C++ भाषा की शुरुआत 1983 में हुई थी, इसके तुरंत बाद 'बजारे स्ट्राउस्ट्रप' ऑपरेटर ओवरलोडिंग जैसी कुछ अतिरिक्त सुविधाओं के साथ सी भाषा में कक्षाओं के साथ काम किया। उपयोग किए गए फ़ाइल एक्सटेंशन '.c' और '.cpp' हैं। सी ++ एक्स्टेंसिबल है और प्लेटफॉर्म पर निर्भर नहीं है और इसमें एसटीएल शामिल है जो स्टैंडर्ड टेम्प्लेट लाइब्रेरी का संक्षिप्त नाम है। इसलिए, मूल रूप से ज्ञात सी ++ भाषा को वास्तव में एक संकलित भाषा के रूप में जाना जाता है जिसमें स्रोत फ़ाइल को ऑब्जेक्ट फ़ाइलों को बनाने के लिए एक साथ संकलित किया जाता है, जब एक लिंकर के साथ मिलकर एक चलने योग्य प्रोग्राम उत्पन्न होता है।
दूसरी ओर, अगर हम इसके स्तर के बारे में बात करते हैं, तो यह मध्यम स्तर का है जो निम्न-स्तरीय प्रोग्रामिंग जैसे ड्राइवर या कर्नेल और उच्च-स्तरीय ऐप जैसे गेम, जीयूआई या डेस्कटॉप ऐप के लाभ की व्याख्या करता है। लेकिन C और C++ दोनों के लिए सिंटैक्स लगभग समान है।
C++ भाषा के अवयव:
#शामिल करें
यह कमांड एक हेडर फाइल है जिसमें 'cout' कमांड शामिल है। उपयोगकर्ता की जरूरतों और प्राथमिकताओं के आधार पर एक से अधिक हेडर फाइल हो सकती हैं।
मुख्य प्रवेश बिंदु()
यह कथन मास्टर प्रोग्राम फ़ंक्शन है जो प्रत्येक C++ प्रोग्राम के लिए एक पूर्वापेक्षा है, जिसका अर्थ है कि इस कथन के बिना कोई भी C++ प्रोग्राम निष्पादित नहीं कर सकता है। यहां 'int' रिटर्न वेरिएबल डेटा प्रकार है जो फ़ंक्शन के डेटा के प्रकार के बारे में बता रहा है।
घोषणा:
चर घोषित किए जाते हैं और उन्हें नाम दिए जाते हैं।
समस्या का विवरण:
यह एक कार्यक्रम में आवश्यक है और 'जबकि' लूप, 'लूप के लिए' या किसी अन्य शर्त को लागू किया जा सकता है।
ऑपरेटर:
ऑपरेटरों का उपयोग सी ++ कार्यक्रमों में किया जाता है और कुछ महत्वपूर्ण हैं क्योंकि वे शर्तों पर लागू होते हैं। कुछ महत्वपूर्ण ऑपरेटर हैं &&, ||, !, &, !=, |, &=, |=, ^, ^=.
सी ++ इनपुट आउटपुट:
अब, हम C++ में इनपुट और आउटपुट क्षमताओं पर चर्चा करेंगे। सी ++ में उपयोग किए जाने वाले सभी मानक पुस्तकालय अधिकतम इनपुट और आउटपुट क्षमताओं को प्रदान कर रहे हैं जो बाइट्स के अनुक्रम के रूप में किए जाते हैं या सामान्य रूप से धाराओं से संबंधित होते हैं।
आगत प्रवाह:
यदि बाइट्स को डिवाइस से मुख्य मेमोरी में स्ट्रीम किया जाता है, तो यह इनपुट स्ट्रीम है।
आउटपुट स्ट्रीम:
यदि बाइट्स को विपरीत दिशा में स्ट्रीम किया जाता है, तो यह आउटपुट स्ट्रीम है।
C++ में इनपुट और आउटपुट को सुविधाजनक बनाने के लिए हेडर फाइल का उपयोग किया जाता है। इसे
उदाहरण:
हम एक वर्ण प्रकार स्ट्रिंग का उपयोग करके एक स्ट्रिंग संदेश प्रदर्शित करेंगे।
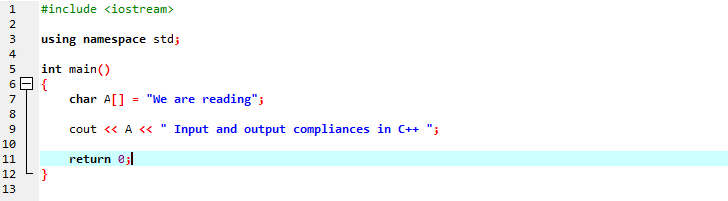
पहली पंक्ति में, हम 'iostream' को शामिल कर रहे हैं जिसमें लगभग सभी आवश्यक पुस्तकालय हैं जिनकी हमें C++ प्रोग्राम के निष्पादन के लिए आवश्यकता हो सकती है। अगली पंक्ति में, हम एक नाम स्थान की घोषणा कर रहे हैं जो पहचानकर्ताओं के लिए गुंजाइश प्रदान करता है। मुख्य फंक्शन को कॉल करने के बाद, हम एक कैरेक्टर टाइप ऐरे को इनिशियलाइज़ कर रहे हैं जो स्ट्रिंग मैसेज को स्टोर करता है और 'cout' इसे कॉन्टेनेट करके प्रदर्शित करता है। हम स्क्रीन पर टेक्स्ट प्रदर्शित करने के लिए 'cout' का उपयोग कर रहे हैं। इसके अलावा, हमने वर्णों की एक स्ट्रिंग को संग्रहीत करने के लिए एक वर्ण डेटा प्रकार सरणी वाला एक चर 'ए' लिया और फिर हमने 'cout' कमांड का उपयोग करके स्थिर संदेश के साथ दोनों सरणी संदेश जोड़ा।
उत्पन्न आउटपुट नीचे दिखाया गया है:

उदाहरण:
इस मामले में, हम एक साधारण स्ट्रिंग संदेश में उपयोगकर्ता की आयु का प्रतिनिधित्व करेंगे।
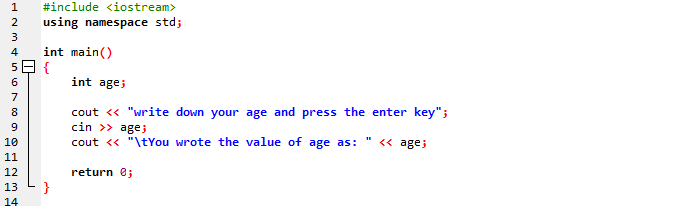
पहले चरण में हम पुस्तकालय को शामिल कर रहे हैं। उसके बाद, हम एक नाम स्थान का उपयोग कर रहे हैं जो पहचानकर्ताओं के लिए गुंजाइश प्रदान करेगा। अगले चरण में, हम कॉल कर रहे हैं मुख्य() समारोह। जिसके बाद, हम उम्र को 'int' वेरिएबल के रूप में इनिशियलाइज़ कर रहे हैं। हम इनपुट के लिए 'cin' कमांड और साधारण स्ट्रिंग संदेश के आउटपुट के लिए 'cout' कमांड का उपयोग कर रहे हैं। 'सिन' उपयोगकर्ता से उम्र के मूल्य को इनपुट करता है और 'कोउट' इसे अन्य स्थिर संदेश में प्रदर्शित करता है।

यह संदेश प्रोग्राम को क्रियान्वित करने के बाद स्क्रीन पर दिखाया जाता है ताकि उपयोगकर्ता आयु प्राप्त कर सके और फिर ENTER दबा सके।

उदाहरण:
यहां, हम प्रदर्शित करते हैं कि 'cout' के उपयोग से एक स्ट्रिंग को कैसे प्रिंट किया जाए।

एक स्ट्रिंग को प्रिंट करने के लिए, हम शुरू में एक पुस्तकालय और फिर पहचानकर्ताओं के लिए नाम स्थान शामिल करते हैं। मुख्य() समारोह कहा जाता है। इसके अलावा, हम सम्मिलन ऑपरेटर के साथ 'cout' कमांड का उपयोग करके एक स्ट्रिंग आउटपुट प्रिंट कर रहे हैं जो तब स्क्रीन पर स्थिर संदेश प्रदर्शित कर रहा है।

सी ++ डेटा प्रकार:
सी ++ में डेटा प्रकार एक बहुत ही महत्वपूर्ण और व्यापक रूप से ज्ञात विषय है क्योंकि यह सी ++ प्रोग्रामिंग भाषा का आधार है। इसी तरह, उपयोग किया जाने वाला कोई भी चर एक निर्दिष्ट या पहचाने गए डेटा प्रकार का होना चाहिए।
हम जानते हैं कि सभी चरों के लिए, हम डेटा प्रकार का उपयोग घोषणा के दौरान डेटा प्रकार को सीमित करने के लिए करते हैं जिसे पुनर्स्थापित करने की आवश्यकता होती है। या, हम कह सकते हैं कि डेटा प्रकार हमेशा एक चर को बताते हैं कि वह किस प्रकार का डेटा स्वयं संग्रहीत कर रहा है। हर बार जब हम एक वेरिएबल को परिभाषित करते हैं, तो कंपाइलर घोषित डेटा प्रकार के आधार पर मेमोरी आवंटित करता है क्योंकि प्रत्येक डेटा प्रकार में एक अलग मेमोरी स्टोरेज क्षमता होती है।
C++ भाषा डेटा प्रकारों की विविधता में सहायता कर रही है ताकि प्रोग्रामर उपयुक्त डेटा प्रकार का चयन कर सके जिसकी उसे आवश्यकता हो।
C++ नीचे बताए गए डेटा प्रकारों के उपयोग की सुविधा प्रदान करता है:
- उपयोगकर्ता-परिभाषित डेटा प्रकार
- व्युत्पन्न डेटा प्रकार
- अंतर्निहित डेटा प्रकार
उदाहरण के लिए, कुछ सामान्य डेटा प्रकारों को आरंभ करके डेटा प्रकारों के महत्व को स्पष्ट करने के लिए निम्नलिखित पंक्तियाँ दी गई हैं:
पूर्णांक एक = दो ; // पूर्णांक मूल्यपानी पर तैरना F_N = 3.66 ; // फ्लोटिंग-पॉइंट वैल्यू
दोहरा डी_एन = 8.87 ; // डबल फ़्लोटिंग-पॉइंट मान
चारो अल्फा = 'पी' ; // चरित्र
बूल बी = सच ; // बूलियन
कुछ सामान्य डेटा प्रकार: वे किस आकार को निर्दिष्ट करते हैं और उनके चर किस प्रकार की जानकारी संग्रहीत करेंगे, नीचे दिखाए गए हैं:
- चार: एक बाइट के आकार के साथ, यह एक एकल वर्ण, अक्षर, संख्या या ASCII मानों को संग्रहीत करेगा।
- बूलियन: 1 बाइट के आकार के साथ, यह मानों को सही या गलत के रूप में संग्रहीत और लौटाएगा।
- Int: 2 या 4 बाइट्स के आकार के साथ, यह दशमलव के बिना पूर्ण संख्याओं को संग्रहीत करेगा।
- फ़्लोटिंग पॉइंट: 4 बाइट्स के आकार के साथ, यह एक या अधिक दशमलव वाले भिन्नात्मक संख्याओं को संग्रहीत करेगा। यह 7 दशमलव अंकों तक स्टोर करने के लिए पर्याप्त है।
- डबल फ़्लोटिंग पॉइंट: 8 बाइट्स के आकार के साथ, यह उन भिन्नात्मक संख्याओं को भी संग्रहीत करेगा जिनमें एक या अधिक दशमलव हैं। यह 15 दशमलव अंकों तक संग्रहीत करने के लिए पर्याप्त है।
- शून्य: बिना किसी निर्दिष्ट आकार के एक शून्य में कुछ मूल्यहीन होता है। इसलिए, इसका उपयोग उन कार्यों के लिए किया जाता है जो एक शून्य मान लौटाते हैं।
- वाइड कैरेक्टर: 8-बिट से अधिक आकार के साथ जो आमतौर पर 2 या 4 बाइट लंबा होता है, जिसे wchar_t द्वारा दर्शाया जाता है जो कि चार के समान होता है और इस प्रकार एक कैरेक्टर वैल्यू भी स्टोर करता है।
प्रोग्राम या कंपाइलर के उपयोग के आधार पर उपर्युक्त चरों का आकार भिन्न हो सकता है।
उदाहरण:
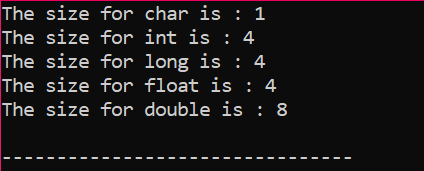
आइए बस C++ में एक साधारण कोड लिखें जो ऊपर वर्णित कुछ डेटा प्रकारों के सटीक आकार देगा:

इस कोड में, हम लाइब्रेरी
आउटपुट बाइट्स में प्राप्त होता है जैसा कि चित्र में दिखाया गया है:
उदाहरण:
यहां हम दो अलग-अलग डेटा प्रकारों का आकार जोड़ेंगे।
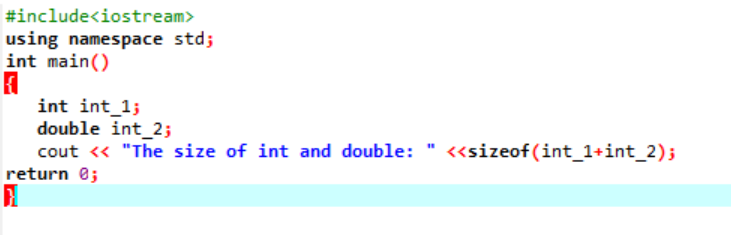
सबसे पहले, हम पहचानकर्ताओं के लिए 'मानक नाम स्थान' का उपयोग करते हुए एक हेडर फ़ाइल शामिल कर रहे हैं। अगला, मुख्य() फ़ंक्शन को कहा जाता है जिसमें हम पहले 'int' वेरिएबल को इनिशियलाइज़ कर रहे हैं और फिर इन दोनों के साइज़ के बीच अंतर की जाँच करने के लिए एक 'डबल' वेरिएबल को इनिशियलाइज़ कर रहे हैं। फिर, उनके आकार को के उपयोग से जोड़ा जाता है का आकार() समारोह। आउटपुट को 'cout' स्टेटमेंट द्वारा प्रदर्शित किया जाता है।

एक और शब्द है जिसका यहाँ उल्लेख करना है और वह है 'डेटा संशोधक' . नाम से पता चलता है कि 'डेटा संशोधक' का उपयोग अंतर्निहित डेटा प्रकारों के साथ उनकी लंबाई को संशोधित करने के लिए किया जाता है जिसे एक निश्चित डेटा प्रकार संकलक की आवश्यकता या आवश्यकता के अनुसार बनाए रख सकता है।
निम्नलिखित डेटा संशोधक हैं जो C++ में उपलब्ध हैं:
- पर हस्ताक्षर किए
- अहस्ताक्षरित
- लंबा
- छोटा
संशोधित आकार और साथ ही अंतर्निहित डेटा प्रकारों की उपयुक्त श्रेणी का उल्लेख नीचे किया गया है जब उन्हें डेटा प्रकार संशोधक के साथ जोड़ा जाता है:
- लघु इंट: 2 बाइट्स के आकार के साथ, -32,768 से 32,767 तक के संशोधनों की एक श्रृंखला है
- अहस्ताक्षरित लघु इंट: 2 बाइट्स के आकार के साथ, इसमें 0 से 65,535 . तक के संशोधनों की एक श्रृंखला है
- अहस्ताक्षरित इंट: 4 बाइट्स के आकार के साथ, 0 से 4,294,967,295 तक के संशोधनों की एक श्रृंखला है
- इंट: 4 बाइट्स के आकार के साथ, -2,147,483,648 से 2,147,483,647 तक संशोधन की एक सीमा है
- लॉन्ग इंट: 4 बाइट्स के आकार वाले, -2,147,483,648 से 2,147,483,647 तक के संशोधन की एक सीमा है
- अहस्ताक्षरित लंबा इंट: 4 बाइट्स के आकार के साथ, इसमें 0 से 4,294,967.295 तक कई संशोधन हैं।
- लॉन्ग लॉन्ग इंट: 8 बाइट्स के आकार के साथ, -(2^63) से (2^63)-1 तक के संशोधनों की एक श्रृंखला है
- अहस्ताक्षरित लंबा लंबा इंट: 8 बाइट्स के आकार के साथ, इसमें 0 से 18,446,744,073,709,551,615 तक कई संशोधन हैं।
- हस्ताक्षरित चार: 1 बाइट के आकार के साथ, -128 से 127 . तक कई संशोधन हैं
- अहस्ताक्षरित चार: 1 बाइट के आकार के साथ, 0 से 255 तक के संशोधनों की एक श्रृंखला है।
सी ++ गणना:
C++ प्रोग्रामिंग भाषा में 'गणना' एक उपयोगकर्ता द्वारा परिभाषित डेटाटाइप है। गणना को 'के रूप में घोषित किया गया है एनम' सी ++ में। इसका उपयोग प्रोग्राम में उपयोग किए जाने वाले किसी भी स्थिरांक को विशिष्ट नाम आवंटित करने के लिए किया जाता है। यह कार्यक्रम की पठनीयता और उपयोगिता में सुधार करता है।
वाक्य - विन्यास:
हम C++ में एन्यूमरेशन की घोषणा इस प्रकार करते हैं:
एन्यूम enum_Name { लगातार1 , लगातार 2 , लगातार3… }C++ में एन्यूमरेशन के लाभ:
Enum का उपयोग निम्नलिखित तरीकों से किया जा सकता है:
- इसे स्विच केस स्टेटमेंट में अक्सर इस्तेमाल किया जा सकता है।
- यह कंस्ट्रक्टर, फ़ील्ड और विधियों का उपयोग कर सकता है।
- यह केवल 'एनम' वर्ग का विस्तार कर सकता है, किसी अन्य वर्ग का नहीं।
- यह संकलन समय बढ़ा सकता है।
- इसे पार किया जा सकता है।
C++ में एन्यूमरेशन के नुकसान:
Enum के कुछ नुकसान भी हैं:
यदि एक बार किसी नाम की गणना कर दी जाती है तो उसे उसी दायरे में दोबारा इस्तेमाल नहीं किया जा सकता है।
उदाहरण के लिए:
एन्यूम दिन{ बैठा , रवि , मेरे } ;
पूर्णांक बैठा = 8 ; // इस लाइन में त्रुटि है
Enum अग्रेषित घोषित नहीं किया जा सकता है।
उदाहरण के लिए:
एन्यूम आकार ;कक्षा का रंग
{
शून्य चित्र बनाना ( आकार ) ; // आकार घोषित नहीं किया गया है
} ;
वे नाम की तरह दिखते हैं लेकिन वे पूर्णांक हैं। इसलिए, वे स्वचालित रूप से किसी अन्य डेटाटाइप में परिवर्तित हो सकते हैं।
उदाहरण के लिए:
एन्यूम आकार{
त्रिकोण , घेरा , वर्ग
} ;
पूर्णांक रंग = नीला ;
रंग = वर्ग ;
उदाहरण:
इस उदाहरण में, हम C++ एन्यूमरेशन का उपयोग देखते हैं:
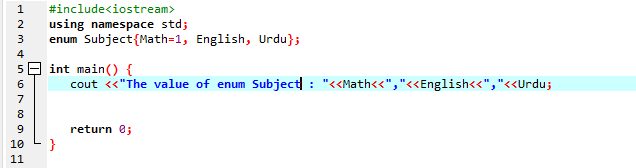
इस कोड निष्पादन में, सबसे पहले, हम #include
यहाँ निष्पादित कार्यक्रम का हमारा परिणाम है:

तो, जैसा कि आप देख सकते हैं कि हमारे पास विषय के मूल्य हैं: गणित, उर्दू, अंग्रेजी; यानी 1,2,3।
उदाहरण:
यहां एक और उदाहरण दिया गया है जिसके माध्यम से हम एनम के बारे में अपनी अवधारणाओं को स्पष्ट करते हैं:
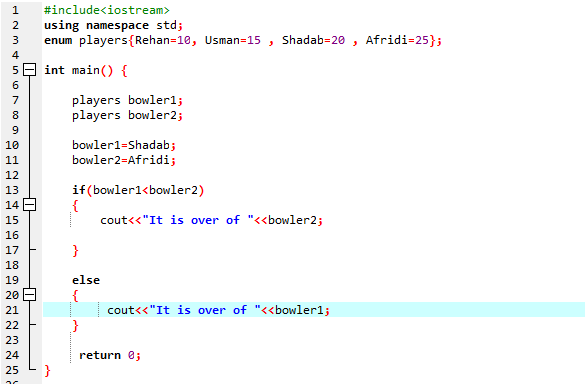
इस कार्यक्रम में, हम हेडर फ़ाइल
हमें if-else कथन का उपयोग करना होगा . हमने 'if' स्टेटमेंट के अंदर कंपेरिजन ऑपरेटर का भी इस्तेमाल किया है, जिसका मतलब है कि हम तुलना कर रहे हैं कि क्या 'bowler2', 'bowler1' से बड़ा है। फिर, 'if' ब्लॉक निष्पादित होता है जिसका अर्थ है कि यह अफरीदी का ओवर है। फिर, हमने आउटपुट प्रदर्शित करने के लिए 'cout<<' दर्ज किया। सबसे पहले, हम 'इट इज ओवर' स्टेटमेंट प्रिंट करते हैं। फिर, 'गेंदबाज 2' का मान। यदि नहीं, तो अन्य ब्लॉक लगाया जाता है, जिसका अर्थ है कि यह शादाब का ओवर है। फिर, 'cout<<' कमांड को लागू करके हम 'It is over' कथन प्रदर्शित करते हैं। फिर, 'गेंदबाज 1' का मान।

इफ-इफ स्टेटमेंट के अनुसार, हमारे पास 25 से अधिक हैं जो अफरीदी का मूल्य है। इसका मतलब है कि एनम वेरिएबल 'बॉलर 2' का मान 'बॉलर 1' से अधिक है, इसलिए 'अगर' स्टेटमेंट को निष्पादित किया जाता है।
सी ++ यदि और, स्विच करें:
C++ प्रोग्रामिंग लैंग्वेज में हम प्रोग्राम के फ्लो को मॉडिफाई करने के लिए 'if स्टेटमेंट' और 'स्विच स्टेटमेंट' का इस्तेमाल करते हैं। इन कथनों का उपयोग क्रमशः उल्लिखित कथनों के सही मूल्य के आधार पर कार्यक्रम के कार्यान्वयन के लिए कमांड के कई सेट प्रदान करने के लिए किया जाता है। ज्यादातर मामलों में, हम 'if' स्टेटमेंट के विकल्प के रूप में ऑपरेटरों का उपयोग करते हैं। ये सभी उपर्युक्त कथन चयन कथन हैं जिन्हें निर्णयात्मक या सशर्त कथन के रूप में जाना जाता है।
'अगर' कथन:
जब भी आपको किसी प्रोग्राम के प्रवाह को बदलने का मन करता है तो इस कथन का उपयोग किसी दी गई स्थिति का परीक्षण करने के लिए किया जाता है। यहां, यदि कोई शर्त सत्य है, तो प्रोग्राम लिखित निर्देशों को निष्पादित करेगा लेकिन यदि शर्त गलत है, तो यह समाप्त हो जाएगा। आइए एक उदाहरण पर विचार करें;
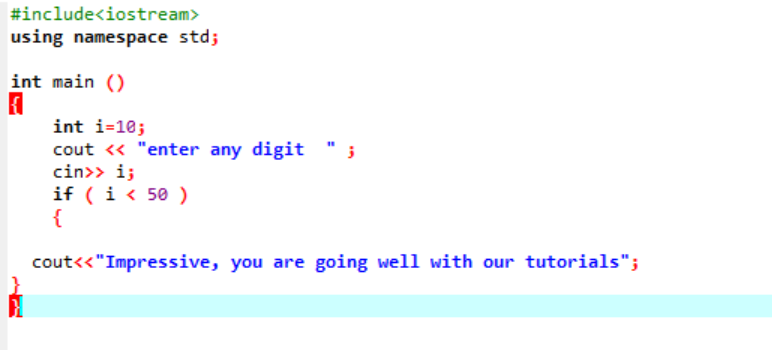
यह उपयोग किया जाने वाला सरल 'if' स्टेटमेंट है, जहां हम 'int' वेरिएबल को 10 के रूप में इनिशियलाइज़ कर रहे हैं। फिर, यूजर से एक वैल्यू लिया जाता है और इसे 'if' स्टेटमेंट में क्रॉस-चेक किया जाता है। यदि यह 'if' स्टेटमेंट में लागू शर्तों को पूरा करता है, तो आउटपुट प्रदर्शित होता है।

चूंकि चुना गया अंक 40 था, आउटपुट संदेश है।
'अगर-अन्य' कथन:
एक अधिक जटिल कार्यक्रम में जहां 'if' कथन आमतौर पर सहयोग नहीं करता है, हम 'if-else' कथन का उपयोग करते हैं। दिए गए मामले में, हम लागू शर्तों की जांच के लिए 'if- else' कथन का उपयोग कर रहे हैं।
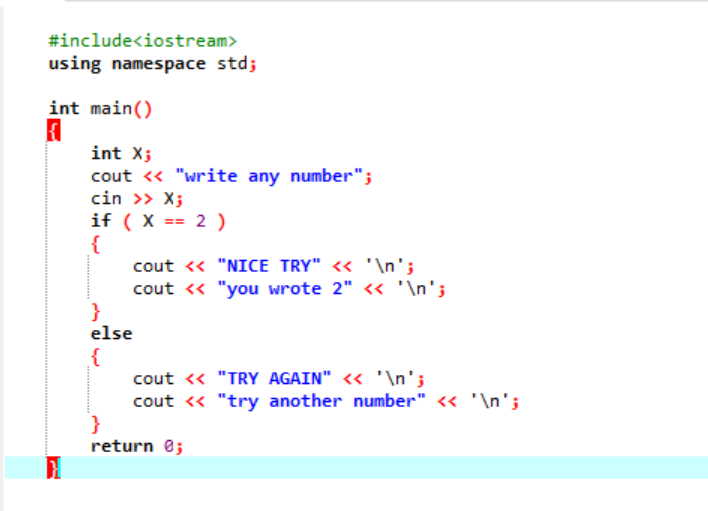
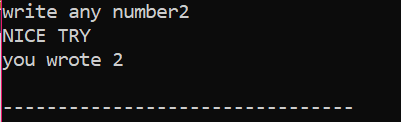
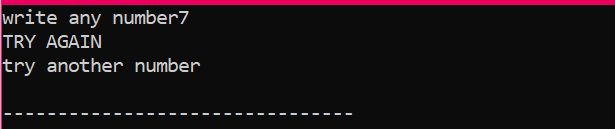
सबसे पहले, हम 'x' नामक डेटाटाइप 'int' का एक वैरिएबल घोषित करेंगे जिसका मूल्य उपयोगकर्ता से लिया गया है। अब, 'if' स्टेटमेंट का उपयोग किया जाता है, जहां हमने एक शर्त लागू की है कि यदि उपयोगकर्ता द्वारा दर्ज किया गया पूर्णांक मान 2 है। आउटपुट वांछित होगा और एक साधारण 'NICE TRY' संदेश प्रदर्शित किया जाएगा। अन्यथा, यदि दर्ज की गई संख्या 2 नहीं है, तो आउटपुट भिन्न होगा।
जब उपयोगकर्ता संख्या 2 लिखता है, तो निम्न आउटपुट दिखाया जाता है।
जब उपयोगकर्ता 2 को छोड़कर कोई अन्य संख्या लिखता है, तो हमें जो आउटपुट मिलता है वह है:
इफ-इफ-इफ स्टेटमेंट:
नेस्टेड if-else-if स्टेटमेंट काफी जटिल होते हैं और एक ही कोड में कई शर्तें लागू होने पर उपयोग किए जाते हैं। आइए एक अन्य उदाहरण का उपयोग करके इस पर विचार करें:
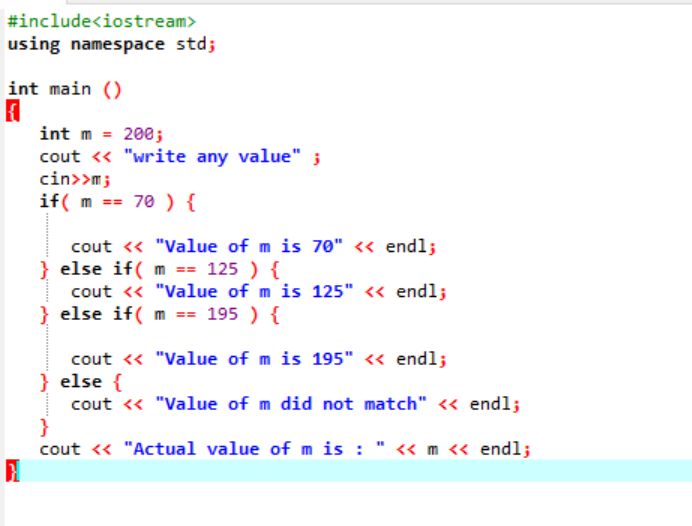
यहां, हेडर फ़ाइल और नेमस्पेस को एकीकृत करने के बाद, हमने वेरिएबल 'm' के मान को 200 के रूप में इनिशियलाइज़ किया। 'm' का मान तब उपयोगकर्ता से लिया जाता है और फिर प्रोग्राम में बताई गई कई शर्तों के साथ क्रॉस-चेक किया जाता है।
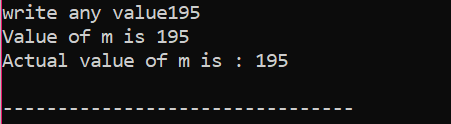
यहां, उपयोगकर्ता ने मान 195 चुना। यही कारण है कि आउटपुट से पता चलता है कि यह 'm' का वास्तविक मान है।
स्विच स्टेटमेंट:
एक 'स्विच' स्टेटमेंट का उपयोग C++ में एक वेरिएबल के लिए किया जाता है जिसका परीक्षण करने की आवश्यकता होती है यदि यह कई मानों की सूची के बराबर है। 'स्विच' स्टेटमेंट में, हम अलग-अलग मामलों के रूप में स्थितियों की पहचान करते हैं और सभी मामलों में प्रत्येक केस स्टेटमेंट के अंत में एक ब्रेक शामिल होता है। कई मामलों में ब्रेक स्टेटमेंट के साथ उचित शर्तें और स्टेटमेंट लागू होते हैं जो स्विच स्टेटमेंट को समाप्त कर देते हैं और कोई शर्त समर्थित नहीं होने की स्थिति में डिफ़ॉल्ट स्टेटमेंट पर चले जाते हैं।
कीवर्ड 'ब्रेक':
स्विच स्टेटमेंट में 'ब्रेक' कीवर्ड होता है। यह कोड को बाद के मामले में निष्पादित करने से रोकता है। स्विच स्टेटमेंट का निष्पादन तब समाप्त होता है जब C ++ कंपाइलर 'ब्रेक' कीवर्ड के सामने आता है और नियंत्रण उस लाइन पर चला जाता है जो स्विच स्टेटमेंट का अनुसरण करती है। स्विच में ब्रेक स्टेटमेंट का उपयोग करना आवश्यक नहीं है। यदि इसका उपयोग नहीं किया जाता है तो निष्पादन अगले मामले में आगे बढ़ता है।
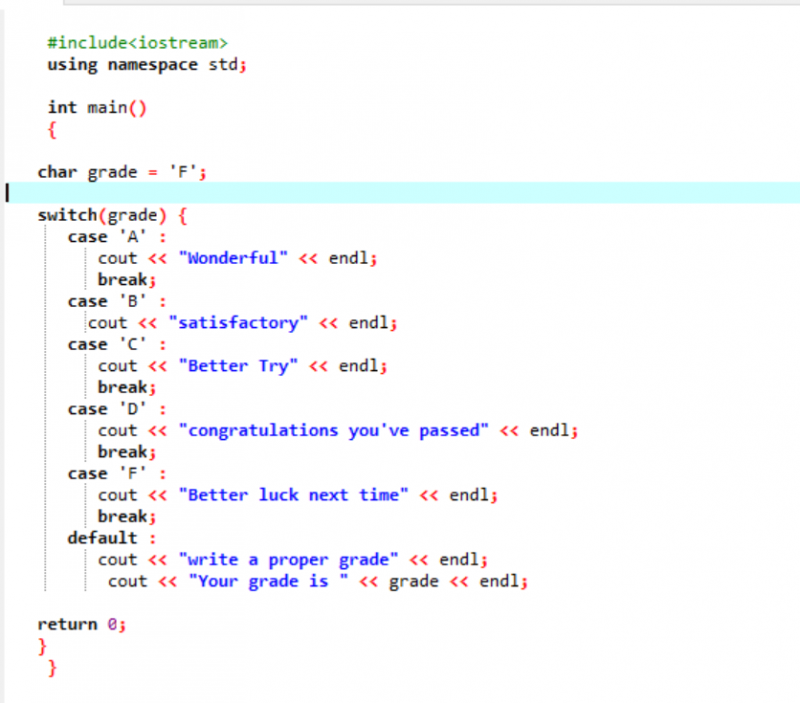
साझा किए गए कोड की पहली पंक्ति में, हम पुस्तकालय को शामिल कर रहे हैं। जिसके बाद हम 'नेमस्पेस' जोड़ रहे हैं। हम आह्वान करते हैं मुख्य() समारोह। फिर, हम एक चरित्र डेटाटाइप ग्रेड को 'एफ' के रूप में घोषित कर रहे हैं। यह ग्रेड आपकी इच्छा हो सकती है और चुने गए मामलों के लिए परिणाम क्रमशः दिखाया जाएगा। हमने परिणाम प्राप्त करने के लिए स्विच स्टेटमेंट लागू किया।
यदि हम ग्रेड के रूप में 'एफ' चुनते हैं, तो आउटपुट 'बेहतर भाग्य अगली बार' होता है क्योंकि यह वह कथन है जिसे हम ग्रेड 'एफ' के मामले में मुद्रित करना चाहते हैं।

आइए ग्रेड को X में बदलें और देखें कि क्या होता है। मैंने ग्रेड के रूप में 'X' लिखा है और प्राप्त आउटपुट नीचे दिखाया गया है:

तो, 'स्विच' में अनुचित मामला स्वचालित रूप से पॉइंटर को सीधे डिफ़ॉल्ट स्टेटमेंट पर ले जाता है और प्रोग्राम को समाप्त कर देता है।
if-else और स्विच स्टेटमेंट में कुछ सामान्य विशेषताएं हैं:
- इन कथनों का उपयोग यह प्रबंधित करने के लिए किया जाता है कि प्रोग्राम कैसे निष्पादित किया जाता है।
- वे दोनों एक शर्त का मूल्यांकन करते हैं और यह निर्धारित करता है कि कार्यक्रम कैसे प्रवाहित होता है।
- विभिन्न प्रतिनिधित्व शैली होने के बावजूद, उनका उपयोग एक ही उद्देश्य के लिए किया जा सकता है।
if-else और स्विच स्टेटमेंट कुछ खास तरीकों से भिन्न होते हैं:
- जबकि उपयोगकर्ता ने 'स्विच' केस स्टेटमेंट में मानों को परिभाषित किया है, जबकि बाधाएं 'if-else' स्टेटमेंट में मान निर्धारित करती हैं।
- यह निर्धारित करने में समय लगता है कि परिवर्तन कहाँ करने की आवश्यकता है, 'अगर-अन्य' कथनों को संशोधित करना चुनौतीपूर्ण है। दूसरी ओर, 'स्विच' कथन अद्यतन करने के लिए सरल हैं क्योंकि उन्हें आसानी से संशोधित किया जा सकता है।
- कई अभिव्यक्तियों को शामिल करने के लिए, हम कई 'if-else' कथनों का उपयोग कर सकते हैं।
सी ++ लूप्स:
अब, हम जानेंगे कि C++ प्रोग्रामिंग में लूप्स का उपयोग कैसे किया जाता है। 'लूप' के रूप में जानी जाने वाली नियंत्रण संरचना बयानों की एक श्रृंखला को दोहराती है। दूसरे शब्दों में, इसे दोहरावदार संरचना कहा जाता है। अनुक्रमिक संरचना में सभी कथनों को एक साथ निष्पादित किया जाता है . दूसरी ओर, निर्दिष्ट कथन के आधार पर, स्थिति संरचना एक अभिव्यक्ति को निष्पादित या छोड़ सकती है। विशेष परिस्थितियों में एक से अधिक बार किसी कथन को निष्पादित करने की आवश्यकता हो सकती है।
लूप के प्रकार:
लूप की तीन श्रेणियां हैं:
पाश के लिए:
लूप एक ऐसी चीज है जो खुद को एक चक्र की तरह दोहराती है और जब यह प्रदान की गई शर्त को मान्य नहीं करती है तो रुक जाती है। एक 'फॉर' लूप कई बार बयानों के अनुक्रम को लागू करता है और उस कोड को संघनित करता है जो लूप वेरिएबल से मुकाबला करता है। यह दर्शाता है कि कैसे 'फॉर' लूप एक विशिष्ट प्रकार की पुनरावृत्ति नियंत्रण संरचना है जो हमें एक लूप बनाने की अनुमति देता है जिसे कई बार दोहराया जाता है। लूप हमें केवल एक साधारण लाइन के कोड का उपयोग करके चरणों की 'एन' संख्या को निष्पादित करने की अनुमति देगा। आइए उस सिंटैक्स के बारे में बात करते हैं जिसका उपयोग हम आपके सॉफ़्टवेयर एप्लिकेशन में 'फॉर' लूप के निष्पादन के लिए करेंगे।
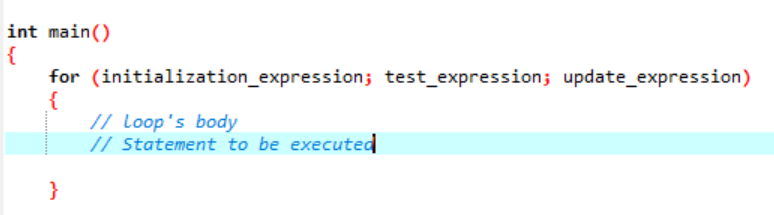
'फॉर' लूप निष्पादन का सिंटैक्स:
उदाहरण:
यहां, हम इस लूप को 'फॉर' लूप में रेगुलेट करने के लिए लूप वेरिएबल का उपयोग करते हैं। पहला कदम इस चर के लिए एक मान निर्दिष्ट करना होगा जिसे हम लूप के रूप में बता रहे हैं। उसके बाद, हमें परिभाषित करना चाहिए कि यह काउंटर वैल्यू से कम है या अधिक है। अब, लूप की बॉडी को निष्पादित किया जाना है और स्टेटमेंट के सही होने की स्थिति में लूप वेरिएबल को भी अपडेट किया जाता है। उपरोक्त चरणों को अक्सर तब तक दोहराया जाता है जब तक हम बाहर निकलने की स्थिति में नहीं पहुंच जाते।
- प्रारंभिक अभिव्यक्ति: सबसे पहले, हमें इस अभिव्यक्ति में लूप काउंटर को किसी भी प्रारंभिक मान पर सेट करने की आवश्यकता है।
- टेस्ट एक्सप्रेशन : अब, हमें दिए गए व्यंजक में दी गई स्थिति का परीक्षण करने की आवश्यकता है। यदि मानदंड पूरे होते हैं, तो हम 'फॉर' लूप की बॉडी को पूरा करेंगे और एक्सप्रेशन को अपडेट करना जारी रखेंगे; यदि नहीं, तो हमें रुक जाना चाहिए।
- अद्यतन अभिव्यक्ति: लूप के शरीर को निष्पादित करने के बाद यह अभिव्यक्ति लूप चर को एक निश्चित मान से बढ़ाती या घटाती है।
C++ प्रोग्राम उदाहरण 'फॉर' लूप को मान्य करने के लिए:
उदाहरण:
यह उदाहरण 0 से 10 तक पूर्णांक मानों की छपाई दिखाता है।
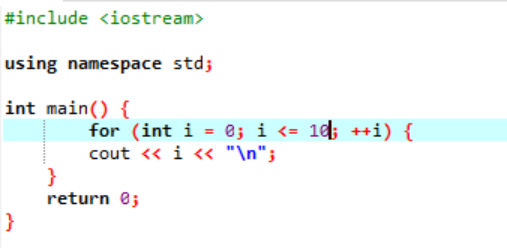
इस परिदृश्य में, हमें 0 से 10 तक के पूर्णांकों को प्रिंट करना चाहिए। सबसे पहले, हमने एक यादृच्छिक चर i को एक मान के साथ आरंभ किया है, जिसे '0' दिया गया है और फिर जिस स्थिति पैरामीटर का हमने पहले से उपयोग किया है, वह स्थिति की जाँच करता है यदि i<=10। और जब यह शर्त को पूरा करता है और यह सच हो जाता है, तो 'फॉर' लूप का निष्पादन शुरू हो जाता है। निष्पादन के बाद, दो इंक्रीमेंट या डिक्रीमेंट मापदंडों में से एक को निष्पादित किया जाएगा और जिसमें निर्दिष्ट स्थिति i<=10 के गलत होने तक, वेरिएबल i का मान बढ़ जाता है।

शर्त के साथ पुनरावृत्तियों की संख्या <10:
| की संख्या पुनरावृत्तियों |
चर | मैं<10 | गतिविधि |
| प्रथम | मैं = 0 | सच | 0 प्रदर्शित होता है और i को 1 से बढ़ा दिया जाता है। |
| दूसरा | मैं = 1 | सच | 1 प्रदर्शित होता है और i 2 से बढ़ जाता है। |
| तीसरा | मैं = 2 | सच | 2 प्रदर्शित होता है और i 3 से बढ़ जाता है। |
| चौथी | मैं = 3 | सच | 3 प्रदर्शित होता है और i को 4 से बढ़ा दिया जाता है। |
| पांचवां | मैं = 4 | सच | 4 प्रदर्शित होता है और i को 5 से बढ़ा दिया जाता है। |
| छठा | मैं = 5 | सच | 5 प्रदर्शित होता है और i में 6 की वृद्धि होती है। |
| सातवीं | मैं=6 | सच | 6 प्रदर्शित होता है और i में 7 की वृद्धि होती है। |
| आठवाँ | मैं=7 | सच | 7 प्रदर्शित होता है और i 8 . से बढ़ जाता है |
| नौवां | मैं = 8 | सच | 8 प्रदर्शित होता है और i को 9 से बढ़ा दिया जाता है। |
| दसवां | मैं=9 | सच | 9 प्रदर्शित होता है और i 10 से बढ़ जाता है। |
| ग्यारहवें | मैं = 10 | सच | 10 प्रदर्शित होता है और i को 11 से बढ़ा दिया जाता है। |
| बारहवें | मैं = 11 | असत्य | लूप समाप्त हो गया है। |
उदाहरण:
निम्न उदाहरण पूर्णांक का मान प्रदर्शित करता है:
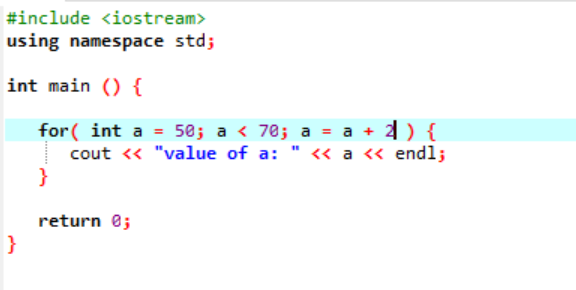
उपरोक्त मामले में, 'ए' नामक एक चर को 50 दिए गए मान के साथ प्रारंभ किया जाता है। एक शर्त लागू होती है जहां चर 'ए' 70 से कम है। फिर, 'ए' का मान अपडेट किया जाता है जैसे कि इसे जोड़ा जाता है 2. 'ए' का मान तब प्रारंभिक मान से शुरू होता है जो 50 था और 2 को पूरे लूप में समवर्ती रूप से जोड़ा जाता है जब तक कि स्थिति झूठी नहीं हो जाती है और 'ए' का मान 70 से बढ़ जाता है और लूप समाप्त हो जाता है।
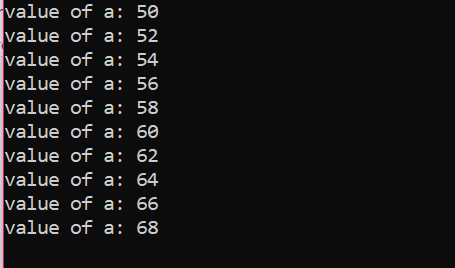
पुनरावृत्तियों की संख्या:
| की संख्या यात्रा |
चर | ए = 50 | गतिविधि |
| प्रथम | ए = 50 | सच | a का मान दो और पूर्णांक जोड़कर अद्यतन किया जाता है और 50 52 . हो जाता है |
| दूसरा | ए = 52 | सच | a का मान दो और पूर्णांक जोड़कर अद्यतन किया जाता है और 52 हो जाता है 54 |
| तीसरा | ए = 54 | सच | a का मान दो और पूर्णांक जोड़कर अद्यतन किया जाता है और 54 हो जाता है 56 |
| चौथी | ए = 56 | सच | a का मान दो और पूर्णांक जोड़कर अद्यतन किया जाता है और 56 हो जाता है 58 |
| पांचवां | ए = 58 | सच | a का मान दो और पूर्णांक जोड़कर अद्यतन किया जाता है और 58 60 . हो जाता है |
| छठा | ए = 60 | सच | a का मान दो और पूर्णांक जोड़कर अद्यतन किया जाता है और 60 62 . हो जाता है |
| सातवीं | ए = 62 | सच | a का मान दो और पूर्णांक जोड़कर अद्यतन किया जाता है और 62 64 . हो जाता है |
| आठवाँ | ए = 64 | सच | a का मान दो और पूर्णांक जोड़कर अद्यतन किया जाता है और 64 हो जाता है 66 |
| नौवां | ए = 66 | सच | a का मान दो और पूर्णांक जोड़कर अद्यतन किया जाता है और 66 68 . हो जाता है |
| दसवां | ए = 68 | सच | a का मान दो और पूर्णांक जोड़कर अद्यतन किया जाता है और 68 70 . हो जाता है |
| ग्यारहवें | ए = 70 | असत्य | लूप समाप्त हो गया है |
घुमाव के दौरान:
जब तक परिभाषित शर्त पूरी नहीं हो जाती, तब तक एक या अधिक कथनों को निष्पादित किया जा सकता है। जब पुनरावृत्ति पहले से अज्ञात हो, तो यह बहुत उपयोगी होती है। सबसे पहले, स्थिति की जाँच की जाती है और फिर कथन को निष्पादित या कार्यान्वित करने के लिए लूप के शरीर में प्रवेश करती है।
पहली पंक्ति में, हम हेडर फ़ाइल
डू-जबकि लूप:
जब परिभाषित शर्त पूरी हो जाती है, तो बयानों की एक श्रृंखला की जाती है। सबसे पहले, लूप के शरीर को बाहर किया जाता है। उसके बाद, स्थिति की जाँच की जाती है कि यह सच है या नहीं। इसलिए, कथन को एक बार निष्पादित किया जाता है। स्थिति का मूल्यांकन करने से पहले लूप के शरीर को 'डू-जबकि' लूप में संसाधित किया जाता है। जब भी आवश्यक शर्त पूरी होती है तो कार्यक्रम चलता है। अन्यथा, जब स्थिति झूठी होती है, तो प्रोग्राम समाप्त हो जाता है।
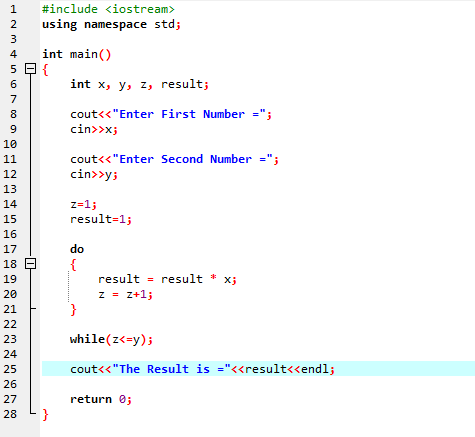
यहां, हम हेडर फाइल
सी ++ जारी रखें / तोड़ें:
सी ++ स्टेटमेंट जारी रखें:
लूप के वर्तमान अवतार से बचने के साथ-साथ बाद के पुनरावृत्ति पर नियंत्रण को स्थानांतरित करने के लिए सी ++ प्रोग्रामिंग भाषा में जारी बयान का उपयोग किया जाता है। लूपिंग के दौरान, जारी कथन का उपयोग कुछ कथनों को छोड़ने के लिए किया जा सकता है। इसका उपयोग लूप के भीतर कार्यकारी बयानों के साथ संयोजन में भी किया जाता है। यदि विशिष्ट शर्त सत्य है, तो जारी कथन के बाद सभी कथन लागू नहीं किए जाते हैं।
लूप के साथ:
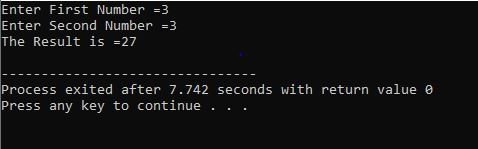
इस उदाहरण में, हम कुछ निर्दिष्ट आवश्यकताओं को पारित करते समय आवश्यक परिणाम प्राप्त करने के लिए C++ से जारी कथन के साथ 'लूप के लिए' का उपयोग करते हैं।

हम
थोड़ी देर के लूप के साथ:
इस पूरे प्रदर्शन के दौरान, हमने कुछ शर्तों सहित 'जबकि लूप' और C++ 'जारी रखें' कथन दोनों का उपयोग किया, यह देखने के लिए कि किस प्रकार का आउटपुट उत्पन्न किया जा सकता है।
इस उदाहरण में, हम केवल 40 में संख्याओं को जोड़ने के लिए एक शर्त निर्धारित करते हैं। यदि दर्ज किया गया पूर्णांक एक ऋणात्मक संख्या है, तो 'जबकि' लूप समाप्त हो जाएगा। दूसरी ओर, यदि संख्या 40 से अधिक है, तो वह विशिष्ट संख्या पुनरावृत्ति से छूट जाएगी।
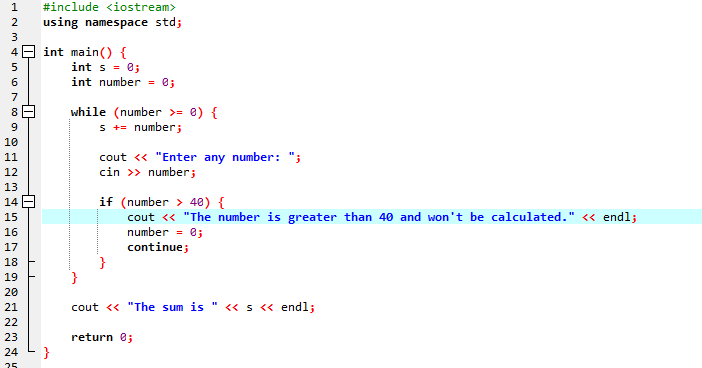
हम 'नेमस्पेस एसटीडी' का उपयोग करते हुए
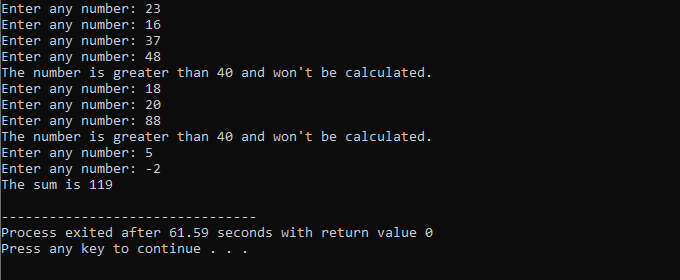
सी ++ ब्रेक स्टेटमेंट:
जब भी सी ++ में लूप में ब्रेक स्टेटमेंट का उपयोग किया जाता है, तो लूप तुरंत समाप्त हो जाता है और साथ ही लूप के बाद स्टेटमेंट पर प्रोग्राम कंट्रोल फिर से शुरू हो जाता है। किसी मामले को 'स्विच' स्टेटमेंट के अंदर समाप्त करना भी संभव है।
लूप के साथ:
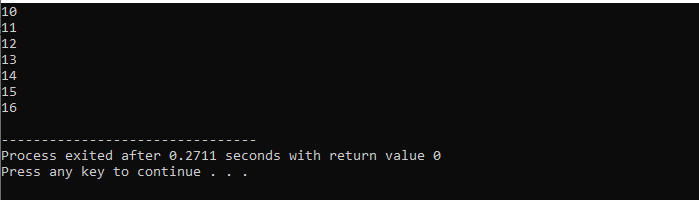
यहां, हम विभिन्न मूल्यों पर पुनरावृति करके आउटपुट का निरीक्षण करने के लिए 'ब्रेक' स्टेटमेंट के साथ 'फॉर' लूप का उपयोग करेंगे।
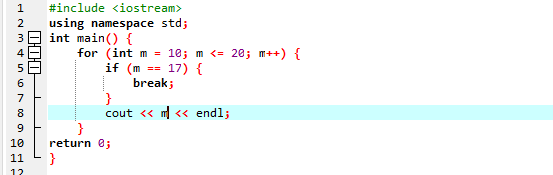
सबसे पहले, हम एक
थोड़ी देर के लूप के साथ:
हम ब्रेक स्टेटमेंट के साथ 'जबकि' लूप को नियोजित करने जा रहे हैं।
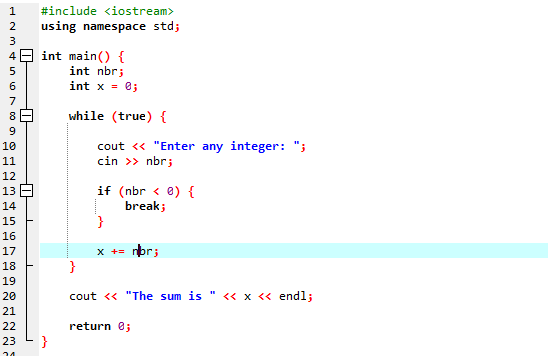
हम
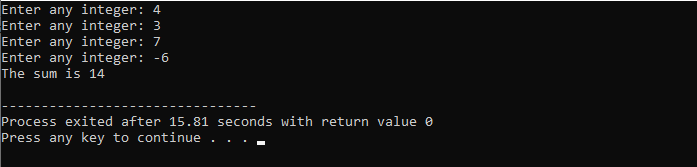
सी ++ कार्य:
फ़ंक्शंस का उपयोग पहले से ज्ञात प्रोग्राम को कोड के कई टुकड़ों में संरचित करने के लिए किया जाता है जो इसे कॉल करने पर ही निष्पादित होते हैं। सी ++ प्रोग्रामिंग भाषा में, एक फ़ंक्शन को बयानों के समूह के रूप में परिभाषित किया जाता है जिन्हें उचित नाम दिया जाता है और उनके द्वारा बुलाया जाता है। उपयोगकर्ता उन कार्यों में डेटा पास कर सकता है जिन्हें हम पैरामीटर कहते हैं। जब कोड के पुन: उपयोग की सबसे अधिक संभावना होती है, तो कार्यों को लागू करने के लिए कार्य जिम्मेदार होते हैं।
एक समारोह का निर्माण:
हालाँकि C++ कई पूर्व-निर्धारित कार्य प्रदान करता है जैसे मुख्य(), जो कोड के निष्पादन की सुविधा प्रदान करता है। इसी तरह आप अपने फंक्शन्स को अपनी आवश्यकता के अनुसार बना और परिभाषित कर सकते हैं। सभी सामान्य कार्यों की तरह, यहां, आपको एक घोषणा के लिए अपने फ़ंक्शन के लिए एक नाम की आवश्यकता होती है जिसे बाद में एक कोष्ठक के साथ जोड़ा जाता है '()'।
वाक्य - विन्यास:
शून्य श्रम ( ){
// समारोह का शरीर
}
शून्य फ़ंक्शन का रिटर्न प्रकार है। श्रम इसे दिया गया नाम है और घुंघराले कोष्ठक फ़ंक्शन के शरीर को संलग्न करेंगे जहां हम निष्पादन के लिए कोड जोड़ते हैं।
किसी फ़ंक्शन को कॉल करना:
कोड में घोषित कार्यों को केवल तभी निष्पादित किया जाता है जब उन्हें बुलाया जाता है। किसी फ़ंक्शन को कॉल करने के लिए, आपको कोष्ठक के साथ फ़ंक्शन का नाम निर्दिष्ट करना होगा जिसके बाद अर्धविराम ';' होगा।
उदाहरण:
आइए इस स्थिति में उपयोगकर्ता द्वारा परिभाषित फ़ंक्शन की घोषणा करें और निर्माण करें।
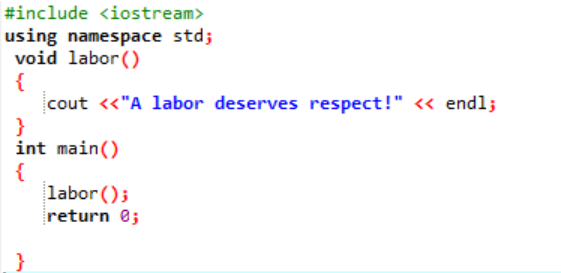
प्रारंभ में, जैसा कि प्रत्येक कार्यक्रम में वर्णित है, हमें कार्यक्रम के निष्पादन का समर्थन करने के लिए एक पुस्तकालय और नाम स्थान सौंपा गया है। उपयोगकर्ता द्वारा परिभाषित फ़ंक्शन श्रम() लिखने से पहले हमेशा बुलाया जाता है मुख्य() समारोह। नाम का एक समारोह श्रम() घोषित किया जाता है जहां एक संदेश प्रदर्शित होता है 'एक श्रमिक सम्मान का हकदार है!'। में मुख्य() पूर्णांक रिटर्न प्रकार के साथ फ़ंक्शन, हम कॉल कर रहे हैं श्रम() समारोह।

यह सरल संदेश है जिसे यहां प्रदर्शित उपयोगकर्ता-परिभाषित फ़ंक्शन में परिभाषित किया गया था मुख्य() समारोह।
शून्य:
उपरोक्त उदाहरण में, हमने देखा कि उपयोगकर्ता द्वारा परिभाषित फ़ंक्शन का रिटर्न प्रकार शून्य है। यह इंगित करता है कि फ़ंक्शन द्वारा कोई मान वापस नहीं किया जा रहा है। यह दर्शाता है कि मान मौजूद नहीं है या शायद शून्य है। क्योंकि जब भी कोई फ़ंक्शन केवल संदेशों को प्रिंट कर रहा होता है, तो उसे किसी वापसी मूल्य की आवश्यकता नहीं होती है।
यह शून्य समान रूप से फ़ंक्शन के पैरामीटर स्पेस में स्पष्ट रूप से यह बताने के लिए उपयोग किया जाता है कि यह फ़ंक्शन कॉल करते समय कोई वास्तविक मान नहीं लेता है। उपरोक्त स्थिति में, हम यह भी कहेंगे श्रम() ऐसे काम करता है:
शून्य श्रम ( शून्य ){
अदालत << 'एक मजदूर सम्मान का पात्र है' ! ' ;
}
वास्तविक पैरामीटर:
कोई फ़ंक्शन के लिए पैरामीटर परिभाषित कर सकता है। किसी फ़ंक्शन के पैरामीटर को फ़ंक्शन की तर्क सूची में परिभाषित किया जाता है जो फ़ंक्शन के नाम में जोड़ता है। जब भी हम फ़ंक्शन को कॉल करते हैं, तो हमें निष्पादन को पूरा करने के लिए मापदंडों के वास्तविक मूल्यों को पारित करने की आवश्यकता होती है। इन्हें वास्तविक मापदंडों के रूप में समाप्त किया जाता है। जबकि फ़ंक्शन को परिभाषित करते समय परिभाषित किए गए पैरामीटर औपचारिक पैरामीटर के रूप में जाने जाते हैं।
उदाहरण:
इस उदाहरण में, हम एक फ़ंक्शन के माध्यम से दो पूर्णांक मानों का आदान-प्रदान या स्थानापन्न करने वाले हैं।
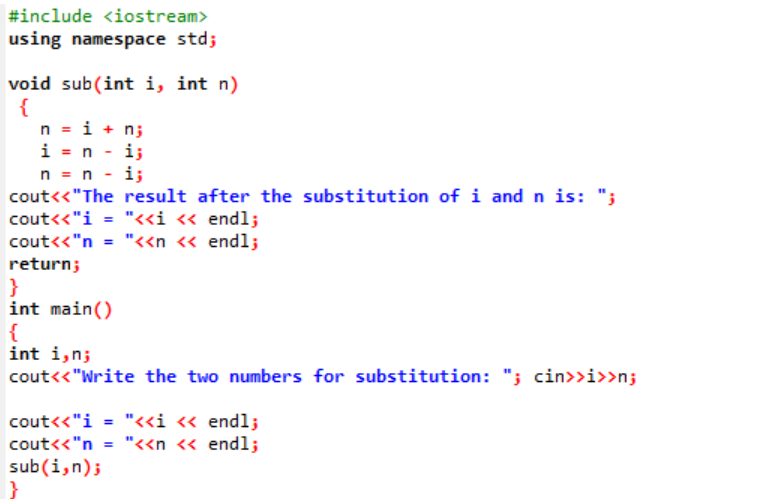
शुरुआत में, हम हेडर फाइल ले रहे हैं। उपयोगकर्ता द्वारा परिभाषित फ़ंक्शन घोषित और परिभाषित नाम है विषय()। इस फ़ंक्शन का उपयोग दो पूर्णांक मानों के प्रतिस्थापन के लिए किया जाता है जो कि i और n हैं। इसके बाद, इन दो पूर्णांकों के आदान-प्रदान के लिए अंकगणितीय ऑपरेटरों का उपयोग किया जाता है। पहले पूर्णांक 'i' का मान 'n' के स्थान पर संग्रहीत किया जाता है और n का मान 'i' के मान के स्थान पर सहेजा जाता है। फिर, मानों को स्विच करने के बाद परिणाम मुद्रित होता है। अगर हम के बारे में बात करते हैं मुख्य() फ़ंक्शन, हम उपयोगकर्ता से दो पूर्णांकों के मान ले रहे हैं और प्रदर्शित कर रहे हैं। अंतिम चरण में, उपयोगकर्ता द्वारा परिभाषित फ़ंक्शन विषय() कहा जाता है और दो मानों को आपस में बदल दिया जाता है।
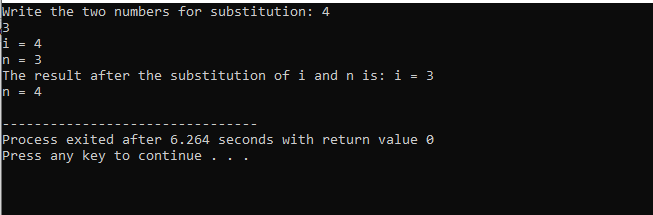
इस मामले में दो संख्याओं को प्रतिस्थापित करने पर, हम स्पष्ट रूप से देख सकते हैं कि का उपयोग करते समय विषय() फ़ंक्शन, पैरामीटर सूची के अंदर 'i' और 'n' का मान औपचारिक पैरामीटर हैं। वास्तविक पैरामीटर वे पैरामीटर हैं जो के अंत में गुजर रहे हैं मुख्य() फ़ंक्शन जहां प्रतिस्थापन फ़ंक्शन कहा जा रहा है।
सी ++ पॉइंटर्स:
सी ++ में पॉइंटर सीखना काफी आसान है और उपयोग करने में बहुत अच्छा है। C++ भाषा में पॉइंटर्स का उपयोग किया जाता है क्योंकि वे हमारे काम को आसान बनाते हैं और पॉइंटर्स शामिल होने पर सभी ऑपरेशन बड़ी दक्षता के साथ काम करते हैं। इसके अलावा, कुछ ऐसे कार्य हैं जो तब तक पूरे नहीं होंगे जब तक कि गतिशील स्मृति आवंटन की तरह पॉइंटर्स का उपयोग नहीं किया जाता है। पॉइंटर्स के बारे में बात करते हुए, मुख्य विचार, जिसे समझना चाहिए, वह यह है कि पॉइंटर सिर्फ एक वैरिएबल है जो सटीक मेमोरी एड्रेस को इसके मूल्य के रूप में संग्रहीत करेगा। C++ में पॉइंटर्स का व्यापक उपयोग निम्न कारणों से होता है:
- एक फ़ंक्शन को दूसरे में पास करने के लिए।
- ढेर पर नई वस्तुओं को आवंटित करने के लिए।
- एक सरणी में तत्वों की पुनरावृत्ति के लिए
आमतौर पर, '&' (एम्पर्सेंड) ऑपरेटर का उपयोग मेमोरी में किसी भी वस्तु के पते तक पहुंचने के लिए किया जाता है।
संकेतक और उनके प्रकार:
पॉइंटर के कई प्रकार होते हैं:
- शून्य संकेत: ये C++ लाइब्रेरी में संग्रहीत शून्य के मान वाले पॉइंटर्स हैं।
- अंकगणित सूचक: इसमें चार प्रमुख अंकगणितीय ऑपरेटर शामिल हैं जो सुलभ हैं जो ++, -, +, - हैं।
- पॉइंटर्स की एक सरणी: वे सरणियाँ हैं जिनका उपयोग कुछ बिंदुओं को संग्रहीत करने के लिए किया जाता है।
- सूचक से सूचक: यह वह जगह है जहाँ एक सूचक के ऊपर एक सूचक का उपयोग किया जाता है।
उदाहरण:
अगले उदाहरण पर विचार करें जिसमें कुछ चरों के पते मुद्रित होते हैं।
हेडर फाइल और स्टैंडर्ड नेमस्पेस को शामिल करने के बाद, हम दो वेरिएबल्स को इनिशियलाइज़ कर रहे हैं। एक पूर्णांक मान है जो i' द्वारा दर्शाया गया है और दूसरा वर्ण प्रकार सरणी 'I' है जिसका आकार 10 वर्णों के साथ है। फिर दोनों चरों के पते 'cout' कमांड का उपयोग करके प्रदर्शित किए जाते हैं।
हमें जो आउटपुट मिला है वह नीचे दिखाया गया है:
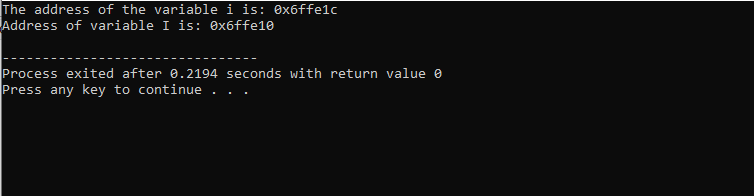
यह परिणाम दोनों चरों के लिए पता दिखाता है।
दूसरी ओर, एक पॉइंटर को एक वेरिएबल माना जाता है जिसका मान स्वयं एक भिन्न वेरिएबल का पता होता है। एक पॉइंटर हमेशा एक डेटाटाइप को इंगित करता है जिसमें एक ही प्रकार होता है जो (*) ऑपरेटर के साथ बनाया जाता है।
एक सूचक की घोषणा:
सूचक इस तरह घोषित किया गया है:
प्रकार * था - नाम ;सूचक का आधार प्रकार 'प्रकार' द्वारा इंगित किया जाता है, जबकि सूचक का नाम 'var-name' द्वारा व्यक्त किया जाता है। और पॉइंटर के लिए एक वेरिएबल को एंटाइटेल करने के लिए तारांकन (*) का उपयोग किया जाता है।
चरों को संकेत देने के तरीके:
पूर्णांक * अनुकरणीय ; // एक पूर्णांक डेटाटाइप का सूचकदोहरा * पी.डी. ; // एक डबल डेटाटाइप का सूचक
पानी पर तैरना * पीएफ ; // फ्लोट डेटाटाइप का सूचक
चारो * पीसी ; // एक चार डेटाटाइप का सूचक
लगभग हमेशा एक लंबी हेक्साडेसिमल संख्या होती है जो स्मृति पते का प्रतिनिधित्व करती है जो प्रारंभ में सभी पॉइंटर्स के लिए उनके डेटाटाइप के बावजूद समान होती है।
उदाहरण:
निम्नलिखित उदाहरण प्रदर्शित करेगा कि कैसे पॉइंटर्स '&' ऑपरेटर को प्रतिस्थापित करते हैं और चर के पते को संग्रहीत करते हैं।
हम पुस्तकालयों और निर्देशिकाओं के समर्थन को एकीकृत करने जा रहे हैं। फिर, हम आह्वान करेंगे मुख्य() फ़ंक्शन जहां हम पहले 55 के मान के साथ 'int' प्रकार के एक चर 'n' को घोषित और प्रारंभ करते हैं। अगली पंक्ति में, हम 'p1' नामक एक सूचक चर प्रारंभ कर रहे हैं। इसके बाद, हम 'n' वेरिएबल का पता पॉइंटर 'p1' को असाइन करते हैं और फिर हम वेरिएबल 'n' का मान दिखाते हैं। 'p1' सूचक में संग्रहीत 'n' का पता प्रदर्शित होता है। बाद में, '*p1' का मान 'cout' कमांड का उपयोग करके स्क्रीन पर प्रिंट होता है। आउटपुट इस प्रकार है:
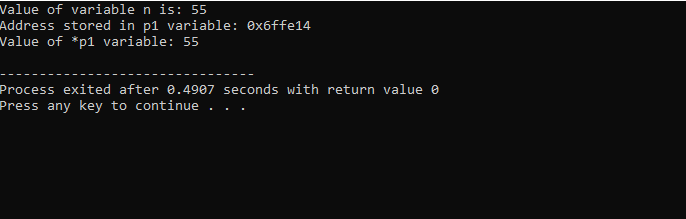
यहाँ, हम देखते हैं कि 'n' का मान 55 है और सूचक 'p1' में संग्रहीत 'n' का पता 0x6ffe14 के रूप में दिखाया गया है। सूचक चर का मान पाया जाता है और यह 55 है जो पूर्णांक चर के मान के समान है। इसलिए, एक सूचक चर के पते को संग्रहीत करता है, और साथ ही * सूचक, में संग्रहीत पूर्णांक का मान होता है जो परिणामस्वरूप प्रारंभिक रूप से संग्रहीत चर का मान वापस कर देगा।
उदाहरण:
आइए एक अन्य उदाहरण पर विचार करें जहां हम एक पॉइंटर का उपयोग कर रहे हैं जो एक स्ट्रिंग के पते को संग्रहीत करता है।
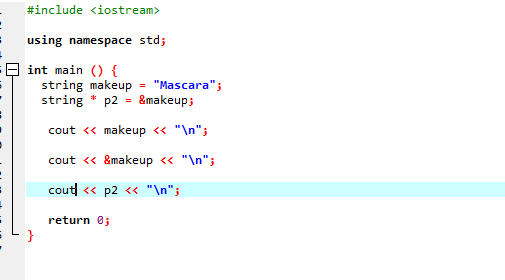
इस कोड में, हम पहले लाइब्रेरी और नेमस्पेस जोड़ रहे हैं। में मुख्य() समारोह में हमें 'मेकअप' नाम की एक स्ट्रिंग घोषित करनी होती है, जिसमें 'काजल' का मान होता है। एक स्ट्रिंग टाइप पॉइंटर '*p2' का उपयोग मेकअप वेरिएबल के पते को स्टोर करने के लिए किया जाता है। वेरिएबल 'मेकअप' का मान तब 'cout' स्टेटमेंट का उपयोग करते हुए स्क्रीन पर प्रदर्शित होता है। इसके बाद वेरिएबल 'मेकअप' का एड्रेस प्रिंट किया जाता है और अंत में पॉइंटर वेरिएबल 'p2' को पॉइंटर के साथ 'मेकअप' वेरिएबल का मेमोरी एड्रेस दिखाते हुए प्रदर्शित किया जाता है।
उपरोक्त कोड से प्राप्त आउटपुट इस प्रकार है:
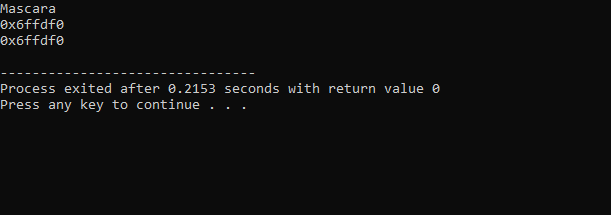
पहली पंक्ति में प्रदर्शित 'मेकअप' चर का मान है। दूसरी पंक्ति चर 'मेकअप' का पता दिखाती है। अंतिम पंक्ति में, सूचक के उपयोग के साथ 'मेकअप' चर का स्मृति पता दिखाया गया है।
सी ++ मेमोरी प्रबंधन:
C++ में प्रभावी मेमोरी मैनेजमेंट के लिए, C++ में काम करते समय मेमोरी के प्रबंधन के लिए कई ऑपरेशन मददगार होते हैं। जब हम सी ++ का उपयोग करते हैं, तो सबसे अधिक इस्तेमाल की जाने वाली मेमोरी आवंटन प्रक्रिया गतिशील मेमोरी आवंटन होती है जहां मेमोरी को रनटाइम के दौरान चरों को सौंपा जाता है; अन्य प्रोग्रामिंग भाषाओं की तरह नहीं जहां कंपाइलर मेमोरी को वेरिएबल में आवंटित कर सकता है। C++ में, गतिशील रूप से आवंटित किए गए वेरिएबल्स का डीलोकेशन आवश्यक है, ताकि जब वेरिएबल उपयोग में न हो तो मेमोरी मुक्त हो जाए।
C++ में मेमोरी के डायनेमिक आवंटन और डीलोकेशन के लिए, हम ' नया' तथा 'मिटाना' संचालन। स्मृति को प्रबंधित करना महत्वपूर्ण है ताकि कोई स्मृति बर्बाद न हो। स्मृति का आवंटन आसान और प्रभावी हो जाता है। किसी भी सी ++ प्रोग्राम में, मेमोरी दो पहलुओं में से एक में नियोजित होती है: या तो ढेर या ढेर के रूप में।
- ढेर : सभी वेरिएबल जो फ़ंक्शन के अंदर घोषित किए जाते हैं और फ़ंक्शन से जुड़े हर दूसरे विवरण को स्टैक में संग्रहीत किया जाता है।
- ढेर : किसी भी प्रकार की अप्रयुक्त मेमोरी या जिस हिस्से से हम प्रोग्राम के निष्पादन के दौरान डायनेमिक मेमोरी आवंटित या असाइन करते हैं, उसे हीप के रूप में जाना जाता है।
सरणी का उपयोग करते समय, स्मृति आवंटन एक ऐसा कार्य है जहां हम रनटाइम तक स्मृति को निर्धारित नहीं कर सकते हैं। इसलिए, हम ऐरे को अधिकतम मेमोरी असाइन करते हैं लेकिन यह भी एक अच्छा अभ्यास नहीं है क्योंकि ज्यादातर मामलों में मेमोरी अप्रयुक्त रहती है और यह किसी तरह बर्बाद हो जाती है जो कि आपके पर्सनल कंप्यूटर के लिए एक अच्छा विकल्प या अभ्यास नहीं है। यही कारण है कि, हमारे पास कुछ ऑपरेटर हैं जिनका उपयोग रनटाइम के दौरान हीप से मेमोरी आवंटित करने के लिए किया जाता है। दो प्रमुख ऑपरेटरों 'नया' और 'हटाएं' का उपयोग कुशल मेमोरी आवंटन और डीलोकेशन के लिए किया जाता है।
सी ++ नया ऑपरेटर:
नया ऑपरेटर मेमोरी के आवंटन के लिए जिम्मेदार है और इसका उपयोग निम्नानुसार किया जाता है:
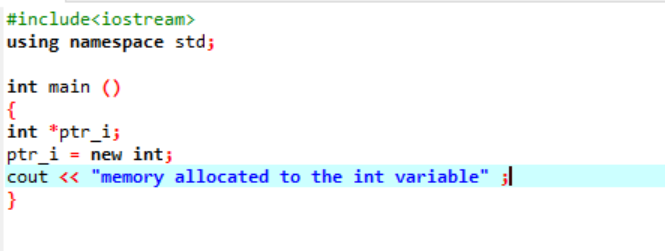
इस कोड में, हम लाइब्रेरी

पॉइंटर के उपयोग से मेमोरी को 'इंट' वेरिएबल को सफलतापूर्वक आवंटित कर दिया गया है।
सी ++ ऑपरेटर हटाएं:
जब भी हम एक वेरिएबल का उपयोग करते हैं, तो हमें उस मेमोरी को हटा देना चाहिए जिसे हमने एक बार आवंटित किया था क्योंकि यह अब उपयोग में नहीं है। इसके लिए हम मेमोरी को रिलीज करने के लिए 'डिलीट' ऑपरेटर का इस्तेमाल करते हैं।
अभी हम जिस उदाहरण की समीक्षा करने जा रहे हैं, उसमें दोनों ऑपरेटरों को शामिल किया गया है।
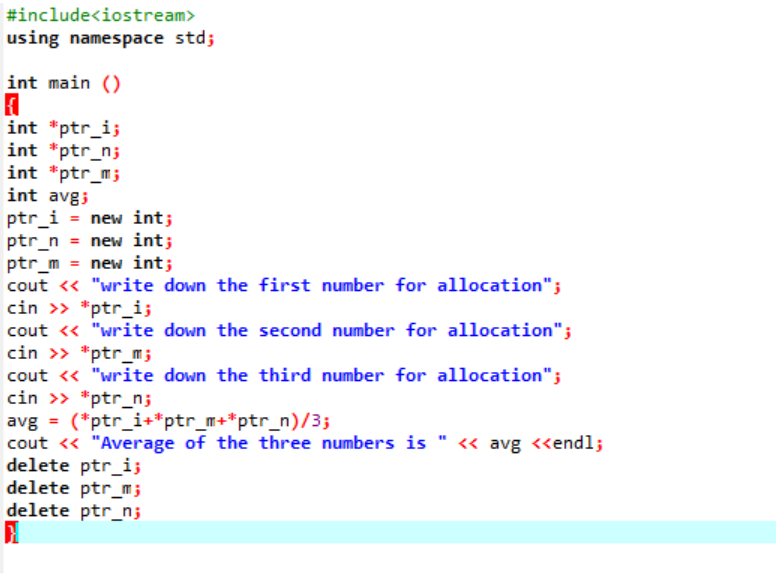
हम उपयोगकर्ता से लिए गए तीन अलग-अलग मानों के औसत की गणना कर रहे हैं। पॉइंटर वेरिएबल्स को मूल्यों को स्टोर करने के लिए 'नए' ऑपरेटर के साथ सौंपा गया है। औसत का सूत्र लागू किया जाता है। इसके बाद, 'डिलीट' ऑपरेटर का उपयोग किया जाता है जो 'नए' ऑपरेटर का उपयोग करके पॉइंटर वेरिएबल्स में संग्रहीत मानों को हटा देता है। यह गतिशील आवंटन है जहां रनटाइम के दौरान आवंटन किया जाता है और फिर कार्यक्रम समाप्त होने के तुरंत बाद डीलोकेशन होता है।
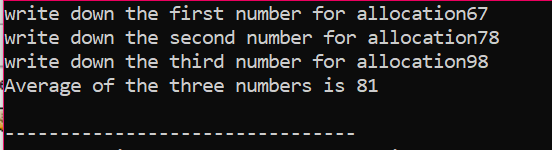
मेमोरी आवंटन के लिए सरणी का उपयोग:
अब, हम यह देखने जा रहे हैं कि सरणियों का उपयोग करते समय 'नए' और 'डिलीट' ऑपरेटरों का उपयोग कैसे किया जाता है। डायनेमिक आवंटन उसी तरह होता है जैसे वेरिएबल्स के लिए हुआ था क्योंकि सिंटैक्स लगभग समान होता है।
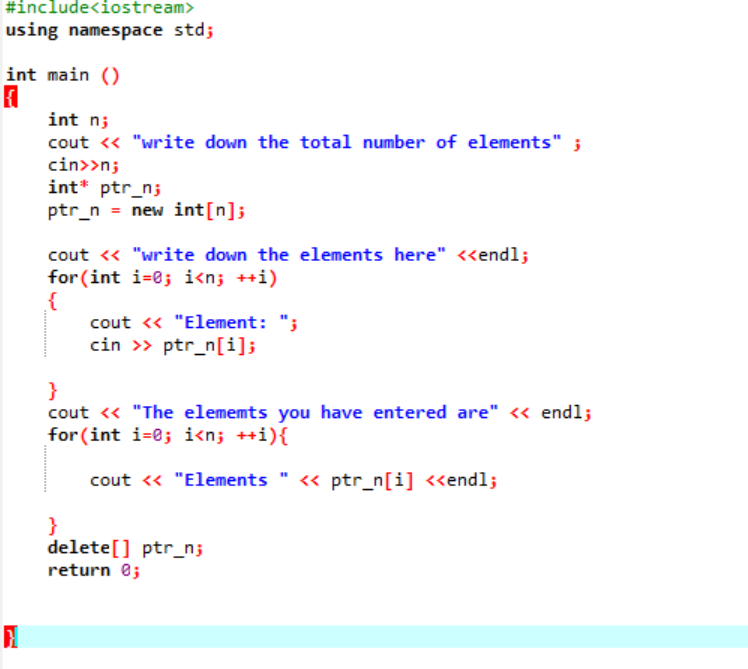
दिए गए उदाहरण में, हम उन तत्वों की सरणी पर विचार कर रहे हैं जिनका मूल्य उपयोगकर्ता से लिया गया है। सरणी के तत्वों को लिया जाता है और सूचक चर घोषित किया जाता है और फिर स्मृति आवंटित की जाती है। मेमोरी आवंटन के तुरंत बाद, सरणी तत्वों की इनपुट प्रक्रिया शुरू हो जाती है। इसके बाद, सरणी तत्वों के लिए आउटपुट 'फॉर' लूप का उपयोग करके दिखाया जाता है। इस लूप में n द्वारा दर्शाए गए ऐरे के वास्तविक आकार से कम आकार वाले तत्वों की पुनरावृत्ति स्थिति है।
जब सभी तत्वों का उपयोग किया जाता है और उन्हें फिर से उपयोग करने की कोई आवश्यकता नहीं होती है, तो तत्वों को सौंपी गई मेमोरी को 'डिलीट' ऑपरेटर का उपयोग करके हटा दिया जाएगा।
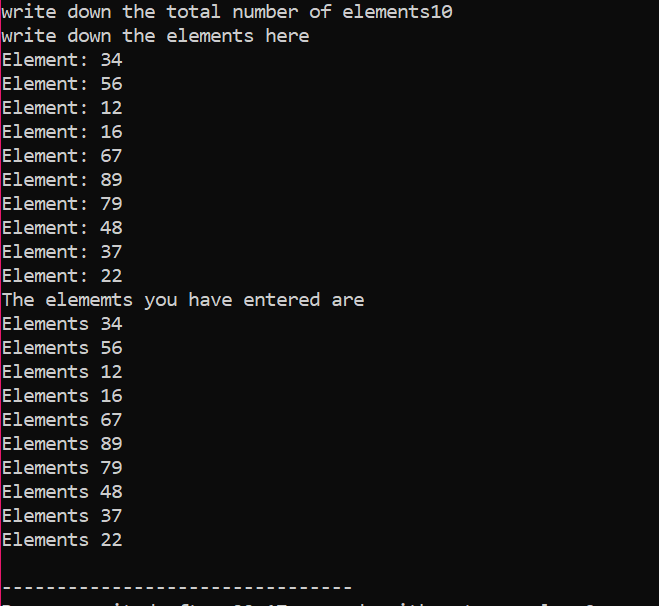
आउटपुट में, हम दो बार मुद्रित मूल्यों के सेट देख सकते थे। पहले 'फॉर' लूप का उपयोग तत्वों के लिए मूल्यों को लिखने के लिए किया गया था और दूसरे 'फॉर' लूप का उपयोग पहले से लिखे गए मूल्यों की छपाई के लिए किया जाता है, यह दर्शाता है कि उपयोगकर्ता ने इन मूल्यों को स्पष्टता के लिए लिखा है।
लाभ:
C++ प्रोग्रामिंग लैंग्वेज में 'नया' और 'डिलीट' ऑपरेटर हमेशा प्राथमिकता होता है और इसका व्यापक रूप से उपयोग किया जाता है। पूरी तरह से चर्चा और समझ होने पर, यह नोट किया जाता है कि 'नए' ऑपरेटर के बहुत सारे फायदे हैं। मेमोरी के आवंटन के लिए 'नए' ऑपरेटर के फायदे इस प्रकार हैं:
- नए ऑपरेटर को अधिक आसानी से ओवरलोड किया जा सकता है।
- रनटाइम के दौरान मेमोरी आवंटित करते समय, जब भी पर्याप्त मेमोरी नहीं होती है, तो प्रोग्राम को समाप्त करने के बजाय एक स्वचालित अपवाद फेंक दिया जाएगा।
- टाइपकास्टिंग प्रक्रिया का उपयोग करने की हलचल यहां मौजूद नहीं है क्योंकि 'नए' ऑपरेटर के पास उसी प्रकार की मेमोरी है जो हमने आवंटित की है।
- 'नया' ऑपरेटर भी आकार () ऑपरेटर का उपयोग करने के विचार को खारिज कर देता है क्योंकि 'नया' अनिवार्य रूप से वस्तुओं के आकार की गणना करेगा।
- 'नया' ऑपरेटर हमें वस्तुओं को आरंभ करने और घोषित करने में सक्षम बनाता है, भले ही यह उनके लिए अनायास जगह पैदा कर रहा हो।
सी ++ सरणी:
हम इस बात पर पूरी तरह से चर्चा करने जा रहे हैं कि C++ प्रोग्राम में सरणियाँ क्या हैं और उन्हें कैसे घोषित और कार्यान्वित किया जाता है। सरणी एक डेटा संरचना है जिसका उपयोग केवल एक चर में कई मानों को संग्रहीत करने के लिए किया जाता है जिससे कई चर को स्वतंत्र रूप से घोषित करने की हलचल कम हो जाती है।
सरणियों की घोषणा:
एक सरणी घोषित करने के लिए, किसी को पहले चर के प्रकार को परिभाषित करना होगा और उस सरणी को एक उपयुक्त नाम देना होगा जिसे बाद में वर्ग कोष्ठक के साथ जोड़ा जाता है। इसमें किसी विशेष सरणी के आकार को दर्शाने वाले तत्वों की संख्या होगी।
उदाहरण के लिए:
स्ट्रिंग मेकअप [ 5 ] ;इस चर को यह दिखाते हुए घोषित किया गया है कि इसमें 'मेकअप' नामक एक सरणी में पाँच तार हैं। इस सरणी के मूल्यों को पहचानने और स्पष्ट करने के लिए, हमें घुंघराले कोष्ठक का उपयोग करने की आवश्यकता है, प्रत्येक तत्व को अलग-अलग दोहरे उल्टे अल्पविराम में संलग्न किया गया है, प्रत्येक को बीच में एक अल्पविराम से अलग किया गया है।
उदाहरण के लिए:
स्ट्रिंग मेकअप [ 5 ] = { 'काजल' , 'टिंट' , 'लिपस्टिक' , 'नींव' , 'प्रथम' } ;इसी तरह, यदि आपको लगता है कि एक अलग डेटाटाइप के साथ एक और सरणी बनाना 'int' माना जाता है, तो प्रक्रिया वही होगी जो आपको नीचे दिखाए गए चर के डेटा प्रकार को बदलने की जरूरत है:
पूर्णांक मल्टीपल्स [ 5 ] = { दो , 4 , 6 , 8 , 10 } ;सरणी को पूर्णांक मान निर्दिष्ट करते समय, किसी को उन्हें उल्टे अल्पविराम में नहीं रखना चाहिए, जो केवल स्ट्रिंग चर के लिए काम करेगा। तो, निर्णायक रूप से एक सरणी उन में संग्रहीत व्युत्पन्न डेटा प्रकारों के साथ परस्पर संबंधित डेटा आइटम का एक संग्रह है।
सरणी में तत्वों का उपयोग कैसे करते हैं?
सरणी में शामिल सभी तत्वों को एक अलग संख्या के साथ सौंपा गया है जो कि उनकी अनुक्रमणिका संख्या है जिसका उपयोग सरणी से किसी तत्व तक पहुंचने के लिए किया जाता है। सूचकांक मान 0 से शुरू होता है और सरणी के आकार से एक कम होता है। बहुत पहले मान का सूचकांक मान 0 है।
उदाहरण:
एक बहुत ही बुनियादी और आसान उदाहरण पर विचार करें जिसमें हम एक सरणी में वेरिएबल्स को इनिशियलाइज़ करेंगे।
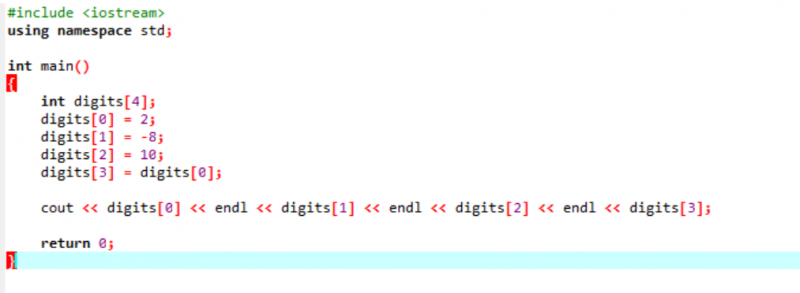
पहले चरण में, हम
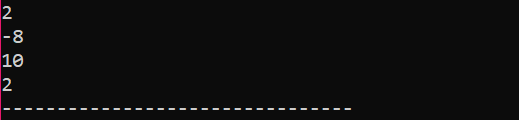
यह उपरोक्त कोड से प्राप्त परिणाम है। 'endl' कीवर्ड अन्य आइटम को स्वचालित रूप से अगली पंक्ति में ले जाता है।
उदाहरण:
इस कोड में, हम किसी ऐरे के आइटम्स को प्रिंट करने के लिए 'फॉर' लूप का उपयोग कर रहे हैं।

उपरोक्त उदाहरण में, हम आवश्यक पुस्तकालय जोड़ रहे हैं। मानक नाम स्थान जोड़ा जा रहा है। मुख्य() फ़ंक्शन वह फ़ंक्शन है जहां हम किसी विशेष कार्यक्रम के निष्पादन के लिए सभी कार्य करने जा रहे हैं। इसके बाद, हम 'Num' नामक एक इंट टाइप ऐरे की घोषणा कर रहे हैं, जिसका आकार 10 है। इन दस वेरिएबल्स का मान उपयोगकर्ता से 'फॉर' लूप के उपयोग से लिया जाता है। इस सरणी के प्रदर्शन के लिए, एक 'फॉर' लूप का फिर से उपयोग किया जाता है। सरणी में संग्रहीत 10 पूर्णांकों को 'cout' कथन की सहायता से प्रदर्शित किया जाता है।
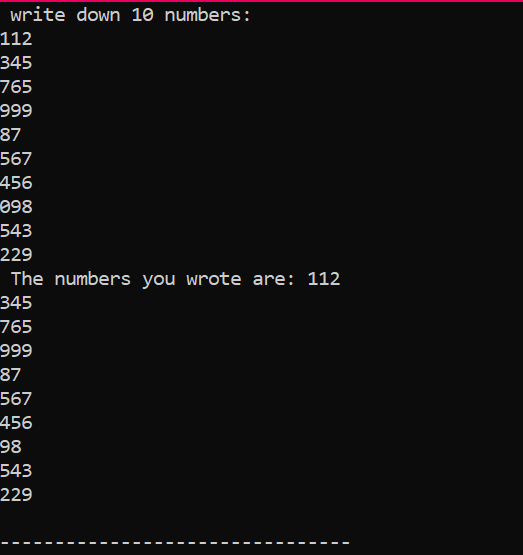
यह वह आउटपुट है जो हमें उपरोक्त कोड के निष्पादन से मिला है, जिसमें अलग-अलग मान वाले 10 पूर्णांक दिखाए गए हैं।
उदाहरण:
इस परिदृश्य में, हम एक छात्र के औसत अंक और कक्षा में उसके द्वारा प्राप्त किए गए प्रतिशत का पता लगाने वाले हैं।
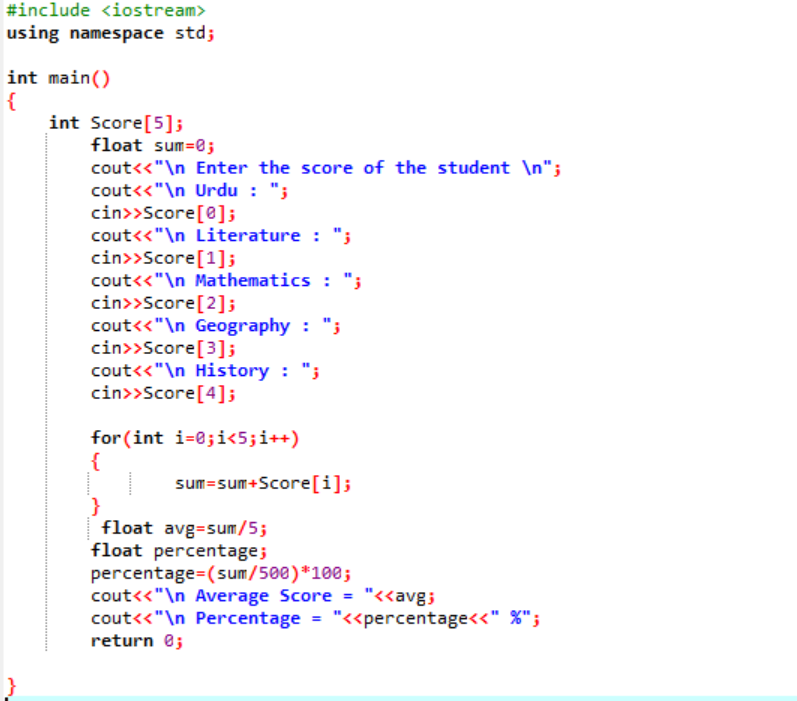
सबसे पहले, आपको एक पुस्तकालय जोड़ने की जरूरत है जो सी ++ प्रोग्राम को प्रारंभिक समर्थन प्रदान करेगा। अगला, हम 'स्कोर' नामक सरणी के आकार 5 को निर्दिष्ट कर रहे हैं। फिर, हमने डेटाटाइप फ्लोट के एक वैरिएबल 'योग' को इनिशियलाइज़ किया। प्रत्येक विषय के अंक उपयोगकर्ता से मैन्युअल रूप से लिए जाते हैं। फिर, शामिल सभी विषयों के औसत और प्रतिशत का पता लगाने के लिए 'फॉर' लूप का उपयोग किया जाता है। सरणी और 'फॉर' लूप का उपयोग करके योग प्राप्त किया जाता है। फिर, औसत के सूत्र का उपयोग करके औसत पाया जाता है। औसत निकालने के बाद, हम इसके मान को प्रतिशत में पास कर रहे हैं जिसे प्रतिशत प्राप्त करने के लिए सूत्र में जोड़ा जाता है। तब औसत और प्रतिशत की गणना और प्रदर्शन किया जाता है।
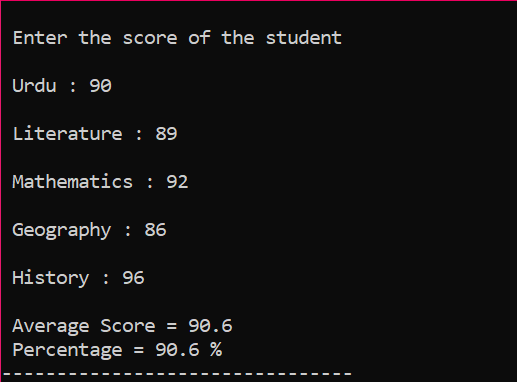
यह अंतिम आउटपुट है जहां प्रत्येक विषय के लिए उपयोगकर्ता से व्यक्तिगत रूप से स्कोर लिया जाता है और औसत और प्रतिशत की गणना क्रमशः की जाती है।
सरणियों का उपयोग करने के लाभ:
- सरणी में आइटम्स को उनके द्वारा निर्दिष्ट इंडेक्स नंबर के कारण एक्सेस करना आसान है।
- हम किसी ऐरे पर आसानी से सर्च ऑपरेशन कर सकते हैं।
- यदि आप प्रोग्रामिंग में जटिलताएं चाहते हैं, तो आप 2-आयामी सरणी का उपयोग कर सकते हैं जो मैट्रिस की विशेषता भी है।
- समान डेटाटाइप वाले कई मानों को संग्रहीत करने के लिए, एक सरणी का आसानी से उपयोग किया जा सकता है।
Arrays का उपयोग करने के नुकसान:
- सरणियों का एक निश्चित आकार होता है।
- Arrays समरूप हैं जिसका अर्थ है कि केवल एक ही प्रकार का मान संग्रहीत किया जाता है।
- Arrays व्यक्तिगत रूप से भौतिक मेमोरी में डेटा संग्रहीत करता है।
- सरणियों के लिए सम्मिलन और विलोपन प्रक्रिया आसान नहीं है।
सी ++ ऑब्जेक्ट्स और क्लासेस:
C++ एक ऑब्जेक्ट-ओरिएंटेड प्रोग्रामिंग लैंग्वेज है, जिसका अर्थ है कि ऑब्जेक्ट C++ में महत्वपूर्ण भूमिका निभाते हैं। वस्तुओं के बारे में बात करते हुए किसी को पहले विचार करना होगा कि वस्तुएं क्या हैं, इसलिए वस्तु वर्ग का कोई भी उदाहरण है। चूंकि सी ++ ओओपी की अवधारणाओं से निपट रहा है, इसलिए चर्चा की जाने वाली प्रमुख चीजें वस्तुएं और वर्ग हैं। कक्षाएं वास्तव में डेटाटाइप हैं जो स्वयं उपयोगकर्ता द्वारा परिभाषित की जाती हैं और डेटा सदस्यों को इनकैप्सुलेट करने के लिए नामित की जाती हैं और ऐसे कार्य जो केवल विशेष वर्ग के लिए सुलभ हैं, बनाए जाते हैं। डेटा सदस्य वे चर हैं जिन्हें कक्षा के अंदर परिभाषित किया गया है।
दूसरे शब्दों में वर्ग एक रूपरेखा या डिज़ाइन है जो डेटा सदस्यों की परिभाषा और घोषणा और उन डेटा सदस्यों को सौंपे गए कार्यों के लिए ज़िम्मेदार है। कक्षा में घोषित प्रत्येक वस्तु वर्ग द्वारा प्रदर्शित सभी विशेषताओं या कार्यों को साझा करने में सक्षम होगी।
मान लीजिए पक्षियों नाम का एक वर्ग है, अब शुरू में सभी पक्षी उड़ सकते थे और पंख लगा सकते थे। इसलिए, उड़ना एक ऐसा व्यवहार है जिसे ये पक्षी अपनाते हैं और पंख उनके शरीर का हिस्सा या एक बुनियादी विशेषता है।
एक वर्ग को परिभाषित करना:
एक वर्ग को परिभाषित करने के लिए, आपको वाक्य रचना पर अनुवर्ती कार्रवाई करनी होगी और इसे अपनी कक्षा के अनुसार रीसेट करना होगा। वर्ग को परिभाषित करने के लिए कीवर्ड 'वर्ग' का उपयोग किया जाता है और अन्य सभी डेटा सदस्यों और कार्यों को वर्ग की परिभाषा के बाद घुंघराले कोष्ठक के अंदर परिभाषित किया जाता है।
कक्षा का नामऑफक्लास
{
एक्सेस स्पेसिफायर :
डेटा सदस्य ;
डेटा सदस्य कार्य ( ) ;
} ;
वस्तुओं की घोषणा:
एक वर्ग को परिभाषित करने के तुरंत बाद, हमें उन कार्यों को एक्सेस करने और परिभाषित करने के लिए ऑब्जेक्ट बनाने की आवश्यकता होती है जो कक्षा द्वारा निर्दिष्ट किए गए थे। उसके लिए हमें क्लास का नाम और फिर डिक्लेरेशन के लिए ऑब्जेक्ट का नाम लिखना होगा।
डेटा सदस्यों तक पहुंचना:
कार्यों और डेटा सदस्यों को एक साधारण बिंदु '।' ऑपरेटर की मदद से एक्सेस किया जाता है। सार्वजनिक डेटा सदस्यों को भी इस ऑपरेटर के साथ एक्सेस किया जाता है, लेकिन निजी डेटा सदस्यों के मामले में, आप उन्हें सीधे एक्सेस नहीं कर सकते। डेटा सदस्यों की पहुंच एक्सेस संशोधक द्वारा उन्हें दिए गए एक्सेस कंट्रोल पर निर्भर करती है जो या तो निजी, सार्वजनिक या संरक्षित हैं। यहां एक परिदृश्य है जो दर्शाता है कि साधारण वर्ग, डेटा सदस्यों और कार्यों को कैसे घोषित किया जाए।
उदाहरण:
इस उदाहरण में, हम कुछ फ़ंक्शंस को परिभाषित करने जा रहे हैं और ऑब्जेक्ट की मदद से क्लास फ़ंक्शंस और डेटा सदस्यों तक पहुँच प्राप्त कर रहे हैं।
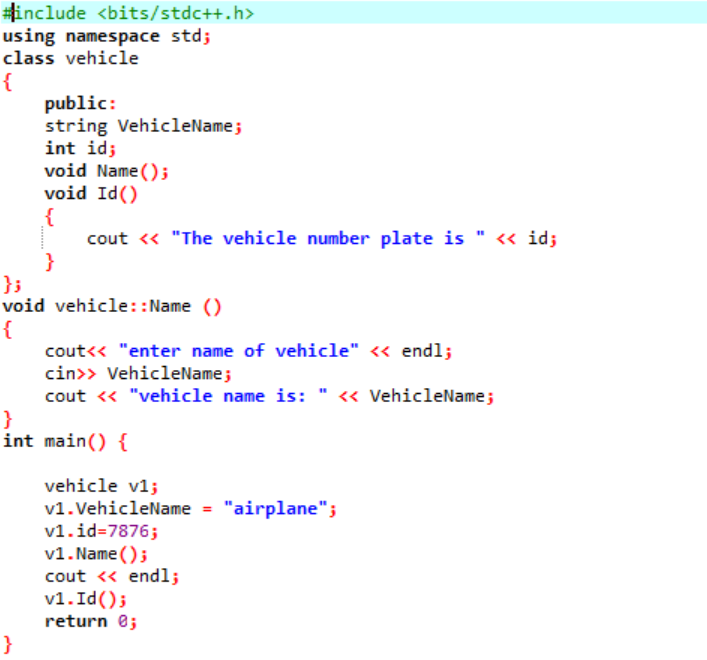
पहले चरण में, हम पुस्तकालय को एकीकृत कर रहे हैं जिसके बाद हमें सहायक निर्देशिकाओं को शामिल करने की आवश्यकता है। कॉल करने से पहले वर्ग को स्पष्ट रूप से परिभाषित किया गया है मुख्य() समारोह। इस वर्ग को 'वाहन' कहा जाता है। डेटा सदस्य वाहन का नाम और उस वाहन की 'आईडी' थे, जो कि उस वाहन के लिए प्लेट नंबर है जिसमें क्रमशः स्ट्रिंग और इंट डेटाटाइप होता है। इन दो डेटा सदस्यों के लिए दो कार्य घोषित किए गए हैं। पहचान() फ़ंक्शन वाहन की आईडी प्रदर्शित करता है। चूंकि कक्षा के डेटा सदस्य सार्वजनिक होते हैं, इसलिए हम उन्हें कक्षा के बाहर भी एक्सेस कर सकते हैं। इसलिए, हम कॉल कर रहे हैं नाम() कक्षा के बाहर कार्य करना और फिर उपयोगकर्ता से 'वाहन नाम' के लिए मूल्य लेना और अगले चरण में इसे प्रिंट करना। में मुख्य() फ़ंक्शन, हम आवश्यक वर्ग की एक वस्तु घोषित कर रहे हैं जो कक्षा से डेटा सदस्यों और कार्यों तक पहुंचने में मदद करेगी। इसके अलावा, हम वाहन के नाम और उसकी आईडी के लिए मानों को केवल तभी प्रारंभ कर रहे हैं, जब उपयोगकर्ता वाहन के नाम के लिए मान नहीं देता है।
यह तब प्राप्त होता है जब उपयोगकर्ता स्वयं वाहन के लिए नाम देता है और नंबर प्लेट इसे निर्दिष्ट स्थिर मान होते हैं।
सदस्य कार्यों की परिभाषा के बारे में बात करते हुए, किसी को यह समझना चाहिए कि कक्षा के अंदर कार्य को परिभाषित करना हमेशा अनिवार्य नहीं होता है। जैसा कि आप उपरोक्त उदाहरण में देख सकते हैं, हम कक्षा के बाहर वर्ग के कार्य को परिभाषित कर रहे हैं क्योंकि डेटा सदस्यों को सार्वजनिक रूप से घोषित किया जाता है और यह '::' के रूप में दिखाए गए स्कोप रिज़ॉल्यूशन ऑपरेटर की मदद से किया जाता है। वर्ग और समारोह का नाम।
सी ++ कंस्ट्रक्टर्स और डिस्ट्रक्टर्स:
हम उदाहरणों की मदद से इस विषय पर पूरी तरह से विचार करने जा रहे हैं। C++ प्रोग्रामिंग में ऑब्जेक्ट को हटाना और बनाना बहुत महत्वपूर्ण है। उसके लिए, जब भी हम किसी वर्ग के लिए एक इंस्टेंस बनाते हैं, तो हम कुछ मामलों में कंस्ट्रक्टर विधियों को स्वचालित रूप से कॉल करते हैं।
निर्माता:
जैसा कि नाम से संकेत मिलता है, एक कंस्ट्रक्टर 'कंस्ट्रक्ट' शब्द से बना है जो किसी चीज के निर्माण को निर्दिष्ट करता है। इसलिए, कंस्ट्रक्टर को नए बनाए गए वर्ग के व्युत्पन्न फ़ंक्शन के रूप में परिभाषित किया जाता है जो वर्ग के नाम को साझा करता है। और इसका उपयोग कक्षा में शामिल वस्तुओं के आरंभीकरण के लिए किया जाता है। इसके अलावा, एक कंस्ट्रक्टर के पास अपने लिए कोई रिटर्न वैल्यू नहीं होता है, जिसका अर्थ है कि इसका रिटर्न टाइप भी शून्य नहीं होगा। तर्कों को स्वीकार करना अनिवार्य नहीं है, लेकिन यदि आवश्यक हो तो कोई उन्हें जोड़ सकता है। कंस्ट्रक्टर एक वर्ग की वस्तु को स्मृति के आवंटन में और सदस्य चर के लिए प्रारंभिक मूल्य निर्धारित करने में उपयोगी होते हैं। ऑब्जेक्ट के इनिशियलाइज़ होने के बाद, प्रारंभिक मान को कंस्ट्रक्टर फ़ंक्शन के तर्कों के रूप में पारित किया जा सकता है।
वाक्य - विन्यास:
NameOfTheClass ( ){
// कंस्ट्रक्टर का शरीर
}
कंस्ट्रक्टर्स के प्रकार:
पैरामीटरयुक्त कंस्ट्रक्टर:
जैसा कि पहले चर्चा की गई है, एक कंस्ट्रक्टर के पास कोई पैरामीटर नहीं होता है, लेकिन कोई अपनी पसंद का एक पैरामीटर जोड़ सकता है। यह ऑब्जेक्ट के मूल्य को इनिशियलाइज़ करेगा जबकि इसे बनाया जा रहा है। इस अवधारणा को बेहतर ढंग से समझने के लिए, निम्नलिखित उदाहरण पर विचार करें:
उदाहरण:
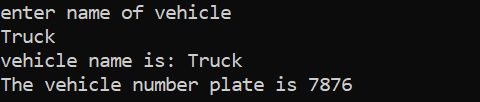
इस उदाहरण में, हम क्लास का कंस्ट्रक्टर बनाएंगे और पैरामीटर घोषित करेंगे।
हम हेडर फ़ाइल को पहले चरण में शामिल कर रहे हैं। नेमस्पेस का उपयोग करने का अगला चरण प्रोग्राम के लिए निर्देशिकाओं का समर्थन कर रहा है। 'अंक' नामक एक वर्ग घोषित किया जाता है, जहां पहले, चर को सार्वजनिक रूप से आरंभीकृत किया जाता है ताकि वे पूरे कार्यक्रम में सुलभ हो सकें। डेटाटाइप पूर्णांक के साथ 'dig1' नामक एक चर घोषित किया गया है। इसके बाद, हमने एक कंस्ट्रक्टर घोषित किया है जिसका नाम क्लास के नाम के समान है। इस कंस्ट्रक्टर के पास एक पूर्णांक चर है जिसे 'n' के रूप में पास किया गया है और वर्ग चर 'dig1' को n के बराबर सेट किया गया है। में मुख्य() कार्यक्रम का कार्य, वर्ग 'अंक' के लिए तीन ऑब्जेक्ट बनाए जाते हैं और कुछ यादृच्छिक मान असाइन किए जाते हैं। इन ऑब्जेक्ट्स का उपयोग तब क्लास वेरिएबल्स को कॉल करने के लिए किया जाता है जिन्हें स्वचालित रूप से समान मानों के साथ असाइन किया जाता है।
पूर्णांक मान स्क्रीन पर आउटपुट के रूप में प्रस्तुत किए जाते हैं।

कॉपी कंस्ट्रक्टर:
यह कंस्ट्रक्टर का प्रकार है जो वस्तुओं को तर्क मानता है और एक वस्तु के डेटा सदस्यों के मूल्यों को दूसरे में दोहराता है। इसलिए, इन कंस्ट्रक्टरों का उपयोग एक वस्तु को दूसरे से घोषित करने और आरंभ करने के लिए किया जाता है। इस प्रक्रिया को कॉपी इनिशियलाइज़ेशन कहा जाता है।
उदाहरण:
इस मामले में, कॉपी कंस्ट्रक्टर घोषित किया जाएगा।

सबसे पहले, हम पुस्तकालय और निर्देशिका को एकीकृत कर रहे हैं। 'नया' नाम का एक वर्ग घोषित किया जाता है जिसमें पूर्णांकों को 'ई' और 'ओ' के रूप में प्रारंभ किया जाता है। कंस्ट्रक्टर को सार्वजनिक किया जाता है जहां दो चरों को मान दिया जाता है और इन चरों को कक्षा में घोषित किया जाता है। फिर, इन मानों को की सहायता से प्रदर्शित किया जाता है मुख्य() रिटर्न प्रकार के रूप में 'int' के साथ कार्य करें। दिखाना() फ़ंक्शन को कॉल किया जाता है और बाद में परिभाषित किया जाता है जहां स्क्रीन पर नंबर प्रदर्शित होते हैं। के अंदर मुख्य() फ़ंक्शन, ऑब्जेक्ट बनाए जाते हैं और इन असाइन किए गए ऑब्जेक्ट को यादृच्छिक मानों के साथ प्रारंभ किया जाता है और फिर दिखाना() पद्धति का प्रयोग किया जाता है।
कॉपी कंस्ट्रक्टर के उपयोग से प्राप्त आउटपुट नीचे दिखाया गया है।

विध्वंसक:
जैसा कि नाम से पता चलता है कि कंस्ट्रक्टर द्वारा बनाई गई वस्तुओं को नष्ट करने के लिए डिस्ट्रक्टर्स का उपयोग किया जाता है। कंस्ट्रक्टर्स की तुलना में, डिस्ट्रक्टर्स का क्लास के समान नाम होता है, लेकिन इसके बाद एक अतिरिक्त टिल्ड (~) होता है।
वाक्य - विन्यास:
~नया ( ){
}
विनाशक किसी भी तर्क में नहीं लेता है और इसका कोई वापसी मूल्य भी नहीं होता है। संकलक स्पष्ट रूप से साफ-सफाई भंडारण के लिए कार्यक्रम से बाहर निकलने की अपील करता है जो अब पहुंच योग्य नहीं है।
उदाहरण:
इस परिदृश्य में, हम किसी वस्तु को हटाने के लिए एक विध्वंसक का उपयोग कर रहे हैं।
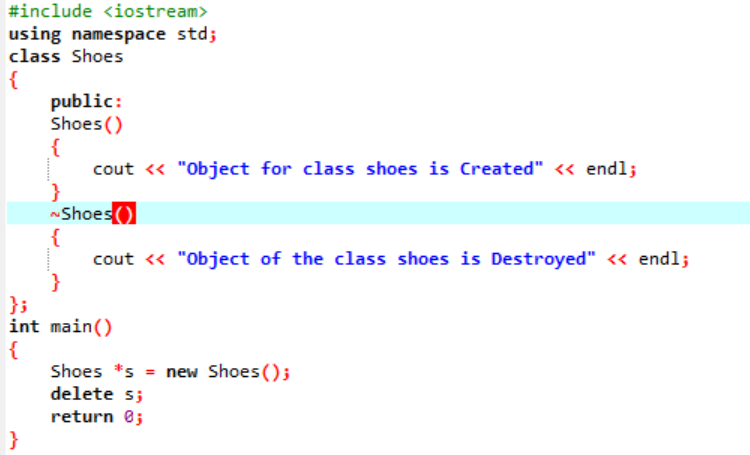
यहां 'जूते' की क्लास बनाई जाती है। एक कंस्ट्रक्टर बनाया जाता है जिसका नाम क्लास के समान होता है। कंस्ट्रक्टर में, एक संदेश प्रदर्शित होता है जहां ऑब्जेक्ट बनाया जाता है। कंस्ट्रक्टर के बाद, डिस्ट्रक्टर बनाया जाता है जो कंस्ट्रक्टर के साथ बनाई गई वस्तुओं को हटा रहा है। में मुख्य() फ़ंक्शन, 's' नाम से एक पॉइंटर ऑब्जेक्ट बनाया जाता है और इस ऑब्जेक्ट को हटाने के लिए एक कीवर्ड 'डिलीट' का उपयोग किया जाता है।

यह वह आउटपुट है जो हमें उस प्रोग्राम से प्राप्त होता है जहाँ डिस्ट्रक्टर बनाई गई वस्तु को साफ़ और नष्ट कर रहा है।
कंस्ट्रक्टर्स और डिस्ट्रक्टर्स के बीच अंतर:
| कंस्ट्रक्टर्स | विध्वंसक |
| कक्षा का उदाहरण बनाता है। | कक्षा के उदाहरण को नष्ट कर देता है। |
| इसमें वर्ग के नाम के साथ तर्क हैं। | इसका कोई तर्क या पैरामीटर नहीं है |
| ऑब्जेक्ट बनने पर कॉल किया जाता है। | ऑब्जेक्ट नष्ट होने पर कॉल किया जाता है। |
| वस्तुओं को स्मृति आवंटित करता है। | वस्तुओं की स्मृति को हटा देता है। |
| अतिभारित किया जा सकता है। | ओवरलोड नहीं किया जा सकता। |
सी ++ विरासत:
अब, हम C++ इनहेरिटेंस और इसके स्कोप के बारे में जानेंगे।
वंशानुक्रम वह तरीका है जिसके माध्यम से एक मौजूदा वर्ग से एक नया वर्ग उत्पन्न या अवरोही होता है। वर्तमान वर्ग को 'आधार वर्ग' या 'मूल वर्ग' भी कहा जाता है और जो नया वर्ग बनाया जाता है उसे 'व्युत्पन्न वर्ग' कहा जाता है। जब हम कहते हैं कि एक बाल वर्ग को मूल वर्ग से विरासत में मिला है, तो इसका मतलब है कि बच्चे के पास मूल वर्ग के सभी गुण हैं।
वंशानुक्रम एक (है) संबंध को संदर्भित करता है। यदि दो वर्गों के बीच 'is-a' का प्रयोग किया जाता है तो हम किसी भी संबंध को वंशानुक्रम कहते हैं।
उदाहरण के लिए:
- तोता एक पक्षी है।
- कंप्यूटर एक मशीन है।
वाक्य - विन्यास:
C++ प्रोग्रामिंग में, हम इनहेरिटेंस का उपयोग या लिखते हैं:
कक्षा < व्युत्पन्न - कक्षा >: < पहुँच - विनिर्देशक >< आधार - कक्षा >सी ++ वंशानुक्रम के तरीके:
इनहेरिटेंस में इनहेरिट क्लासेस के लिए 3 मोड्स शामिल हैं:
- जनता: इस मोड में, यदि एक चाइल्ड क्लास घोषित की जाती है, तो एक पैरेंट क्लास के सदस्यों को चाइल्ड क्लास द्वारा एक पैरेंट क्लास में समान रूप से विरासत में मिला है।
- संरक्षित: मैं इस मोड में, अभिभावक वर्ग के सार्वजनिक सदस्य बाल वर्ग में संरक्षित सदस्य बन जाते हैं।
- निजी : इस मोड में, चाइल्ड क्लास में पैरेंट क्लास के सभी सदस्य प्राइवेट हो जाते हैं।
सी ++ वंशानुक्रम के प्रकार:
C++ इनहेरिटेंस के प्रकार निम्नलिखित हैं:
1. एकल वंशानुक्रम:
इस प्रकार की विरासत के साथ, कक्षाएं एक आधार वर्ग से उत्पन्न हुईं।
वाक्य - विन्यास:
कक्षा एम{
शरीर
} ;
कक्षा संख्या : सार्वजनिक एम
{
शरीर
} ;
2. एकाधिक वंशानुक्रम:
इस प्रकार की विरासत में, एक वर्ग विभिन्न आधार वर्गों से उतर सकता है।
वाक्य - विन्यास:
कक्षा एम{
शरीर
} ;
कक्षा संख्या
{
शरीर
} ;
कक्षा ओ : सार्वजनिक एम , सार्वजनिक संख्या
{
शरीर
} ;
3. बहुस्तरीय विरासत:
इस प्रकार के वंशानुक्रम में एक बाल वर्ग दूसरे बाल वर्ग से उतरा है।
वाक्य - विन्यास:
कक्षा एम{
शरीर
} ;
कक्षा संख्या : सार्वजनिक एम
{
शरीर
} ;
कक्षा ओ : सार्वजनिक संख्या
{
शरीर
} ;
4. पदानुक्रमित विरासत:
वंशानुक्रम की इस पद्धति में एक आधार वर्ग से कई उपवर्ग बनाए जाते हैं।
वाक्य - विन्यास:
कक्षा एम{
शरीर
} ;
कक्षा संख्या : सार्वजनिक एम
{
शरीर
} ;
कक्षा ओ : सार्वजनिक एम
{
} ;
5. हाइब्रिड वंशानुक्रम:
इस तरह की विरासत में, कई विरासत संयुक्त होते हैं।
वाक्य - विन्यास:
कक्षा एम{
शरीर
} ;
कक्षा संख्या : सार्वजनिक एम
{
शरीर
} ;
कक्षा ओ
{
शरीर
} ;
कक्षा पी : सार्वजनिक संख्या , सार्वजनिक ओ
{
शरीर
} ;
उदाहरण:
हम C++ प्रोग्रामिंग में मल्टीपल इनहेरिटेंस की अवधारणा को प्रदर्शित करने के लिए कोड चलाने जा रहे हैं।
जैसा कि हमने एक मानक इनपुट-आउटपुट लाइब्रेरी के साथ शुरुआत की है, तब हमने बेस क्लास को 'बर्ड' नाम दिया है और इसे सार्वजनिक कर दिया है ताकि इसके सदस्यों तक पहुंच हो सके। फिर, हमारे पास बेस क्लास 'सरीसृप' है और हमने इसे सार्वजनिक भी किया है। फिर, हमारे पास आउटपुट प्रिंट करने के लिए 'cout' है। इसके बाद हमने चाइल्ड क्लास 'पेंगुइन' बनाई। में मुख्य() फ़ंक्शन हमने वर्ग पेंगुइन 'p1' का ऑब्जेक्ट बनाया है। सबसे पहले, 'पक्षी' वर्ग निष्पादित करेगा और फिर 'सरीसृप' वर्ग।
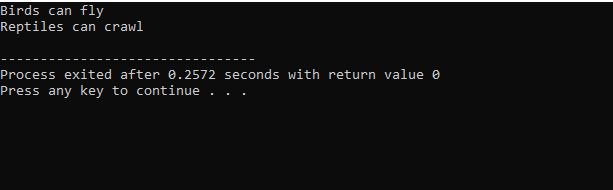
सी ++ में कोड के निष्पादन के बाद, हमें बेस क्लास 'बर्ड' और 'रेप्टाइल' के आउटपुट स्टेटमेंट मिलते हैं। इसका मतलब है कि एक वर्ग 'पेंगुइन' आधार वर्ग 'बर्ड' और 'रेप्टाइल' से लिया गया है क्योंकि पेंगुइन एक पक्षी होने के साथ-साथ एक सरीसृप भी है। यह उड़ भी सकता है और रेंग भी सकता है। इसलिए कई विरासतों ने साबित कर दिया कि एक बाल वर्ग कई आधार वर्गों से प्राप्त किया जा सकता है।
उदाहरण:
यहां हम मल्टीलेवल इनहेरिटेंस का उपयोग करने का तरीका दिखाने के लिए एक प्रोग्राम निष्पादित करेंगे।
हमने इनपुट-आउटपुट स्ट्रीम का उपयोग करके अपना कार्यक्रम शुरू किया। फिर, हमने एक मूल वर्ग 'एम' घोषित किया है जो सार्वजनिक होने के लिए तैयार है। हमने को बुलाया है दिखाना() कथन प्रदर्शित करने के लिए फ़ंक्शन और 'cout' कमांड। इसके बाद, हमने एक चाइल्ड क्लास 'एन' बनाई है जो कि पैरेंट क्लास 'एम' से ली गई है। हमारे पास बाल वर्ग 'एन' से व्युत्पन्न एक नया बाल वर्ग 'ओ' है और दोनों व्युत्पन्न वर्गों का शरीर खाली है। अंत में, हम आह्वान करते हैं मुख्य() फंक्शन जिसमें हमें क्लास 'O' के ऑब्जेक्ट को इनिशियलाइज़ करना होता है। दिखाना() परिणाम प्रदर्शित करने के लिए वस्तु के कार्य का उपयोग किया जाता है।
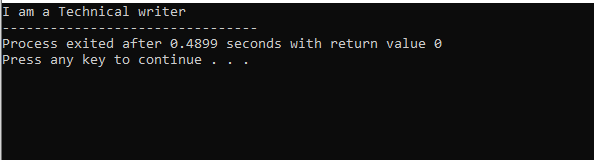
इस आकृति में, हमारे पास वर्ग 'M' का परिणाम है जो मूल वर्ग है क्योंकि हमारे पास a . था दिखाना() इसमें कार्य करते हैं। तो, वर्ग 'एन' मूल वर्ग 'एम' से लिया गया है और कक्षा 'ओ' मूल वर्ग 'एन' से लिया गया है जो बहुस्तरीय विरासत को संदर्भित करता है।
सी ++ बहुरूपता:
'बहुरूपता' शब्द दो शब्दों के संग्रह का प्रतिनिधित्व करता है 'पाली' तथा ' रूपवाद' . 'पॉली' शब्द 'कई' का प्रतिनिधित्व करता है और 'मॉर्फिज्म' 'रूपों' का प्रतिनिधित्व करता है। बहुरूपता का अर्थ है कि एक वस्तु अलग-अलग परिस्थितियों में अलग-अलग व्यवहार कर सकती है। यह एक प्रोग्रामर को कोड का पुन: उपयोग और विस्तार करने की अनुमति देता है। एक ही कोड स्थिति के अनुसार अलग तरह से कार्य करता है। किसी वस्तु के अधिनियमन को रन टाइम पर नियोजित किया जा सकता है।
बहुरूपता की श्रेणियाँ:
बहुरूपता मुख्य रूप से दो तरीकों से होती है:
- संकलन समय बहुरूपता
- रन टाइम बहुरूपता
आइए समझाएं।
6. संकलन समय बहुरूपता:
इस समय के दौरान, दर्ज किए गए प्रोग्राम को एक निष्पादन योग्य प्रोग्राम में बदल दिया जाता है। कोड के परिनियोजन से पहले, त्रुटियों का पता लगाया जाता है। इसकी मुख्य रूप से दो श्रेणियां हैं।
- फंक्शन ओवरलोडिंग
- ऑपरेटर ओवरलोडिंग
आइए देखें कि हम इन दो श्रेणियों का उपयोग कैसे करते हैं।
7. फंक्शन ओवरलोडिंग:
इसका मतलब है कि एक फ़ंक्शन विभिन्न कार्य कर सकता है। फ़ंक्शन को ओवरलोडेड के रूप में जाना जाता है जब समान नाम वाले कई फ़ंक्शन होते हैं लेकिन अलग-अलग तर्क होते हैं।
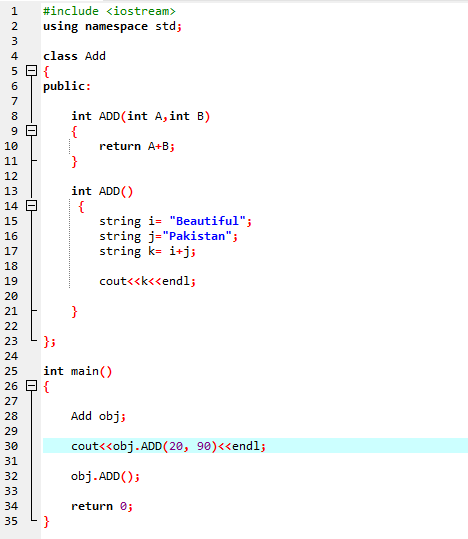
सबसे पहले, हम पुस्तकालय
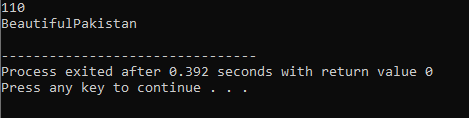
ऑपरेटर ओवरलोडिंग:
एक ऑपरेटर की कई कार्यात्मकताओं को परिभाषित करने की प्रक्रिया को ऑपरेटर ओवरलोडिंग कहा जाता है।
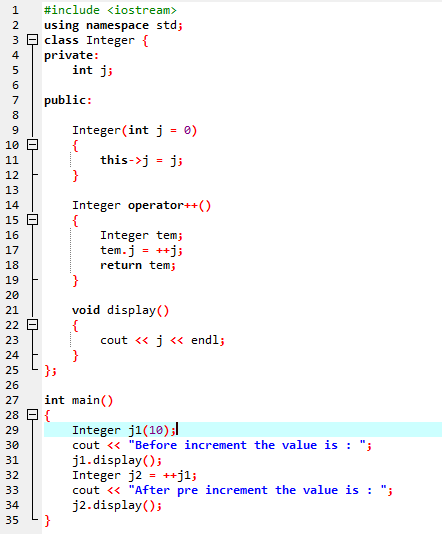
उपरोक्त उदाहरण में हेडर फ़ाइल
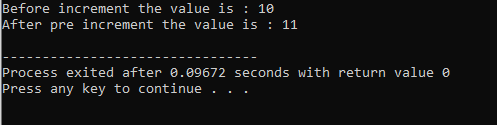
8. रन टाइम बहुरूपता:
यह उस समय की अवधि है जिसमें कोड चलता है। कोड के रोजगार के बाद, त्रुटियों का पता लगाया जा सकता है।
फंक्शन ओवरराइडिंग:
ऐसा तब होता है जब एक व्युत्पन्न वर्ग बेस क्लास सदस्य कार्यों में से एक के समान फ़ंक्शन परिभाषा का उपयोग करता है।
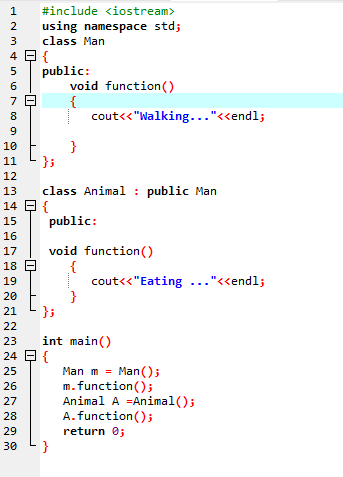
पहली पंक्ति में, हम इनपुट और आउटपुट संचालन को निष्पादित करने के लिए लाइब्रेरी
सी ++ स्ट्रिंग्स:
अब, हम जानेंगे कि C++ में String को कैसे घोषित और इनिशियलाइज़ किया जाता है। स्ट्रिंग का उपयोग प्रोग्राम में वर्णों के समूह को संग्रहीत करने के लिए किया जाता है। यह प्रोग्राम में अक्षरात्मक मान, अंक और विशेष प्रकार के प्रतीकों को संग्रहीत करता है। यह C++ प्रोग्राम में वर्णों को एक सरणी के रूप में आरक्षित करता है। C++ प्रोग्रामिंग में संग्रह या वर्णों के संयोजन को आरक्षित करने के लिए Arrays का उपयोग किया जाता है। अशक्त वर्ण के रूप में जाना जाने वाला एक विशेष प्रतीक सरणी को समाप्त करने के लिए उपयोग किया जाता है। इसे एस्केप सीक्वेंस (\0) द्वारा दर्शाया जाता है और इसका उपयोग स्ट्रिंग के अंत को निर्दिष्ट करने के लिए किया जाता है।
'Cin' कमांड का उपयोग करके स्ट्रिंग प्राप्त करें:
इसका उपयोग बिना किसी रिक्त स्थान के एक स्ट्रिंग वेरिएबल को इनपुट करने के लिए किया जाता है। दिए गए उदाहरण में, हम एक C++ प्रोग्राम लागू करते हैं जो 'cin' कमांड का उपयोग करके उपयोगकर्ता का नाम प्राप्त करता है।
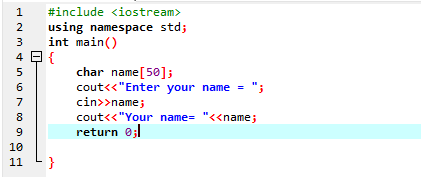
पहले चरण में, हम लाइब्रेरी
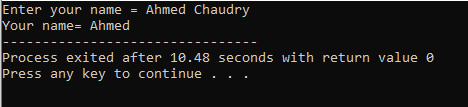
उपयोगकर्ता 'अहमद चौधरी' नाम दर्ज करता है। लेकिन हमें पूर्ण 'अहमद चौधरी' के बजाय आउटपुट के रूप में केवल 'अहमद' मिलता है क्योंकि 'सिन' कमांड रिक्त स्थान के साथ एक स्ट्रिंग को स्टोर नहीं कर सकता है। यह केवल अंतरिक्ष से पहले मूल्य संग्रहीत करता है।
Cin.get() फ़ंक्शन का उपयोग करके स्ट्रिंग प्राप्त करें:
प्राप्त() cin कमांड के फंक्शन का उपयोग कीबोर्ड से स्ट्रिंग प्राप्त करने के लिए किया जाता है जिसमें रिक्त स्थान हो सकते हैं।
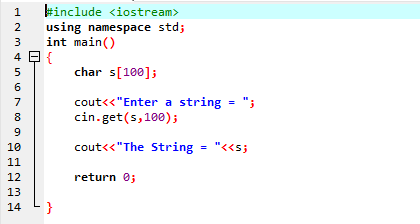
उपरोक्त उदाहरण में इनपुट और आउटपुट संचालन करने के लिए लाइब्रेरी
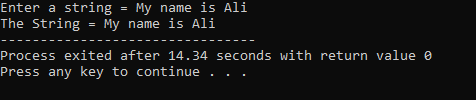
उपयोगकर्ता द्वारा एक स्ट्रिंग 'माई नेम इज अली' दर्ज की जाती है। परिणाम के रूप में हमें पूरा स्ट्रिंग 'माई नेम इज अली' मिलता है क्योंकि cin.get () फ़ंक्शन उन स्ट्रिंग्स को स्वीकार करता है जिनमें रिक्त स्थान होते हैं।
स्ट्रिंग्स के 2डी (दो-आयामी) ऐरे का उपयोग करना:
इस मामले में, हम स्ट्रिंग के 2डी सरणी का उपयोग करके उपयोगकर्ता से इनपुट (तीन शहरों के नाम) लेते हैं।
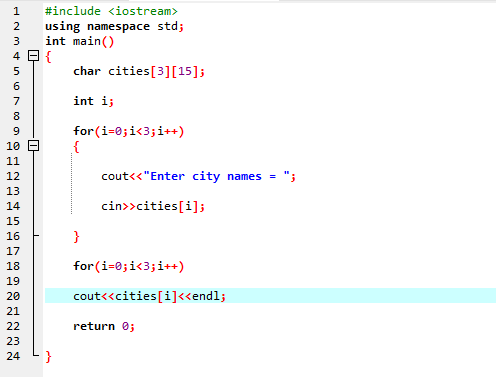
सबसे पहले, हम हेडर फ़ाइल
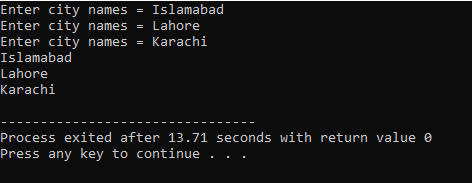
यहां यूजर तीन अलग-अलग शहरों का नाम दर्ज करता है। प्रोग्राम तीन स्ट्रिंग मान प्राप्त करने के लिए एक पंक्ति अनुक्रमणिका का उपयोग करता है। प्रत्येक मान अपनी पंक्ति में रखा जाता है। पहली स्ट्रिंग को पहली पंक्ति में संग्रहीत किया जाता है और इसी तरह। पंक्ति अनुक्रमणिका का उपयोग करके प्रत्येक स्ट्रिंग मान को उसी तरह प्रदर्शित किया जाता है।
सी ++ मानक पुस्तकालय:
सी ++ लाइब्रेरी कई कार्यों, वर्गों, स्थिरांक, और सभी संबंधित वस्तुओं का समूह या समूह है जो लगभग एक उचित सेट में संलग्न है, हमेशा मानकीकृत हेडर फाइलों को परिभाषित और घोषित करता है। इनके कार्यान्वयन में दो नई शीर्षलेख फ़ाइलें शामिल हैं जिन्हें
मानक पुस्तकालय प्रोग्रामिंग करते समय निर्देशों को फिर से लिखने की हलचल को दूर करता है। इसके अंदर कई पुस्तकालय हैं जिन्होंने कई कार्यों के लिए कोड संग्रहीत किया है। इन पुस्तकालयों का अच्छा उपयोग करने के लिए इन्हें हेडर फाइलों की सहायता से जोड़ना अनिवार्य है। जब हम इनपुट या आउटपुट लाइब्रेरी को इम्पोर्ट करते हैं, तो इसका मतलब है कि हम उस लाइब्रेरी के अंदर स्टोर किए गए सभी कोड को इम्पोर्ट कर रहे हैं और इस तरह हम इसमें संलग्न फंक्शन्स का भी उपयोग कर सकते हैं, सभी अंतर्निहित कोड को छिपाकर जिनकी आपको आवश्यकता नहीं हो सकती है देखना।
C++ मानक पुस्तकालय निम्नलिखित दो प्रकारों का समर्थन करता है:
- एक होस्टेड कार्यान्वयन जो सी ++ आईएसओ मानक द्वारा वर्णित सभी आवश्यक मानक लाइब्रेरी हेडर फाइलों का प्रावधान करता है।
- एक स्टैंडअलोन कार्यान्वयन जिसके लिए मानक पुस्तकालय से केवल शीर्षलेख फ़ाइलों के एक हिस्से की आवश्यकता होती है। उपयुक्त उपसमुच्चय है:
| <परमाणु> (कम से कम घोषित करना Atomic_signed_lock_free और atomic-unsigned_lock_free) |
|
<श्रेणियां> |
| <बिट> | |
<अनुपात> |
| |
<अपवाद> | <टुपल> |
| <पहाड़> | <कार्यात्मक> | <टाइपइन्फो> |
| <तुलना> | <प्रारंभकर्ता_सूची> | <स्रोत_स्थान> |
| <अवधारणा> | <पुनरावर्तक> | |
| <कोरआउटिन> | <सीमा> | <उपयोगिता> |
| <नया> |
| |
| |
<स्मृति> | <संस्करण> |
पिछले 11 C++ के आने के बाद से कुछ शीर्षलेख फ़ाइलों की निंदा की गई है: ये हैं
होस्ट किए गए और फ्रीस्टैंडिंग कार्यान्वयन के बीच अंतर नीचे दिखाए गए हैं:
- होस्ट किए गए कार्यान्वयन में, हमें एक वैश्विक फ़ंक्शन का उपयोग करने की आवश्यकता है जो मुख्य कार्य है। एक फ्रीस्टैंडिंग कार्यान्वयन में, उपयोगकर्ता अपने आप ही कार्यों को शुरू करने और समाप्त करने की घोषणा और परिभाषित कर सकता है।
- एक होस्टिंग कार्यान्वयन में मिलान के समय एक थ्रेड अनिवार्य रूप से चल रहा होता है। जबकि, फ्रीस्टैंडिंग कार्यान्वयन में, कार्यान्वयनकर्ता स्वयं तय करेंगे कि उन्हें अपने पुस्तकालय में समवर्ती धागे के समर्थन की आवश्यकता है या नहीं।
प्रकार:
फ्रीस्टैंडिंग और होस्टेड दोनों C++ द्वारा समर्थित हैं। शीर्षलेख फ़ाइलें निम्नलिखित दो में विभाजित हैं:
- आयस्ट्रीम भाग
- सी ++ एसटीएल भागों (मानक पुस्तकालय)
जब भी हम C++ में एक्ज़ीक्यूशन के लिए प्रोग्राम लिख रहे होते हैं, तो हम हमेशा उन फंक्शन्स को कॉल करते हैं जो पहले से ही STL के अंदर लागू होते हैं। ये ज्ञात कार्य दक्षता के साथ पहचाने गए ऑपरेटरों का उपयोग करके इनपुट और डिस्प्ले आउटपुट लेते हैं।
इतिहास को ध्यान में रखते हुए, एसटीएल को शुरू में मानक टेम्पलेट लाइब्रेरी कहा जाता था। फिर, एसटीएल पुस्तकालय के हिस्से को सी ++ के मानक पुस्तकालय में मानकीकृत किया गया था जो आजकल उपयोग किया जाता है। इनमें ISO C++ रनटाइम लाइब्रेरी और कुछ अन्य महत्वपूर्ण कार्यक्षमताओं सहित बूस्ट लाइब्रेरी के कुछ अंश शामिल हैं। कभी-कभी एसटीएल कंटेनर या अधिक बार सी ++ मानक पुस्तकालय के एल्गोरिदम को दर्शाता है। अब, यह एसटीएल या मानक टेम्पलेट लाइब्रेरी पूरी तरह से ज्ञात सी ++ मानक पुस्तकालय के बारे में बात करती है।
एसटीडी नेमस्पेस और हेडर फाइलें:
कार्यों या चरों की सभी घोषणाएं मानक पुस्तकालय के भीतर हेडर फाइलों की सहायता से की जाती हैं जो समान रूप से वितरित की जाती हैं। घोषणा तब तक नहीं होगी जब तक आप हेडर फाइलों को शामिल नहीं करते।
मान लीजिए कि कोई व्यक्ति सूचियों और स्ट्रिंग्स का उपयोग कर रहा है, उसे निम्नलिखित शीर्षलेख फ़ाइलें जोड़ने की आवश्यकता है:
#शामिल करें <स्ट्रिंग>#शामिल करें <सूची>
ये कोणीय कोष्ठक '<>' दर्शाता है कि किसी को इस विशेष हेडर फ़ाइल को परिभाषित और शामिल की जा रही निर्देशिका में देखना चाहिए। कोई भी इस पुस्तकालय में एक '.h' एक्सटेंशन भी जोड़ सकता है जो आवश्यकता या वांछित होने पर किया जाता है। अगर हम '.h' लाइब्रेरी को बाहर करते हैं, तो हमें फ़ाइल के नाम के शुरू होने से ठीक पहले एक अतिरिक्त 'c' की आवश्यकता होती है, जैसे कि यह हेडर फ़ाइल C लाइब्रेरी से संबंधित है। उदाहरण के लिए, आप या तो लिख सकते हैं (#include
नेमस्पेस के बारे में बात करते हुए, संपूर्ण सी ++ मानक पुस्तकालय इस नामस्थान के अंदर है जिसे एसटीडी के रूप में दर्शाया गया है। यही कारण है कि मानकीकृत पुस्तकालय नामों को उपयोगकर्ताओं द्वारा सक्षम रूप से परिभाषित किया जाना चाहिए। उदाहरण के लिए:
कक्षा :: अदालत << 'यह बीत जाएगा !/ एन' ;सी ++ वेक्टर:
C++ में डेटा या वैल्यू को स्टोर करने के कई तरीके हैं। लेकिन अभी के लिए, हम सी ++ भाषा में प्रोग्राम लिखते समय मूल्यों को संग्रहीत करने का सबसे आसान और सबसे लचीला तरीका ढूंढ रहे हैं। तो, वैक्टर कंटेनर होते हैं जिन्हें एक श्रृंखला पैटर्न में ठीक से अनुक्रमित किया जाता है जिसका आकार निष्पादन के समय तत्वों के सम्मिलन और कटौती के आधार पर भिन्न होता है। इसका मतलब है कि प्रोग्राम के निष्पादन के दौरान प्रोग्रामर अपनी इच्छा के अनुसार वेक्टर के आकार को बदल सकता है। वे सरणियों से इस तरह मिलते-जुलते हैं कि उनके शामिल तत्वों के लिए उनके पास संचार योग्य भंडारण स्थान भी हैं। वैक्टर के अंदर मौजूद मूल्यों या तत्वों की संख्या की जाँच के लिए, हमें 'का उपयोग करने की आवश्यकता है' एसटीडी :: गिनती' समारोह। वेक्टर को C++ की मानक टेम्पलेट लाइब्रेरी में शामिल किया गया है, इसलिए इसकी एक निश्चित हेडर फ़ाइल है जिसे पहले शामिल करने की आवश्यकता है:
#शामिल करें <वेक्टर>घोषणा:
वेक्टर की घोषणा नीचे दिखाई गई है।
कक्षा :: वेक्टर < डीटी > नामऑफवेक्टर ;यहां, वेक्टर इस्तेमाल किया जाने वाला कीवर्ड है, डीटी वेक्टर के डेटा प्रकार को दिखा रहा है जिसे इंट, फ्लोट, चार या किसी अन्य संबंधित डेटाटाइप से बदला जा सकता है। उपरोक्त घोषणा को इस प्रकार फिर से लिखा जा सकता है:
वेक्टर < पानी पर तैरना > प्रतिशत ;वेक्टर के लिए आकार निर्दिष्ट नहीं है क्योंकि निष्पादन के दौरान आकार बढ़ या घट सकता है।
वैक्टर की शुरुआत:
वैक्टर के आरंभ के लिए, सी ++ में एक से अधिक तरीके हैं।
तकनीक संख्या 1:
वेक्टर < पूर्णांक > v1 = { 71 , 98 , 3. 4 , 65 } ;वेक्टर < पूर्णांक > वी 2 = { 71 , 98 , 3. 4 , 65 } ;
इस प्रक्रिया में, हम सीधे दोनों वैक्टरों के लिए मान निर्दिष्ट कर रहे हैं। उन दोनों को सौंपे गए मान बिल्कुल समान हैं।
तकनीक संख्या 2:
वेक्टर < पूर्णांक > वी 3 ( 3 , पंद्रह ) ;इस आरंभीकरण प्रक्रिया में, 3 वेक्टर के आकार को निर्धारित कर रहा है और 15 वह डेटा या मान है जो इसमें संग्रहीत किया गया है। 3 के दिए गए आकार के साथ डेटाटाइप 'int' का एक वेक्टर 15 मान को संग्रहीत करता है, जिसका अर्थ है कि वेक्टर 'v3' निम्नलिखित को संग्रहीत कर रहा है:
वेक्टर < पूर्णांक > वी 3 = { पंद्रह , पंद्रह , पंद्रह } ;प्रमुख ऑपरेशन:
वेक्टर क्लास के अंदर वैक्टर पर हम जिन प्रमुख ऑपरेशनों को लागू करने जा रहे हैं, वे हैं:
- एक मूल्य जोड़ना
- एक मूल्य तक पहुंचना
- एक मान बदलना
- एक मान हटाना
जोड़ना और हटाना:
वेक्टर के अंदर तत्वों का जोड़ और विलोपन व्यवस्थित रूप से किया जाता है। ज्यादातर मामलों में, तत्वों को वेक्टर कंटेनरों के परिष्करण पर डाला जाता है लेकिन आप वांछित स्थान पर मान भी जोड़ सकते हैं जो अंततः अन्य तत्वों को उनके नए स्थानों पर स्थानांतरित कर देगा। जबकि, विलोपन में, जब अंतिम स्थिति से मान हटा दिए जाते हैं, तो यह स्वचालित रूप से कंटेनर के आकार को कम कर देगा। लेकिन जब कंटेनर के अंदर के मान किसी विशेष स्थान से बेतरतीब ढंग से हटा दिए जाते हैं, तो नए स्थान अन्य मानों को स्वचालित रूप से असाइन कर दिए जाते हैं।
उपयोग किए गए कार्य:
वेक्टर के अंदर संग्रहीत मूल्यों को बदलने या बदलने के लिए, कुछ पूर्व-निर्धारित कार्य हैं जिन्हें संशोधक के रूप में जाना जाता है। वे इस प्रकार हैं:
- इन्सर्ट (): इसका उपयोग किसी विशेष स्थान पर एक वेक्टर कंटेनर के अंदर एक मूल्य जोड़ने के लिए किया जाता है।
- Erase(): इसका उपयोग किसी विशेष स्थान पर वेक्टर कंटेनर के अंदर किसी मान को हटाने या हटाने के लिए किया जाता है।
- स्वैप (): इसका उपयोग एक वेक्टर कंटेनर के अंदर मूल्यों की अदला-बदली के लिए किया जाता है जो समान डेटा प्रकार से संबंधित होता है।
- असाइन करें (): इसका उपयोग वेक्टर कंटेनर के अंदर पहले से संग्रहीत मूल्य के लिए एक नया मान आवंटित करने के लिए किया जाता है।
- बेगिन (): इसका उपयोग लूप के अंदर एक इटरेटर को वापस करने के लिए किया जाता है जो पहले तत्व के अंदर वेक्टर के पहले मान को संबोधित करता है।
- Clear (): इसका उपयोग वेक्टर कंटेनर के अंदर संग्रहीत सभी मानों को हटाने के लिए किया जाता है।
- Push_back (): इसका उपयोग वेक्टर कंटेनर के परिष्करण पर एक मूल्य जोड़ने के लिए किया जाता है।
- Pop_back (): इसका उपयोग वेक्टर कंटेनर के खत्म होने पर किसी मान को हटाने के लिए किया जाता है।
उदाहरण:
इस उदाहरण में, संशोधक का उपयोग वैक्टर के साथ किया जाता है।
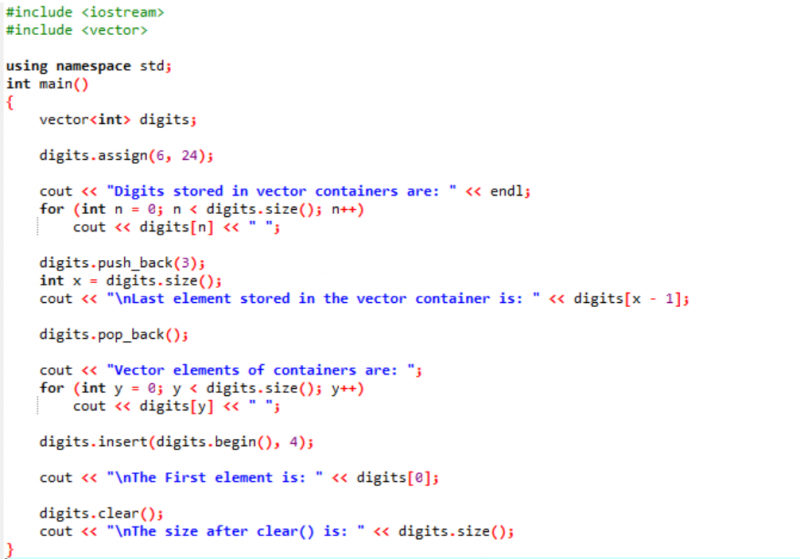
सबसे पहले, हम
आउटपुट नीचे दिखाया गया है।

सी ++ फ़ाइलें इनपुट आउटपुट:
एक फ़ाइल परस्पर संबंधित डेटा का एक संयोजन है। सी ++ में, एक फ़ाइल बाइट्स का एक क्रम है जो कालानुक्रमिक क्रम में एक साथ एकत्र किया जाता है। अधिकांश फाइलें डिस्क के अंदर मौजूद होती हैं। लेकिन हार्डवेयर डिवाइस जैसे चुंबकीय टेप, प्रिंटर और संचार लाइनें भी फाइलों में शामिल हैं।
फाइलों में इनपुट और आउटपुट तीन मुख्य वर्गों की विशेषता है:
- इनपुट लेने के लिए 'आइस्ट्रीम' वर्ग का उपयोग किया जाता है।
- आउटपुट प्रदर्शित करने के लिए 'ओस्ट्रीम' वर्ग कार्यरत है।
- इनपुट और आउटपुट के लिए, 'iostream' वर्ग का उपयोग करें।
फ़ाइलों को सी ++ में स्ट्रीम के रूप में संभाला जाता है। जब हम किसी फाइल या फाइल से इनपुट और आउटपुट ले रहे होते हैं, तो निम्नलिखित क्लासेस का उपयोग किया जाता है:
- ऑफस्ट्रीम: यह एक स्ट्रीम क्लास है जिसका उपयोग फाइल पर लिखने के लिए किया जाता है।
- इफस्ट्रीम: यह एक स्ट्रीम क्लास है जिसका उपयोग किसी फ़ाइल से सामग्री को पढ़ने के लिए किया जाता है।
- धारा: यह एक स्ट्रीम क्लास है जिसका उपयोग फ़ाइल में या फ़ाइल से पढ़ने और लिखने दोनों के लिए किया जाता है।
'इस्ट्रीम' और 'ओस्ट्रीम' वर्ग उन सभी वर्गों के पूर्वज हैं जिनका उल्लेख ऊपर किया गया है। फ़ाइल स्ट्रीम 'सिन' और 'कॉउट' कमांड के रूप में उपयोग करने में आसान हैं, इन फ़ाइल स्ट्रीम को अन्य फाइलों से जोड़ने के अंतर के साथ। आइए 'fstream' वर्ग के बारे में संक्षेप में अध्ययन करने के लिए एक उदाहरण देखें:
उदाहरण:
इस उदाहरण में, हम एक फाइल में डेटा लिख रहे हैं।
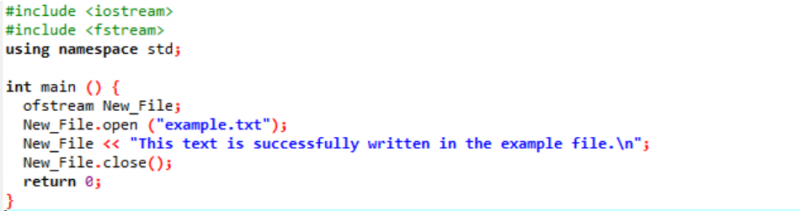
हम पहले चरण में इनपुट और आउटपुट स्ट्रीम को एकीकृत कर रहे हैं। हेडर फ़ाइल

फ़ाइल 'उदाहरण' को पर्सनल कंप्यूटर से खोला जाता है और फ़ाइल पर लिखा गया टेक्स्ट इस टेक्स्ट फ़ाइल पर अंकित होता है जैसा कि ऊपर दिखाया गया है।
एक फ़ाइल खोलना:
जब कोई फ़ाइल खोली जाती है, तो उसे एक स्ट्रीम द्वारा दर्शाया जाता है। फ़ाइल के लिए एक ऑब्जेक्ट बनाया गया है जैसे New_File पिछले उदाहरण में बनाया गया था। स्ट्रीम पर किए गए सभी इनपुट और आउटपुट ऑपरेशन स्वचालित रूप से फ़ाइल पर ही लागू हो जाते हैं। फ़ाइल खोलने के लिए, ओपन () फ़ंक्शन का उपयोग इस प्रकार किया जाता है:
खुला हुआ ( नामऑफ़फ़ाइल , तरीका ) ;यहां, मोड गैर-अनिवार्य है।
फ़ाइल बंद करना:
एक बार जब सभी इनपुट और आउटपुट ऑपरेशन समाप्त हो जाते हैं, तो हमें उस फ़ाइल को बंद करना होगा जो संपादन के लिए खोली गई थी। हमें नियोजित करने की आवश्यकता है a बंद करना() इस स्थिति में कार्य करें।
नई फ़ाइल। बंद करना ( ) ;जब यह किया जाता है, तो फ़ाइल अनुपलब्ध हो जाती है। यदि किसी भी परिस्थिति में वस्तु नष्ट हो जाती है, यहां तक कि फ़ाइल से लिंक होने के बावजूद, विनाशक स्वचालित रूप से बंद () फ़ंक्शन को कॉल करेगा।
पाठ फ़ाइलें:
टेक्स्ट फाइलों का उपयोग टेक्स्ट को स्टोर करने के लिए किया जाता है। इसलिए, यदि पाठ या तो दर्ज किया गया है या प्रदर्शित किया गया है तो इसमें कुछ स्वरूपण परिवर्तन होंगे। टेक्स्ट फ़ाइल के अंदर लेखन कार्य वैसा ही है जैसा हम 'cout' कमांड करते हैं।
उदाहरण:
इस परिदृश्य में, हम उस टेक्स्ट फ़ाइल में डेटा लिख रहे हैं जो पहले से ही पिछले चित्रण में बनाई गई थी।
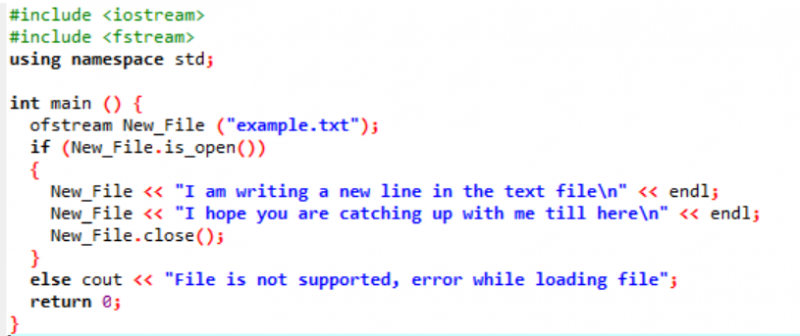
यहां, हम New_File () फ़ंक्शन का उपयोग करके 'उदाहरण' नाम की फ़ाइल में डेटा लिख रहे हैं। हम फ़ाइल 'उदाहरण' का उपयोग करके खोलते हैं खोलना() तरीका। फ़ाइल में डेटा जोड़ने के लिए 'ऑफ़स्ट्रीम' का उपयोग किया जाता है। फाइल के अंदर सारे काम करने के बाद के इस्तेमाल से जरूरी फाइल को बंद कर दिया जाता है बंद करना() समारोह। यदि फ़ाइल नहीं खुलती है तो त्रुटि संदेश 'फ़ाइल समर्थित नहीं है, फ़ाइल लोड करते समय त्रुटि' दिखाई जाती है।

फ़ाइल खुलती है और पाठ कंसोल पर प्रदर्शित होता है।
एक पाठ फ़ाइल पढ़ना:
किसी फ़ाइल का पठन अगले उदाहरण की सहायता से दिखाया गया है।
उदाहरण:
फ़ाइल के अंदर संग्रहीत डेटा को पढ़ने के लिए 'ifstream' का उपयोग किया जाता है।
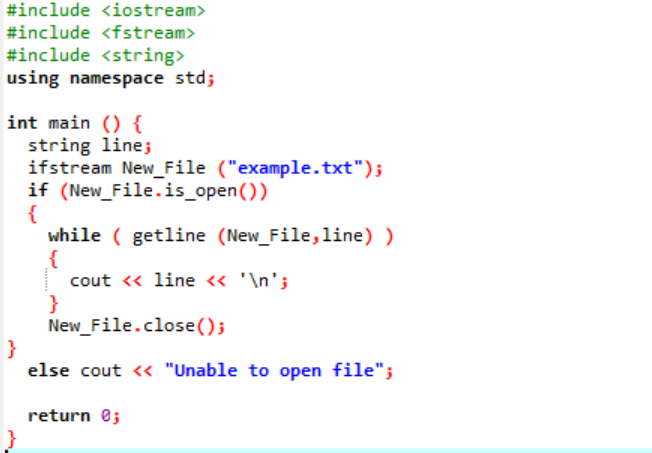
उदाहरण में शुरुआत में प्रमुख हेडर फाइलें
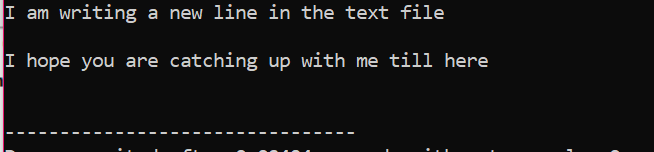
टेक्स्ट फ़ाइल के अंदर संग्रहीत सभी जानकारी स्क्रीन पर दिखाए गए अनुसार प्रदर्शित होती है।
निष्कर्ष
उपरोक्त मार्गदर्शिका में, हमने C++ भाषा के बारे में विस्तार से सीखा है। उदाहरणों के साथ, प्रत्येक विषय का प्रदर्शन और व्याख्या की जाती है, और प्रत्येक क्रिया को विस्तृत किया जाता है।