिन केवल दस ही प्रदर्शित होती हैं। ऐसा इसलिए है क्योंकि पंडों की लाइब्रेरी का डिफ़ॉल्ट मान केवल 10 पंक्तियाँ हैं।
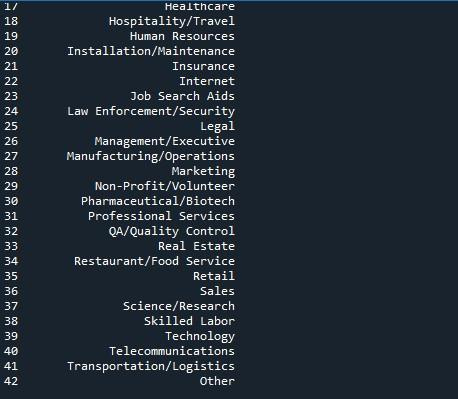
हम यहां सभी पंक्तियों को प्रदर्शित करने के लिए पांडा विधि 'to_string' का उपयोग करेंगे। डेटा फ़्रेम से अधिकतम पंक्तियों को दिखाने का सबसे सरल तरीका इस तकनीक के साथ है। हालांकि, चूंकि यह पूरे डेटा फ़्रेम को एक स्ट्रिंग में बदल देता है, इसलिए बहुत बड़े डेटासेट (लाखों में) के लिए इसकी अनुशंसा नहीं की जाती है। फिर भी, यह हजारों की लंबाई वाले डेटासेट के लिए प्रभावी ढंग से काम करता है।
हमने 'to_string ()' फ़ंक्शन के लिए ऊपर दिए गए सिंटैक्स का पालन किया है। हमने बस अपने डेटाफ़्रेम के नाम के साथ 'to_string ()' विधि को लागू किया। फिर हमने इस विधि को 'प्रिंट ()' फ़ंक्शन में कॉल करने पर इसे प्रदर्शित करने के लिए रखा।

आउटपुट स्नैपशॉट हमें टर्मिनल पर प्रदर्शित होने वाली सभी पंक्तियों के साथ एक डेटाफ़्रेम दिखाता है।
उदाहरण # 2: पंडों का उपयोग करना set_option विधि
इस गाइड में हम जिस दूसरी विधि का अभ्यास करेंगे, वह है प्रदान किए गए डेटाफ्रेम की अधिकतम पंक्तियों को प्रदर्शित करने के लिए पांडा 'set_option ()'।
पायथन फ़ाइल में, हमने उपरोक्त फ़ंक्शन तक पहुँचने के लिए पांडा लाइब्रेरी को आयात किया है। हमने प्रदान की गई CSV फ़ाइल को पढ़ने के लिए पांडा “pd.read_csv ()” का उपयोग किया है। हमने CSV फ़ाइल के नाम के साथ 'pd.read_CSV ()' फ़ंक्शन का आह्वान किया, जिसे हम इसके कोष्ठकों के बीच उपयोग करना चाहते हैं जो 'Sampledata.csv' है। CSV फ़ाइल आयात करते समय, Python प्रोग्राम की वर्तमान कार्यशील निर्देशिका को ध्यान में रखें। आपकी CSV फ़ाइल को उसी निर्देशिका में रखा जाना चाहिए; अन्यथा, आपको एक त्रुटि संदेश मिलेगा 'फ़ाइल नहीं मिली'। हमने CSV फ़ाइल से डेटाफ़्रेम को संग्रहीत करने के लिए एक चर 'नमूना' बनाया है। हमने इस डेटाफ़्रेम को दिखाने के लिए 'प्रिंट ()' विधि को बुलाया।
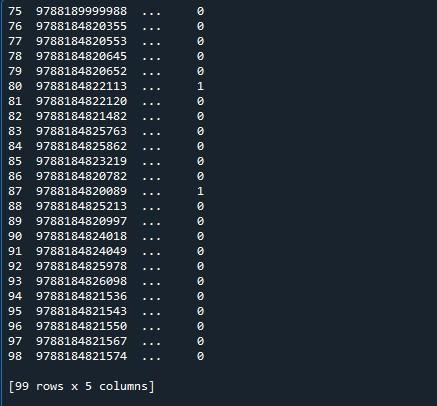
यहां, हमारे पास हमारा आउटपुट है जहां केवल दस पंक्तियां प्रदर्शित होती हैं। इंगित की गई पंक्तियों की अधिकतम संख्या 99 है। पहली 5 और अंतिम पाँच पंक्तियों के बीच की अन्य सभी पंक्तियों को छोटा कर दिया गया है।

इस डेटाफ़्रेम के लिए अधिकतम 99 पंक्तियाँ प्रदर्शित करने के लिए, हम पांडा मॉड्यूल के 'set_option ()' फ़ंक्शन का उपयोग करेंगे। पांडा एक ऑपरेटिंग सिस्टम के साथ आते हैं जो आपको व्यवहार और प्रदर्शन को बदलने की अनुमति देता है। यह विधि हमें प्रदर्शन को छोटे डेटा फ़्रेम के बजाय पूर्ण डेटा फ़्रेम प्रदर्शित करने के लिए सेट करने में सक्षम बनाती है। पांडा डेटा फ़्रेम की सभी पंक्तियों को प्रदर्शित करने के लिए 'set_ विकल्प ()' फ़ंक्शन प्रदान करते हैं।
हमने 'pd.set_option ()' को लागू किया है। इस फ़ंक्शन में 'display.max_rows' पैरामीटर हैं। 'display.max_rows' उन पंक्तियों की अधिकतम संख्या निर्दिष्ट करता है जो डेटाफ़्रेम प्रदर्शित करते समय प्रदर्शित की जाएंगी। 'Max_rows' का मान डिफ़ॉल्ट रूप से 10 पर सेट होता है। यदि 'कोई नहीं' चुना जाता है, तो यह डेटा फ़्रेम में सभी पंक्तियों को दर्शाता है। जैसा कि हम सभी पंक्तियों को प्रदर्शित करना चाहते हैं, इसलिए हम इसे 'कोई नहीं' पर सेट करते हैं। अंत में, हमने अधिकतम पंक्तियों के साथ डेटाफ़्रेम प्रदर्शित करने के लिए 'प्रिंट ()' फ़ंक्शन का उपयोग किया।

यह नीचे दिए गए स्नैपशॉट में दिए गए परिणाम देता है।
उदाहरण # 3: पंडों का उपयोग करना विकल्प_संदर्भ () विधि
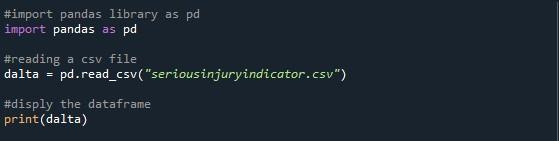
अंतिम विधि जिसकी हम यहां चर्चा कर रहे हैं, वह है 'option_context ()' सभी डेटाफ़्रेम की पंक्तियों को प्रदर्शित करने के लिए। इसके लिए हमने पांडा पैकेज को पायथन फाइल में इंपोर्ट किया और कोड लिखना शुरू किया। हमने निर्दिष्ट CSV फ़ाइल को पढ़ने के लिए 'pd.read_csv ()' फ़ंक्शन का उपयोग किया है। हमने निर्दिष्ट CSV फ़ाइल से डेटाफ़्रेम को संग्रहीत करने के लिए एक चर 'dalta' बनाया है। फिर, हमने केवल 'प्रिंट ()' विधि के साथ डेटाफ़्रेम मुद्रित किया।
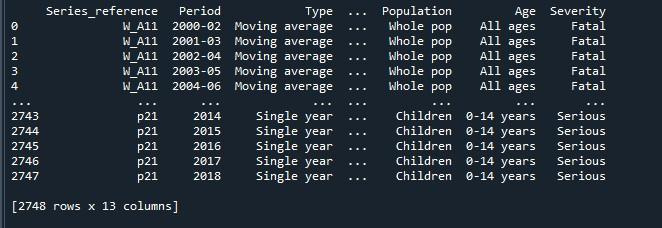
उपरोक्त कोड को निष्पादित करने से हमें जो परिणाम प्राप्त हुआ है, वह हमें काटे गए पंक्तियों के साथ एक डेटाफ़्रेम दिखाता है।
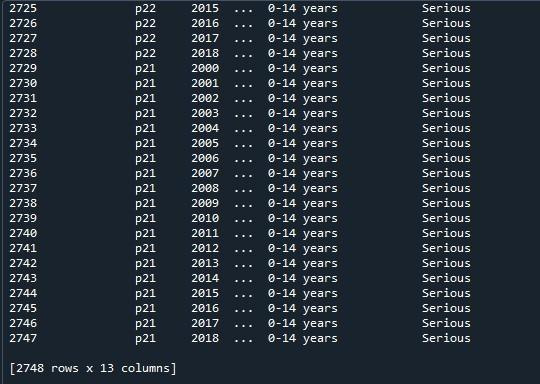
अब हम इस डेटाफ्रेम पर पांडा 'pd.option_context ()' लागू करेंगे। यह फ़ंक्शन 'set_option ()' के समान है। दो दृष्टिकोणों के बीच एकमात्र अंतर यह है कि 'set_option ()' सेटिंग्स को स्थायी रूप से बदलता है, जबकि 'विकल्प _context ()' ने उन्हें इसके दायरे में बदल दिया है। यह विधि डिस्प्ले.मैक्स पंक्तियों को एक पैरामीटर के रूप में भी लेती है, जिसे हम डेटा फ्रेम की सभी पंक्तियों को प्रस्तुत करने के लिए 'कोई नहीं' पर सेट करते हैं। इस फ़ंक्शन को लागू करने के बाद, हमने इसे 'प्रिंट ()' विधि के माध्यम से प्रदर्शित किया।

यहां, हम संपूर्ण डेटाफ्रेम को इसकी अधिकतम पंक्तियों के साथ देख सकते हैं जो 2747 हैं।
निष्कर्ष
यह लेख पांडा के प्रदर्शन विकल्पों पर केंद्रित है। हमें कभी-कभी टर्मिनल पर पूर्ण डेटाफ़्रेम देखने की आवश्यकता हो सकती है। इस उद्देश्य के लिए पांडा हमें कई तरह के विकल्प देते हैं। इस गाइड में, हमने इनमें से तीन रणनीतियों का उपयोग किया है। पहला उदाहरण 'to_string ()' पद्धति का उपयोग करने पर आधारित था। हमारा दूसरा उदाहरण हमें 'set_option ()' को लागू करना सिखाता है जबकि अंतिम उदाहरण 'Option_context ()' विधि को निष्पादित करता है। इन सभी तकनीकों का प्रदर्शन आपको उन वैकल्पिक तरीकों से परिचित कराने के लिए किया जाता है जो पांडा हमें आवश्यक परिणाम प्राप्त करने के लिए प्रदान करते हैं।