6.1 परिचय
आधुनिक सामान्य प्रयोजन कंप्यूटर दो प्रकार के होते हैं: सीआईएससी और आरआईएससी। सीआईएससी का मतलब कॉम्प्लेक्स इंस्ट्रक्शन सेट कंप्यूटर है। RISK का मतलब रिड्यूस्ड इंस्ट्रक्शन सेट कंप्यूटर है। 6502 या 6510 माइक्रोप्रोसेसर, जैसा कि कमोडोर-64 कंप्यूटर पर लागू होता है, सीआईएससी आर्किटेक्चर की तुलना में आरआईएससी आर्किटेक्चर से अधिक मिलता जुलता है।
सीआईएससी कंप्यूटरों की तुलना में आरआईएससी कंप्यूटरों में आम तौर पर छोटे असेंबली भाषा निर्देश (बाइट्स की संख्या के अनुसार) होते हैं।
टिप्पणी : चाहे सीआईएससी, आरआईएससी, या पुराने कंप्यूटर से निपटना हो, एक परिधीय एक आंतरिक पोर्ट से शुरू होता है और कंप्यूटर की सिस्टम यूनिट (बेस यूनिट) की ऊर्ध्वाधर सतह पर एक बाहरी पोर्ट के माध्यम से बाहरी डिवाइस तक जाता है।
सीआईएससी कंप्यूटर के एक विशिष्ट निर्देश को कई छोटे असेंबली भाषा निर्देशों को एक लंबे असेंबली भाषा निर्देश में जोड़ने के रूप में देखा जा सकता है जो परिणामी निर्देश को जटिल बनाता है। विशेष रूप से, एक सीआईएससी कंप्यूटर ऑपरेंड को मेमोरी से माइक्रोप्रोसेसर रजिस्टरों में लोड करता है, एक ऑपरेशन करता है, और फिर परिणाम को एक निर्देश में वापस मेमोरी में संग्रहीत करता है। दूसरी ओर, यह आरआईएससी कंप्यूटर के लिए कम से कम तीन निर्देश (संक्षिप्त) हैं।
सीआईएससी कंप्यूटरों की दो लोकप्रिय श्रृंखलाएं हैं: इंटेल माइक्रोप्रोसेसर कंप्यूटर और एएमडी माइक्रोप्रोसेसर कंप्यूटर। AMD का मतलब एडवांस्ड माइक्रो डिवाइसेस है; यह एक सेमीकंडक्टर निर्माण कंपनी है। इंटेल माइक्रोप्रोसेसर श्रृंखला, विकास के क्रम में, 8086, 8088, 80186, 80286, 80386, 80486, पेंटियम, कोर, आई सीरीज, सेलेरॉन और ज़ीऑन हैं। प्रारंभिक इंटेल माइक्रोप्रोसेसरों जैसे 8086 और 8088 के लिए असेंबली भाषा निर्देश बहुत जटिल नहीं हैं। हालाँकि, वे नए माइक्रोप्रोसेसरों के लिए जटिल हैं। CISC श्रृंखला के लिए हालिया AMD माइक्रोप्रोसेसर Ryzen, Opteron, Athlon, Turion, Phenom, और Sempron हैं। इंटेल और एएमडी माइक्रोप्रोसेसरों को x86 माइक्रोप्रोसेसर के रूप में जाना जाता है।
एआरएम का मतलब एडवांस्ड आरआईएससी मशीन है। एआरएम आर्किटेक्चर आरआईएससी प्रोसेसर के एक परिवार को परिभाषित करते हैं जो विभिन्न प्रकार के अनुप्रयोगों में उपयोग के लिए उपयुक्त हैं। जबकि कई इंटेल और एएमडी माइक्रोप्रोसेसर डेस्कटॉप पर्सनल कंप्यूटर में उपयोग किए जाते हैं, कई एआरएम प्रोसेसर ऑटोमोटिव एंटी-लॉक ब्रेक जैसे सुरक्षा-महत्वपूर्ण सिस्टम में एम्बेडेड प्रोसेसर के रूप में और स्मार्टवॉच, पोर्टेबल फोन, टैबलेट और लैपटॉप कंप्यूटर में सामान्य प्रयोजन प्रोसेसर के रूप में काम करते हैं। . हालाँकि दोनों प्रकार के माइक्रोप्रोसेसर छोटे और बड़े उपकरणों में देखे जा सकते हैं, आरआईएससी माइक्रोप्रोसेसर बड़े उपकरणों की तुलना में छोटे उपकरणों में अधिक पाए जाते हैं।
कंप्यूटर शब्द
यदि किसी कंप्यूटर को 32 बिट वर्ड का कंप्यूटर कहा जाता है, तो इसका मतलब है कि जानकारी को मदरबोर्ड के आंतरिक भाग के भीतर बत्तीस-बिट बाइनरी कोड के रूप में संग्रहीत, स्थानांतरित और हेरफेर किया जाता है। इसका मतलब यह भी है कि कंप्यूटर के माइक्रोप्रोसेसर में सामान्य प्रयोजन रजिस्टर 32-बिट चौड़े होते हैं। 6502 माइक्रोप्रोसेसर के ए, एक्स और वाई रजिस्टर सामान्य प्रयोजन रजिस्टर हैं। वे आठ-बिट चौड़े हैं, और इसलिए कमोडोर-64 कंप्यूटर एक आठ-बिट वर्ड कंप्यूटर है।
कुछ शब्दावली
X86 कंप्यूटर
x86 कंप्यूटर के लिए बाइट, वर्ड, डबलवर्ड, क्वाडवर्ड और डबल-क्वाडवर्ड के अर्थ इस प्रकार हैं:
- बाइट : 8 बिट्स
- शब्द : 16 बिट्स
- दोहरा शब्द : 32 बिट्स
- क्वाडवर्ड : 64 बिट्स
- दोहरा चतुर्शब्द : 128 बिट्स
एआरएम कंप्यूटर
एआरएम कंप्यूटरों के लिए बाइट, हाफवर्ड, वर्ड और डबलवर्ड के अर्थ इस प्रकार हैं:
- बाइट : 8 बिट्स
- आधा हो जाओ : 16 बिट्स
- शब्द : 32 बिट्स
- दोहरा शब्द : 64 बिट्स
x86 और ARM नाम (और मान) के अंतर और समानता पर ध्यान दिया जाना चाहिए।
टिप्पणी : दोनों कंप्यूटर प्रकारों में चिह्न पूर्णांक दो के पूरक हैं।
स्मृति स्थान
कमोडोर-64 कंप्यूटर के साथ, एक मेमोरी लोकेशन आमतौर पर एक बाइट होती है लेकिन पॉइंटर्स (अप्रत्यक्ष एड्रेसिंग) पर विचार करते समय कभी-कभी दो लगातार बाइट्स हो सकती हैं। एक आधुनिक x86 कंप्यूटर के साथ, 16 बाइट्स (128 बिट्स) के डबल क्वाडवर्ड के साथ काम करते समय मेमोरी लोकेशन 16 लगातार बाइट्स होती है, 8 बाइट्स (64 बिट्स) के क्वाडवर्ड के साथ काम करते समय लगातार 8 बाइट्स, डबलवर्ड के साथ काम करते समय लगातार 4 बाइट्स होती है। 4 बाइट्स (32 बिट्स), 2 बाइट्स (16 बिट्स) के एक शब्द के साथ काम करते समय 2 लगातार बाइट्स, और एक बाइट (8 बिट्स) के साथ काम करते समय 1 बाइट। एक आधुनिक एआरएम कंप्यूटर के साथ, एक मेमोरी लोकेशन 8 बाइट्स (64 बिट्स) के डबलवर्ड के साथ काम करते समय लगातार 8 बाइट्स, 4 बाइट्स (32 बिट्स) के एक शब्द के साथ काम करते समय लगातार 4 बाइट्स, आधे शब्द के साथ काम करते समय लगातार 2 बाइट्स होती है। 2 बाइट्स (16 बिट्स) और एक बाइट (8 बिट्स) के साथ काम करते समय 1 बाइट।
यह अध्याय बताता है कि सीआईएससी और आरआईएससी आर्किटेक्चर में क्या आम है और उनके अंतर क्या हैं। यह 6502 µP और कमोडोर-64 कंप्यूटर की तुलना में किया जाता है जहां यह लागू है।
6.2 आधुनिक पीसी का मदरबोर्ड ब्लॉक आरेख
पीसी का मतलब पर्सनल कंप्यूटर है। निम्नलिखित एक पर्सनल कंप्यूटर के लिए एकल माइक्रोप्रोसेसर वाले आधुनिक मदरबोर्ड के लिए एक सामान्य बुनियादी ब्लॉक आरेख है। यह CISC या RISC मदरबोर्ड का प्रतिनिधित्व करता है।
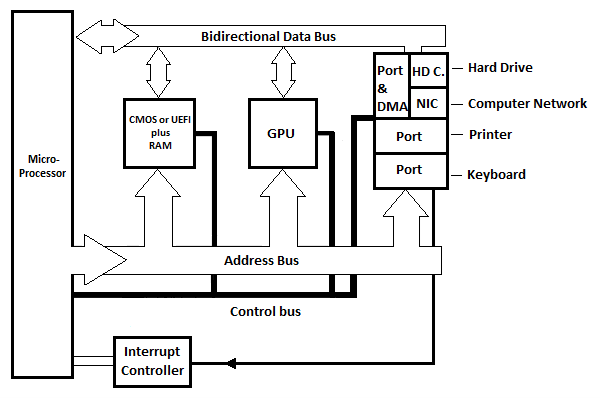
चित्र 6.21 आधुनिक पीसी का बेसिक मदरबोर्ड ब्लॉक आरेख
चित्र में तीन आंतरिक पोर्ट दिखाए गए हैं, लेकिन व्यवहार में और भी हैं। प्रत्येक पोर्ट में एक रजिस्टर होता है जिसे पोर्ट के रूप में ही देखा जा सकता है। प्रत्येक पोर्ट सर्किट में कम से कम एक अन्य रजिस्टर होता है जिसे 'स्टेटस रजिस्टर' कहा जा सकता है। स्थिति रजिस्टर उस प्रोग्राम के पोर्ट को इंगित करता है जो माइक्रोप्रोसेसर को इंटरप्ट सिग्नल भेज रहा है। एक इंटरप्ट कंट्रोलर सर्किट है (दिखाया नहीं गया) जो अलग-अलग पोर्ट से अलग-अलग इंटरप्ट लाइनों के बीच अंतर करता है और इसमें µP की कुछ ही लाइनें होती हैं।
चित्र में HD.C का मतलब हार्ड ड्राइव कार्ड है। एनआईसी का मतलब नेटवर्क इंटरफ़ेस कार्ड है। हार्ड ड्राइव कार्ड (सर्किट) हार्ड ड्राइव से जुड़ा होता है जो आधुनिक कंप्यूटर की बेस यूनिट (सिस्टम यूनिट) के अंदर होता है। नेटवर्क इंटरफ़ेस कार्ड (सर्किट) एक बाहरी केबल के माध्यम से दूसरे कंप्यूटर से जुड़ा होता है। आरेख में, एक पोर्ट और एक डीएमए (निम्नलिखित चित्रण देखें) है जो हार्ड डिस्क कार्ड और/या नेटवर्क इंटरफ़ेस कार्ड से जुड़े हुए हैं। डीएमए का मतलब डायरेक्ट मेमोरी एक्सेस है।
कमोडोर-64 कंप्यूटर अध्याय से याद रखें कि मेमोरी से बाइट्स को डिस्क ड्राइव या किसी अन्य कंप्यूटर पर भेजने के लिए, प्रत्येक बाइट को संबंधित आंतरिक पोर्ट पर कॉपी करने से पहले माइक्रोप्रोसेसर में एक रजिस्टर में कॉपी करना होगा, और फिर स्वचालित रूप से डिवाइस के लिए. डिस्क ड्राइव या किसी अन्य कंप्यूटर से मेमोरी में बाइट्स प्राप्त करने के लिए, प्रत्येक बाइट को मेमोरी में कॉपी करने से पहले संबंधित आंतरिक पोर्ट रजिस्टर से माइक्रोप्रोसेसर रजिस्टर में कॉपी करना होगा। यदि स्ट्रीम में बाइट्स की संख्या बड़ी है तो इसमें आम तौर पर लंबा समय लगता है। तेजी से स्थानांतरण का समाधान माइक्रोप्रोसेसर से गुजरे बिना डायरेक्ट मेमोरी एक्सेस (सर्किट) का उपयोग है।
डीएमए सर्किट पोर्ट और एचडी के बीच है। सी या एनआईसी. डीएमए सर्किट की सीधी मेमोरी एक्सेस के साथ, माइक्रोप्रोसेसर की निरंतर भागीदारी के बिना बाइट्स की बड़ी धाराओं का स्थानांतरण सीधे डीएमए सर्किट और मेमोरी (रैम) के बीच होता है। डीएमए μP के स्थान पर एड्रेस बस और डेटा बस का उपयोग करता है। स्थानांतरण की कुल अवधि µP हार्ड का उपयोग करने की तुलना में कम है। एचडी सी या एनआईसी दोनों डीएमए का उपयोग करते हैं जब उनके पास रैम (मेमोरी) के साथ स्थानांतरण के लिए डेटा (बाइट्स) की एक बड़ी स्ट्रीम होती है।
GPU का मतलब ग्राफ़िक्स प्रोसेसिंग यूनिट है। मदरबोर्ड पर यह ब्लॉक टेक्स्ट और चलती या स्थिर छवियों को स्क्रीन पर भेजने के लिए जिम्मेदार है।
आधुनिक कंप्यूटरों (पीसी) में कोई रीड ओनली मेमोरी (रोम) नहीं होती है। हालाँकि, BIOS या UEFI है जो एक प्रकार की गैर-वाष्पशील रैम है। BIOS में जानकारी वास्तव में एक बैटरी द्वारा बनाए रखी जाती है। बैटरी वास्तव में कंप्यूटर के लिए सही समय और तारीख पर घड़ी के टाइमर को भी बनाए रखती है। UEFI का आविष्कार BIOS के बाद हुआ था, और इसने BIOS का स्थान ले लिया है, हालाँकि आधुनिक पीसी में BIOS अभी भी काफी प्रासंगिक है। हम इन पर बाद में अधिक चर्चा करेंगे!
आधुनिक पीसी में, μP और आंतरिक पोर्ट सर्किट (और मेमोरी) के बीच पता और डेटा बसें समानांतर बसें नहीं हैं। वे सीरियल बसें हैं जिन्हें एक दिशा में ट्रांसमिशन के लिए दो कंडक्टरों की आवश्यकता होती है और विपरीत दिशा में ट्रांसमिशन के लिए अन्य दो कंडक्टरों की आवश्यकता होती है। इसका मतलब है, उदाहरण के लिए, 32-बिट्स को किसी भी दिशा में श्रृंखला में (एक के बाद एक बिट) भेजा जा सकता है।
यदि सीरियल ट्रांसमिशन केवल दो कंडक्टरों (दो लाइनों) के साथ एक दिशा में होता है, तो इसे आधा-डुप्लेक्स कहा जाता है। यदि सीरियल ट्रांसमिशन दोनों दिशाओं में चार कंडक्टरों के साथ होता है, दोनों दिशाओं में एक जोड़ी, तो इसे पूर्ण-डुप्लेक्स कहा जाता है।
आधुनिक कंप्यूटर की संपूर्ण मेमोरी में अभी भी बाइट स्थानों की एक श्रृंखला होती है: प्रति बाइट आठ-बिट। एक आधुनिक कंप्यूटर में कम से कम 4 गीगा बाइट्स = 4 x 210 x 2 का मेमोरी स्पेस होता है 10 एक्स 2 10 = 4 x 1,073,741,824 10 बाइट्स = 4 x 1024 10/उप> x 1024 10 x 1024 10 = 4 x 1,073,741,824 10 .
टिप्पणी : हालाँकि पिछले मदरबोर्ड पर कोई टाइमर सर्किट नहीं दिखाया गया है, सभी आधुनिक मदरबोर्ड में टाइमर सर्किट होते हैं।
6.3 x64 कंप्यूटर आर्किटेक्चर मूल बातें
6.31 x64 रजिस्टर सेट
माइक्रोप्रोसेसरों की x86 श्रृंखला का 64-बिट माइक्रोप्रोसेसर एक 64-बिट माइक्रोप्रोसेसर है। यह उसी सीरीज के 32-बिट प्रोसेसर को रिप्लेस करने के लिए काफी आधुनिक है। 64-बिट माइक्रोप्रोसेसर के सामान्य प्रयोजन रजिस्टर और उनके नाम इस प्रकार हैं:
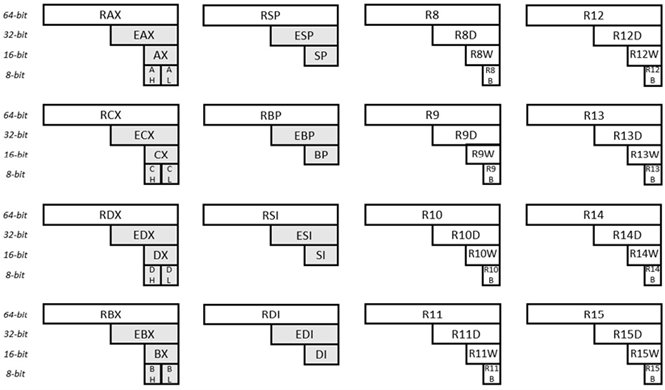
चित्र: 6.31 x64 के लिए सामान्य प्रयोजन रजिस्टर
दिए गए चित्रण में सोलह (16) सामान्य प्रयोजन रजिस्टर दिखाए गए हैं। इनमें से प्रत्येक रजिस्टर 64-बिट चौड़ा है। ऊपरी-बाएँ कोने पर रजिस्टर को देखने पर, 64 बिट्स को RAX के रूप में पहचाना जाता है। इसी रजिस्टर के पहले 32 बिट्स (दाएं से) को EAX के रूप में पहचाना जाता है। इसी रजिस्टर के पहले 16 बिट्स (दाएं से) AX के रूप में पहचाने जाते हैं। इसी रजिस्टर के दूसरे बाइट (दाएं से) को एएच (यहां एच का मतलब उच्च है) के रूप में पहचाना जाता है। और पहली बाइट (इसी रजिस्टर की) को AL के रूप में पहचाना जाता है (यहां L का अर्थ कम है)। निचले-दाएँ कोने पर रजिस्टर को देखने पर, 64 बिट्स की पहचान R15 के रूप में की जाती है। इसी रजिस्टर के पहले 32 बिट्स को R15D के रूप में पहचाना जाता है। इसी रजिस्टर के पहले 16 बिट्स को R15W के रूप में पहचाना जाता है। और पहली बाइट की पहचान R15B के रूप में की गई है। अन्य रजिस्टरों (और उप रजिस्टरों) के नाम भी इसी तरह समझाए गए हैं।
Intel और AMD µPs के बीच कुछ अंतर हैं। इस अनुभाग में दी गई जानकारी Intel के लिए है.
6502 µP के साथ, प्रोग्राम काउंटर रजिस्टर (सीधे पहुंच योग्य नहीं) जिसमें निष्पादित होने वाला अगला निर्देश 16-बिट चौड़ा है। यहां (x64), प्रोग्राम काउंटर को इंस्ट्रक्शन पॉइंटर कहा जाता है, और यह 64-बिट चौड़ा है। इसे RIP के रूप में लेबल किया गया है। इसका मतलब यह है कि x64 μP 264 = 1.844674407 x 1019 (वास्तव में 18,446,744,073,709,551,616) मेमोरी बाइट स्थानों को संबोधित कर सकता है। आरआईपी एक सामान्य प्रयोजन रजिस्टर नहीं है।
स्टैक पॉइंटर रजिस्टर या आरएसपी 16 सामान्य प्रयोजन रजिस्टरों में से एक है। यह मेमोरी में अंतिम स्टैक प्रविष्टि की ओर इशारा करता है। 6502 µP की तरह, x64 के लिए स्टैक नीचे की ओर बढ़ता है। x64 के साथ, रैम में स्टैक का उपयोग सबरूटीन्स के रिटर्न एड्रेस को स्टोर करने के लिए किया जाता है। इसका उपयोग 'छाया स्थान' को संग्रहीत करने के लिए भी किया जाता है (निम्नलिखित चर्चा देखें)।
6502 µP में 8-बिट प्रोसेसर स्टेटस रजिस्टर है। x64 में समतुल्य को RFLAGS रजिस्टर कहा जाता है। यह रजिस्टर उन झंडों को संग्रहीत करता है जिनका उपयोग संचालन के परिणामों और प्रोसेसर (μP) को नियंत्रित करने के लिए किया जाता है। यह 64-बिट चौड़ा है। उच्चतर 32 बिट आरक्षित हैं और वर्तमान में उपयोग नहीं किए जाते हैं। निम्न तालिका RFLAGS रजिस्टर में आमतौर पर उपयोग किए जाने वाले बिट्स के नाम, सूचकांक और अर्थ देती है:
| तालिका 6.31.1 सर्वाधिक उपयोग किए जाने वाले आरएफएलएजीएस झंडे (बिट्स) |
|||
|---|---|---|---|
| प्रतीक | अंश | नाम | उद्देश्य |
| सीएफ़ | 0 | ढोना | यह सेट किया जाता है यदि कोई अंकगणितीय ऑपरेशन परिणाम के सबसे महत्वपूर्ण बिट से कैरी या उधार उत्पन्न करता है; अन्यथा साफ़ कर दिया गया। यह ध्वज अहस्ताक्षरित-पूर्णांक अंकगणित के लिए एक अतिप्रवाह स्थिति को इंगित करता है। इसका उपयोग बहु-परिशुद्धता अंकगणित में भी किया जाता है। |
| पीएफ | 2 | समानता | यह तब सेट किया जाता है जब परिणाम के सबसे कम-महत्वपूर्ण बाइट में 1 बिट की सम संख्या होती है; अन्यथा साफ़ कर दिया गया। |
| का | 4 | समायोजित करना | यह तब सेट किया जाता है जब एक अंकगणितीय ऑपरेशन परिणाम के बिट 3 में से एक कैरी या उधार उत्पन्न करता है; अन्यथा साफ़ कर दिया गया। इस ध्वज का उपयोग बाइनरी-कोडेड दशमलव (बीसीडी) अंकगणित में किया जाता है। |
| जेडएफ | 6 | शून्य | यदि परिणाम शून्य है तो इसे सेट किया जाता है; अन्यथा साफ़ कर दिया गया। |
| एस एफ | 7 | संकेत | इसे तब सेट किया जाता है जब यह परिणाम के सबसे महत्वपूर्ण बिट के बराबर होता है जो एक हस्ताक्षरित पूर्णांक का साइन बिट होता है (0 एक सकारात्मक मान इंगित करता है और 1 एक नकारात्मक मान इंगित करता है)। |
| का | ग्यारह | बाढ़ | यह सेट किया जाता है यदि पूर्णांक परिणाम गंतव्य ऑपरेंड में फिट होने के लिए बहुत बड़ी सकारात्मक संख्या या बहुत छोटी नकारात्मक संख्या (साइन-बिट को छोड़कर) है; अन्यथा साफ़ कर दिया गया। यह ध्वज हस्ताक्षरित-पूर्णांक (दो के पूरक) अंकगणित के लिए एक अतिप्रवाह स्थिति को इंगित करता है। |
| डीएफ | 10 | दिशा | यदि दिशा स्ट्रिंग निर्देश संचालित होते हैं (वृद्धि या कमी) तो इसे सेट किया जाता है। |
| पहचान | इक्कीस | पहचान | इसे सेट किया जाता है यदि इसकी परिवर्तनशीलता सीपीयूआईडी निर्देश की उपस्थिति को दर्शाती है। |
पहले बताए गए अठारह 64-बिट रजिस्टरों के अलावा, x64 आर्किटेक्चर µP में फ्लोटिंग पॉइंट अंकगणित के लिए आठ 80-बिट चौड़े रजिस्टर हैं। इन आठ रजिस्टरों का उपयोग एमएमएक्स रजिस्टरों के रूप में भी किया जा सकता है (निम्नलिखित चर्चा देखें)। एक्सएमएम के लिए सोलह 128-बिट रजिस्टर भी हैं (निम्नलिखित चर्चा देखें)।
यह सब रजिस्टरों के बारे में नहीं है। अधिक x64 रजिस्टर हैं जो खंड रजिस्टर हैं (ज्यादातर x64 में अप्रयुक्त), नियंत्रण रजिस्टर, मेमोरी प्रबंधन रजिस्टर, डिबग रजिस्टर, वर्चुअलाइजेशन रजिस्टर, प्रदर्शन रजिस्टर जो सभी प्रकार के आंतरिक मापदंडों (कैश हिट/मिस, माइक्रो-ऑप्स निष्पादित, समय) को ट्रैक करते हैं , और भी बहुत कुछ)।
SIMD
SIMD का मतलब सिंगल इंस्ट्रक्शन मल्टीपल डेटा है। इसका मतलब यह है कि एक असेंबली भाषा निर्देश एक माइक्रोप्रोसेसर में एक ही समय में कई डेटा पर कार्य कर सकता है। निम्नलिखित तालिका पर विचार करें:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | |
| + | 9 | 10 | ग्यारह | 12 | 13 | 14 | पंद्रह | 16 |
| = | 10 | 12 | 14 | 16 | 18 | बीस | 22 | 24 |
इस तालिका में, आठ उत्तर देने के लिए संख्याओं के आठ जोड़े समानांतर (समान अवधि में) जोड़े जाते हैं। एक असेंबली भाषा निर्देश एमएमएक्स रजिस्टरों में आठ समानांतर पूर्णांक जोड़ सकता है। इसी तरह का काम एक्सएमएम रजिस्टरों के साथ भी किया जा सकता है। तो, पूर्णांकों के लिए एमएमएक्स निर्देश और फ्लोट्स के लिए एक्सएमएम निर्देश हैं।
6.32 मेमोरी मैप और x64
इंस्ट्रक्शन पॉइंटर (प्रोग्राम काउंटर) में 64 बिट्स होने का मतलब है कि 264 = 1.844674407 x 1019 मेमोरी बाइट स्थानों को संबोधित किया जा सकता है। हेक्साडेसिमल में, उच्चतम बाइट स्थान FFFF,FFFF,FFFF,FFFF16 है। आज कोई भी साधारण कंप्यूटर इतनी बड़ी मेमोरी (संपूर्ण) स्थान प्रदान नहीं कर सकता है। तो, x64 कंप्यूटर के लिए एक उपयुक्त मेमोरी मैप इस प्रकार है:

ध्यान दें कि 0000,8000,0000,000016 से FFFF,7FFF,FFFF,FFFF16 तक के अंतर में कोई मेमोरी स्थान नहीं है (कोई मेमोरी रैम बैंक नहीं)। यह FFFF,0000,0000,000116 का अंतर है जो काफी बड़ा है। कैनोनिकल उच्च आधे में ऑपरेटिंग सिस्टम होता है, जबकि कैनोनिकल निचले आधे में उपयोगकर्ता प्रोग्राम (एप्लिकेशन) और डेटा होता है। ऑपरेटिंग सिस्टम में दो भाग होते हैं: एक छोटा UEFI (BIOS) और एक बड़ा भाग जो हार्ड ड्राइव से लोड किया जाता है। अगला अध्याय आधुनिक ऑपरेटिंग सिस्टम के बारे में अधिक बात करता है। इस मेमोरी मैप और कमोडोर-64 के लिए समानता पर ध्यान दें, जब 64KB बहुत अधिक मेमोरी की तरह दिखता होगा।
इस संदर्भ में, ऑपरेटिंग सिस्टम को मोटे तौर पर 'कर्नेल' कहा जाता है। कर्नेल कमोडोर-64 कंप्यूटर के कर्नेल के समान है, लेकिन इसमें कहीं अधिक सबरूटीन हैं।
x64 के लिए एंडियननेस थोड़ा एंडियन है, जिसका अर्थ है कि किसी स्थान के लिए, निचला पता मेमोरी में कम सामग्री बाइट को इंगित करता है।
6.33 x64 के लिए असेंबली लैंग्वेज एड्रेसिंग मोड
एड्रेसिंग मोड वे तरीके हैं जिनसे एक निर्देश µP रजिस्टरों और मेमोरी (आंतरिक पोर्ट रजिस्टरों सहित) तक पहुंच सकता है। x64 में कई एड्रेसिंग मोड हैं, लेकिन यहां केवल आमतौर पर उपयोग किए जाने वाले एड्रेसिंग मोड को ही संबोधित किया गया है। यहां एक निर्देश के लिए सामान्य वाक्यविन्यास है:
ऑपकोड गंतव्य, स्रोत
दशमलव संख्याएँ बिना किसी उपसर्ग या प्रत्यय के लिखी जाती हैं। 6502 के साथ, स्रोत अंतर्निहित है। x64 में 6502 की तुलना में अधिक ऑप-कोड हैं, लेकिन कुछ ऑपकोड में समान निमोनिक्स हैं। व्यक्तिगत x64 निर्देश अलग-अलग लंबाई के होते हैं और इनका आकार 1 से 15 बाइट्स तक हो सकता है। आमतौर पर उपयोग किए जाने वाले एड्रेसिंग मोड इस प्रकार हैं:
तत्काल संबोधन मोड
यहां, स्रोत ऑपरेंड एक वास्तविक मान है न कि कोई पता या लेबल। उदाहरण (टिप्पणी पढ़ें):
EAX जोड़ें, 14 ; 64-बिट RAX के 32-बिट EAX में दशमलव 14 जोड़ें, उत्तर EAX (गंतव्य) में रहता है
एड्रेसिंग मोड रजिस्टर करने के लिए रजिस्टर करें
उदाहरण:
R8B, AL जोड़ें; 64-बिट R8 के R8B में RAX का 8-बिट AL जोड़ें - उत्तर R8B (गंतव्य) में ही रहता है
अप्रत्यक्ष और अनुक्रमित एड्रेसिंग मोड
6502 µP के साथ अप्रत्यक्ष संबोधन का अर्थ है कि निर्देश में दिए गए पते के स्थान में अंतिम स्थान का प्रभावी पता (सूचक) है। x64 के साथ भी कुछ ऐसा ही होता है। 6502 µP के साथ इंडेक्स एड्रेसिंग का मतलब है कि प्रभावी पते के लिए µP रजिस्टर की सामग्री को निर्देश में दिए गए पते पर जोड़ा गया है। x64 के साथ भी कुछ ऐसा ही होता है। साथ ही, x64 के साथ, रजिस्टर की सामग्री को दिए गए पते पर जोड़े जाने से पहले 1 या 2 या 4 या 8 से गुणा भी किया जा सकता है। x64 का mov (कॉपी) निर्देश अप्रत्यक्ष और अनुक्रमित एड्रेसिंग दोनों को जोड़ सकता है। उदाहरण:
MOV R8W, 1234[8*RAX+RCX] ; शब्द को पते (8 x RAX + RCX) + 1234 पर ले जाएँ
यहां, R8W में R8 के पहले 16-बिट हैं। दिया गया पता 1234 है। RAX रजिस्टर में 64-बिट संख्या है जिसे 8 से गुणा किया जाता है। परिणाम 64-बिट RCX रजिस्टर की सामग्री में जोड़ा जाता है। प्रभावी पता प्राप्त करने के लिए यह दूसरा परिणाम दिए गए पते में जोड़ा जाता है जो 1234 है। प्रभावी पते के स्थान की संख्या को R8 रजिस्टर के पहले 16-बिट स्थान (R8W) में स्थानांतरित (कॉपी) किया जाता है, जो कुछ भी वहां था उसे प्रतिस्थापित कर दिया जाता है। वर्गाकार कोष्ठकों के उपयोग पर ध्यान दें। याद रखें कि x64 में एक शब्द 16-बिट चौड़ा है।
आरआईपी सापेक्ष संबोधन
6502 µP के लिए, सापेक्ष संबोधन का उपयोग केवल शाखा निर्देशों के साथ किया जाता है। वहां, ऑपकोड का एकल ऑपरेंड एक ऑफसेट है जिसे प्रभावी निर्देश पते (डेटा पते नहीं) के लिए प्रोग्राम काउंटर की सामग्री में जोड़ा या घटाया जाता है। ऐसी ही बात x64 के साथ होती है जहां प्रोग्राम काउंटर को इंस्ट्रक्शन पॉइंटर कहा जाता है। x64 के साथ निर्देश का केवल एक शाखा निर्देश होना आवश्यक नहीं है। RIP-सापेक्ष संबोधन का एक उदाहरण है:
मूव एएल, [आरआईपी]
RAX के AL में एक 8-बिट हस्ताक्षरित संख्या होती है जिसे अगले निर्देश को इंगित करने के लिए RIP (64-बिट इंस्ट्रक्शन पॉइंटर) में सामग्री से जोड़ा या घटाया जाता है। ध्यान दें कि इस निर्देश में स्रोत और गंतव्य की विशेष रूप से अदला-बदली की गई है। वर्गाकार कोष्ठकों के उपयोग पर भी ध्यान दें जो RIP की सामग्री को संदर्भित करते हैं।
6.34 x64 के सामान्य रूप से प्रयुक्त निर्देश
निम्नलिखित तालिका में * का अर्थ ऑपकोड के सबसेट के विभिन्न संभावित प्रत्ययों से है:
| तालिका 6.34.1 x64 में आम तौर पर प्रयुक्त निर्देश |
|
|---|---|
| ऑपकोड | अर्थ |
| MOV | मेमोरी और रजिस्टरों के बीच/से/में ले जाएँ (कॉपी करें)। |
| सीएमओवी* | विभिन्न सशर्त चालें |
| XCHG | अदला-बदली |
| बीएसडब्ल्यूएपी | बाइट स्वैप |
| पुश पॉप | ढेर का उपयोग |
| जोड़ें/एडीसी | जोड़ें/ले जाने के साथ |
| उप/एसबीसी | घटाना/कैरी के साथ |
| एमयूएल/आईएमयूएल | गुणा/अहस्ताक्षरित |
| डीआईवी/आईडीआईवी | विभाजित/अहस्ताक्षरित |
| इंक/डीईसी | वृद्धि/कमी |
| एनईजी | निगेट |
| सीएमपी | तुलना करना |
| और/या/XOR/नहीं | बिटवाइज़ संचालन |
| SHR/SAR | तार्किक/अंकगणित को दाईं ओर शिफ्ट करें |
| एसएचएल/एसएएल | तार्किक/अंकगणित को बाईं ओर शिफ्ट करें |
| आरओआर/भूमिका | दाएं/बाएं घुमाएं |
| आरसीआर/आरसीएल | कैरी बिट के माध्यम से दाएं/बाएं घुमाएं |
| बीटी/बीटीएस/बीटीआर | बिट परीक्षण/और सेट/और रीसेट |
| जेएमपी | बिना शर्त छलांग |
| जेई/जेएनई/जेसी/जेएनसी/जे* | कूदें यदि बराबर/बराबर नहीं/ले जाएं/नहीं ले जाएं/कई अन्य |
| चलना/चलना/चलना | ECX के साथ लूप |
| कॉल/रिट करें | सबरूटीन/रिटर्न पर कॉल करें |
| एनओपी | कोई ऑपरेशन नहीं |
| सीपीयूआईडी | सीपीयू जानकारी |
x64 में गुणा और भाग निर्देश हैं। इसके μP में गुणन और विभाजन हार्डवेयर सर्किट हैं। 6502 µP में गुणन और विभाजन हार्डवेयर सर्किट नहीं हैं। सॉफ़्टवेयर की तुलना में हार्डवेयर द्वारा गुणा और भाग करना तेज़ है (बिट्स की शिफ्टिंग सहित)।
स्ट्रिंग निर्देश
कई स्ट्रिंग निर्देश हैं, लेकिन यहां चर्चा की जाने वाली एकमात्र चीज़ MOVS (स्ट्रिंग को स्थानांतरित करने के लिए) निर्देश है जो पते C000 से शुरू होने वाली स्ट्रिंग को कॉपी करने के लिए है। एच . पते C100 से प्रारंभ करें एच , निम्नलिखित निर्देश का उपयोग करें:
MOVS [C100H], [C000H]
हेक्साडेसिमल के लिए प्रत्यय H पर ध्यान दें।
6.35 x64 में लूपिंग
6502 µP में लूपिंग के लिए शाखा निर्देश हैं। एक शाखा अनुदेश उस पते वाले स्थान पर पहुंच जाता है जिसमें नया अनुदेश होता है। पता स्थान को 'लूप' कहा जा सकता है। x64 में लूपिंग के लिए LOOP/LOOPE/LOOPNE निर्देश हैं। इन आरक्षित असेंबली भाषा के शब्दों को 'लूप' लेबल (उद्धरण के बिना) के साथ भ्रमित नहीं किया जाना चाहिए। व्यवहार इस प्रकार है:
LOOP ECX को घटाता है और जाँचता है कि ECX शून्य तो नहीं है। यदि वह शर्त (शून्य) पूरी हो जाती है, तो यह एक निर्दिष्ट लेबल पर पहुंच जाता है। अन्यथा, यह विफल हो जाता है (निम्नलिखित चर्चा में शेष निर्देशों के साथ जारी रखें)।
LOOPE ECX को घटाता है और जांचता है कि ECX शून्य नहीं है (उदाहरण के लिए 1 हो सकता है) और ZF सेट है (1 पर)। यदि ये शर्तें पूरी हो जाती हैं, तो यह लेबल पर पहुंच जाता है। अन्यथा, यह गिर जाता है.
LOOPNE ECX को घटाता है और जांचता है कि ECX शून्य नहीं है और ZF सेट नहीं है (यानी, शून्य हो)। यदि ये शर्तें पूरी हो जाती हैं, तो यह लेबल पर पहुंच जाता है। अन्यथा, यह गिर जाता है.
x64 के साथ, RCX रजिस्टर या इसके उप भाग जैसे ECX या CX, काउंटर पूर्णांक रखता है। लूप निर्देशों के साथ, काउंटर आम तौर पर उलटी गिनती करता है, प्रत्येक जंप (लूप) के लिए 1 की कमी करता है। निम्नलिखित लूपिंग कोड सेगमेंट में, EAX रजिस्टर में संख्या दस पुनरावृत्तियों में 0 से बढ़कर 10 हो जाती है, जबकि ECX में संख्या 10 गुना कम हो जाती है (टिप्पणियाँ पढ़ें):
MOV EAX, 0 ;
एमओवी ईसीएक्स, 10 ; डिफ़ॉल्ट रूप से 10 बार उलटी गिनती करें, प्रत्येक पुनरावृत्ति के लिए एक बार
लेबल:
इंक EAX ; लूप बॉडी के रूप में EAX बढ़ाएँ
लूप लेबल; EAX घटाएं, और यदि EAX शून्य नहीं है, तो 'लेबल:' से लूप बॉडी को फिर से निष्पादित करें
लूप कोडिंग 'लेबल:' से शुरू होती है। कोलन के उपयोग पर ध्यान दें. लूप कोडिंग 'LOOP लेबल' के साथ समाप्त होती है जो डिक्रीमेंट EAX कहता है। यदि इसकी सामग्री शून्य नहीं है, तो 'लेबल:' के बाद निर्देश पर वापस जाएं और 'लूप लेबल' तक नीचे आने वाले किसी भी निर्देश (सभी मुख्य निर्देश) को दोबारा निष्पादित करें। ध्यान दें कि 'लेबल' का अभी भी दूसरा नाम हो सकता है।
6.36 x64 का इनपुट/आउटपुट
अध्याय का यह खंड डेटा को आउटपुट (आंतरिक) पोर्ट पर भेजने या इनपुट (आंतरिक) पोर्ट से डेटा प्राप्त करने से संबंधित है। चिपसेट में आठ-बिट पोर्ट हैं। किसी भी दो लगातार 8-बिट पोर्ट को 16-बिट पोर्ट के रूप में माना जा सकता है, और किसी भी चार लगातार पोर्ट को 32-बिट पोर्ट के रूप में माना जा सकता है। इस तरीके से, प्रोसेसर किसी बाहरी डिवाइस से 8, 16 या 32 बिट्स स्थानांतरित कर सकता है।
जानकारी को प्रोसेसर और आंतरिक पोर्ट के बीच दो तरीकों से स्थानांतरित किया जा सकता है: मेमोरी-मैप्ड इनपुट/आउटपुट के रूप में जाना जाने वाला उपयोग करके या एक अलग इनपुट/आउटपुट एड्रेस स्पेस का उपयोग करके। मेमोरी-मैप्ड I/O वैसा ही है जैसा 6502 प्रोसेसर के साथ होता है जहां पोर्ट पते वास्तव में संपूर्ण मेमोरी स्पेस का हिस्सा होते हैं। इस मामले में, किसी विशेष पते वाले स्थान पर डेटा भेजते समय, यह एक पोर्ट पर जाता है, न कि मेमोरी बैंक में। बंदरगाहों में एक अलग I/O पता स्थान हो सकता है। इस बाद वाले मामले में, सभी मेमोरी बैंकों के पते शून्य से हैं। 0000H से FFFF16 तक एक अलग पता सीमा है। इनका उपयोग चिपसेट में पोर्ट द्वारा किया जाता है। मदरबोर्ड को मेमोरी-मैप्ड I/O और अलग I/O एड्रेस स्पेस के बीच भ्रमित न होने के लिए प्रोग्राम किया गया है।
मेमोरी-मैप्ड I/O
इसके साथ, पोर्ट को मेमोरी लोकेशन के रूप में माना जाता है, और मेमोरी और µP के बीच उपयोग किए जाने वाले सामान्य ऑपकोड का उपयोग µP और पोर्ट के बीच डेटा ट्रांसफर के लिए किया जाता है। तो, पते F000H पर एक पोर्ट से µP रजिस्टर RAX:EAX:AX:AL पर एक बाइट को स्थानांतरित करने के लिए, निम्न कार्य करें:
मूव अल, [F000H]
एक स्ट्रिंग को मेमोरी से पोर्ट पर ले जाया जा सकता है और इसके विपरीत भी। उदाहरण:
MOVS [F000H], [C000H] ; स्रोत C000H है, और गंतव्य F000H पर पोर्ट है।
अलग I/O पता स्थान
इसके साथ इनपुट और आउटपुट के लिए विशेष निर्देशों का उपयोग करना पड़ता है।
एकल आइटम स्थानांतरित करना
स्थानांतरण के लिए प्रोसेसर रजिस्टर RAX है। दरअसल, यह डबलवर्ड के लिए RAX:EAX, वर्ड के लिए RAX:EAX:AX और बाइट के लिए RAX:EAX:AX:AL है। तो, FFF0h पर एक पोर्ट से RAX:EAX:AX:AL पर एक बाइट स्थानांतरित करने के लिए, निम्न टाइप करें:
अल में, [FFF0H]
रिवर्स ट्रांसफर के लिए, निम्नलिखित टाइप करें:
आउट [एफएफएफ0एच], एएल
इसलिए, एकल आइटम के लिए, निर्देश IN और OUT हैं। पोर्ट एड्रेस RDX:EDX:DX रजिस्टर में भी दिया जा सकता है।
स्ट्रिंग्स स्थानांतरित करना
एक स्ट्रिंग को मेमोरी से चिपसेट पोर्ट में स्थानांतरित किया जा सकता है और इसके विपरीत। FFF0H पते वाले पोर्ट से स्ट्रिंग को मेमोरी में स्थानांतरित करने के लिए, C100H से शुरू करें, टाइप करें:
आईएनएस [ईएसआई], [डीएक्स]
जिसका प्रभाव वैसा ही है:
आईएनएस [ईडीआई], [डीएक्स]
प्रोग्रामर को FFF0H का दो-बाइट पोर्ट पता RDX:EDX:Dx रजिस्टर में डालना चाहिए, और C100H का दो-बाइट पता RSI:ESI या RDI:EDI रजिस्टर में डालना चाहिए। रिवर्स ट्रांसफर के लिए, निम्नलिखित कार्य करें:
आईएनएस [डीएक्स], [ईएसआई]
जिसका प्रभाव वैसा ही है:
आईएनएस [डीएक्स], [ईडीआई]
6.37 x64 में स्टैक
6502 प्रोसेसर की तरह, x64 प्रोसेसर में भी रैम का ढेर होता है। x64 के लिए स्टैक 2 हो सकता है 16 = 65,536 बाइट्स लंबा या यह 2 हो सकता है 32 = 4,294,967,296 बाइट्स लंबा। यह नीचे की ओर भी बढ़ता है। जब किसी रजिस्टर की सामग्री को स्टैक पर धकेला जाता है, तो आरएसपी स्टैक पॉइंटर में संख्या 8 से कम हो जाती है। याद रखें कि x64 के लिए मेमोरी एड्रेस 64 बिट चौड़ा है। µP में स्टैक पॉइंटर का मान RAM में स्टैक में अगले स्थान की ओर इशारा करता है। जब एक रजिस्टर की सामग्री (या एक ऑपरेंड में एक मान) को स्टैक से एक रजिस्टर में पॉप किया जाता है, तो आरएसपी स्टैक पॉइंटर में संख्या 8 बढ़ जाती है। ऑपरेटिंग सिस्टम स्टैक का आकार तय करता है और यह रैम में कहां से शुरू होता है और नीचे की ओर बढ़ता है. याद रखें कि स्टैक एक लास्ट-इन-फर्स्ट-आउट (LIFO) संरचना है जो इस मामले में नीचे की ओर बढ़ती है और ऊपर की ओर सिकुड़ती है।
µP RBX रजिस्टर की सामग्री को स्टैक पर पुश करने के लिए, निम्न कार्य करें:
पुश आरबीएक्स
स्टैक में अंतिम प्रविष्टि को वापस RBX पर पॉप करने के लिए, निम्न कार्य करें:
पॉप आरबीएक्स
6.38 x64 में प्रक्रिया
x64 में सबरूटीन को 'प्रक्रिया' कहा जाता है। यहां स्टैक का उपयोग 6502 µP के लिए उपयोग किए जाने से अधिक किया जाता है। x64 प्रक्रिया के लिए सिंटैक्स है:
proc_name:
प्रक्रिया निकाय
…
सही
जारी रखने से पहले, ध्यान दें कि x64 सबरूटीन (सामान्य रूप से असेंबली भाषा निर्देश) के लिए ऑपकोड और लेबल केस असंवेदनशील हैं। अर्थात proc_name PROC_NAME के समान है। 6502 की तरह, प्रक्रिया नाम (लेबल) का नाम असेंबली भाषा के लिए टेक्स्ट एडिटर में एक नई लाइन की शुरुआत में शुरू होता है। इसके बाद 6502 की तरह स्पेस और ऑपकोड नहीं बल्कि एक कोलन होता है। सबरूटीन बॉडी आरईटी के साथ समाप्त होती है और 6502 μP की तरह आरटीएस नहीं। 6502 की तरह, आरईटी सहित शरीर में प्रत्येक निर्देश, इसकी पंक्ति की शुरुआत में शुरू नहीं होता है। ध्यान दें कि यहां एक लेबल 8 अक्षरों से अधिक लंबा हो सकता है। इस प्रक्रिया को कॉल करने के लिए, टाइप की गई प्रक्रिया के ऊपर या नीचे से, निम्नलिखित कार्य करें:
Proc_name पर कॉल करें
6502 के साथ, लेबल का नाम केवल कॉलिंग के लिए टाइप है। हालाँकि, यहाँ, आरक्षित शब्द 'CALL' या 'कॉल' टाइप किया गया है, जिसके बाद एक स्थान के बाद प्रक्रिया का नाम (सबरूटीन) लिखा गया है।
प्रक्रियाओं से निपटते समय, आमतौर पर दो प्रक्रियाएं होती हैं। एक प्रक्रिया दूसरे को कॉल करती है. वह प्रक्रिया जो कॉल करती है (जिसमें कॉल निर्देश होता है) उसे 'कॉलर' कहा जाता है, और जिस प्रक्रिया को कॉल किया जाता है उसे 'कैली' कहा जाता है। पालन करने के लिए एक सम्मेलन (नियम) है।
कॉल करने वाले के नियम
सबरूटीन लागू करते समय कॉल करने वाले को निम्नलिखित नियमों का पालन करना चाहिए:
1. सबरूटीन को कॉल करने से पहले, कॉल करने वाले को कुछ रजिस्टरों की सामग्री को सहेजना चाहिए जिन्हें स्टैक में कॉलर-सेव के रूप में नामित किया गया है। कॉलर द्वारा सहेजे गए रजिस्टर R10, R11 और कोई भी रजिस्टर हैं जिनमें पैरामीटर डाले गए हैं (RDI, RSI, RDX, RCX, R8, R9)। यदि इन रजिस्टरों की सामग्री को सबरूटीन कॉल में संरक्षित किया जाना है, तो उन्हें रैम में सहेजने के बजाय स्टैक पर पुश करें। ऐसा इसलिए किया जाना चाहिए क्योंकि पिछली सामग्री को मिटाने के लिए कैली द्वारा रजिस्टरों का उपयोग किया जाना है।
2. उदाहरण के लिए, यदि प्रक्रिया दो संख्याओं को जोड़ने की है, तो दो संख्याएँ स्टैक में पारित किए जाने वाले पैरामीटर हैं। सबरूटीन में पैरामीटर पास करने के लिए, उनमें से छह को निम्नलिखित रजिस्टरों में क्रम से डालें: आरडीआई, आरएसआई, आरडीएक्स, आरसीएक्स, आर8, आर9। यदि सबरूटीन में छह से अधिक पैरामीटर हैं, तो बाकी को रिवर्स ऑर्डर में स्टैक पर पुश करें (यानी, अंतिम पैरामीटर पहले)। चूंकि स्टैक नीचे बढ़ता है, अतिरिक्त पैरामीटर में से पहला (वास्तव में सातवां पैरामीटर) सबसे कम पते पर संग्रहीत किया जाता है (पैरामीटर का यह व्युत्क्रम ऐतिहासिक रूप से फ़ंक्शन (सबरूटीन) को पैरामीटर की एक चर संख्या के साथ पारित करने की अनुमति देने के लिए उपयोग किया जाता था)।
3. सबरूटीन (प्रक्रिया) को कॉल करने के लिए, कॉल निर्देश का उपयोग करें। यह निर्देश रिटर्न एड्रेस को स्टैक (निम्नतम स्थिति) पर पैरामीटर के शीर्ष पर और शाखाओं को सबरूटीन कोड पर रखता है।
4. सबरूटीन के वापस आने के बाद (अर्थात कॉल निर्देश के तुरंत बाद), कॉल करने वाले को स्टैक से कोई भी अतिरिक्त पैरामीटर (रजिस्टरों में संग्रहीत छह के अलावा) को हटाना होगा। यह कॉल निष्पादित होने से पहले स्टैक को उसकी स्थिति में पुनर्स्थापित करता है।
5. कॉल करने वाला RAX रजिस्टर में सबरूटीन का रिटर्न वैल्यू (पता) ढूंढने की उम्मीद कर सकता है।
6. कॉलर, कॉल करने वाले द्वारा सहेजे गए रजिस्टरों (R10, R11, और पैरामीटर पासिंग रजिस्टरों में से कोई भी) की सामग्री को स्टैक से हटाकर पुनर्स्थापित करता है। कॉल करने वाला यह मान सकता है कि सबरूटीन द्वारा किसी अन्य रजिस्टर को संशोधित नहीं किया गया था।
जिस तरह से कॉलिंग कन्वेंशन को संरचित किया गया है, उसके कारण आमतौर पर ऐसा होता है कि इनमें से कुछ (या अधिकतर) चरण स्टैक में कोई बदलाव नहीं करेंगे। उदाहरण के लिए, यदि छह या उससे कम पैरामीटर हैं, तो उस चरण में स्टैक पर कुछ भी नहीं धकेला जाता है। इसी तरह, प्रोग्रामर (और कंपाइलर) आम तौर पर अतिरिक्त पुश और पॉप को रोकने के लिए चरण 1 और 6 में कॉलर द्वारा सहेजे गए रजिस्टरों से उन परिणामों को रखते हैं जिनकी उन्हें परवाह होती है।
किसी सबरूटीन में मापदंडों को पारित करने के दो अन्य तरीके हैं, लेकिन इस ऑनलाइन कैरियर पाठ्यक्रम में उन पर चर्चा नहीं की जाएगी। उनमें से एक सामान्य प्रयोजन रजिस्टरों के बजाय स्वयं स्टैक का उपयोग करता है।
कैली के नियम
तथाकथित सबरूटीन की परिभाषा को निम्नलिखित नियमों का पालन करना चाहिए:
1. रजिस्टरों का उपयोग करके या स्टैक पर जगह बनाकर स्थानीय चर (प्रक्रिया के भीतर विकसित होने वाले चर) आवंटित करें। याद रखें स्टैक नीचे की ओर बढ़ता है। इसलिए, स्टैक के शीर्ष पर जगह बनाने के लिए, स्टैक पॉइंटर को कम किया जाना चाहिए। जिस मात्रा में स्टैक पॉइंटर को घटाया जाता है वह स्थानीय चर की आवश्यक संख्या पर निर्भर करता है। उदाहरण के लिए, यदि एक स्थानीय फ्लोट और एक स्थानीय लॉन्ग (कुल 12 बाइट्स) की आवश्यकता होती है, तो इन स्थानीय चर के लिए जगह बनाने के लिए स्टैक पॉइंटर को 12 से कम करना होगा। सी जैसी उच्च-स्तरीय भाषा में, इसका अर्थ मान निर्दिष्ट (प्रारंभिक) किए बिना चर घोषित करना है।
2. इसके बाद, फ़ंक्शन द्वारा उपयोग किए जाने वाले किसी भी रजिस्टर के मान जो निर्दिष्ट कैली-सेव (कॉलर द्वारा सहेजे नहीं गए सामान्य प्रयोजन रजिस्टर) हैं, को सहेजा जाना चाहिए। रजिस्टरों को सहेजने के लिए, उन्हें स्टैक पर धकेलें। कैली-सहेजे गए रजिस्टर आरबीएक्स, आरबीपी और आर12 से आर15 तक हैं (आरएसपी को कॉल कन्वेंशन द्वारा भी संरक्षित किया जाता है, लेकिन इस चरण के दौरान स्टैक पर धकेलने की आवश्यकता नहीं है)।
इन तीन क्रियाओं के निष्पादित होने के बाद, सबरूटीन का वास्तविक संचालन आगे बढ़ सकता है। जब सबरूटीन वापस लौटने के लिए तैयार होता है, तो कॉल कन्वेंशन नियम जारी रहते हैं।
3. जब सबरूटीन पूरा हो जाए, तो सबरूटीन के लिए रिटर्न वैल्यू RAX में रखा जाना चाहिए यदि यह पहले से मौजूद नहीं है।
4. सबरूटीन को किसी भी कैली-सहेजे गए रजिस्टर (आरबीएक्स, आरबीपी, और आर12 से आर15) के पुराने मूल्यों को पुनर्स्थापित करना होगा जिन्हें संशोधित किया गया था। रजिस्टर सामग्री को स्टैक से निकालकर पुनर्स्थापित किया जाता है। ध्यान दें कि रजिस्टरों को उसी विपरीत क्रम में पॉप किया जाना चाहिए जिस क्रम में उन्हें पुश किया गया था।
5. इसके बाद, हम स्थानीय चरों का आवंटन रद्द करते हैं। ऐसा करने का सबसे आसान तरीका आरएसपी में वही राशि जोड़ना है जो चरण 1 में इससे घटाया गया था।
6. अंत में, हम एक ret निर्देश निष्पादित करके कॉल करने वाले के पास लौटते हैं। यह निर्देश स्टैक से उचित रिटर्न पता ढूंढेगा और हटा देगा।
किसी अन्य सबरूटीन को कॉल करने के लिए कॉलर सबरूटीन की बॉडी का एक उदाहरण जो कि 'myFunc' है, इस प्रकार है (टिप्पणियाँ पढ़ें):
; एक फ़ंक्शन 'myFunc' को कॉल करना चाहते हैं जिसमें तीन लगते हैं
; पूर्णांक पैरामीटर. पहला पैरामीटर RAX में है।
; दूसरा पैरामीटर स्थिरांक 456 है। तीसरा
; पैरामीटर मेमोरी स्थान 'वेरिएबल' में है
पुश आरडीआई; rdi एक पैरामीटर होगा, इसलिए इसे सहेजा जा रहा है
; long retVal = myFunc (x, 456, z);
मूव आरडीआई, रैक्स; आरडीआई में पहला पैरामीटर डालें
मूव आरएसआई, 456 ; आरएसआई में दूसरा पैरामीटर डालें
mov rdx , [चर] ; आरडीएक्स में तीसरा पैरामीटर डालें
myFunc को कॉल करें; फ़ंक्शन को कॉल करें
पॉप आरडीआई; सहेजे गए RDI मान को पुनर्स्थापित करें
; myFunc का रिटर्न वैल्यू अब RAX में उपलब्ध है
कैली फ़ंक्शन (myFunc) का एक उदाहरण है (टिप्पणियाँ पढ़ें):
मायफनक:
; ∗∗∗ मानक सबरूटीन प्रस्तावना ∗∗∗
उप आरएसपी, 8 ; 'उप' ऑपकोड का उपयोग करके 64−बिट स्थानीय चर (परिणाम) के लिए जगह
पुश आरबीएक्स; सेव कैली-सेव रजिस्टर
पुश आरबीपी; दोनों का उपयोग myFunc द्वारा किया जाएगा
; ∗∗∗ उप दिनचर्या शरीर ∗∗∗
मूव रैक्स, आरडीआई; पैरामीटर 1 से RAX
मूव आरबीपी, आरएसआई; आरबीपी के लिए पैरामीटर 2
मूव आरबीएक्स, आरडीएक्स; पैरामीटर 3 से आरबी एक्स
मूव [आरएसपी + 1 6 ] , आरबीएक्स ; स्थानीय चर में rbx डालें
जोड़ें [ आरएसपी + 1 6 ] , आरबीपी ; स्थानीय चर में आरबीपी जोड़ें
मूव रैक्स , [ आरएसपी +16 ] ; स्थानीय चर की सामग्री को RAX में ले जाएँ
; (वापसी मूल्य/अंतिम परिणाम)
; ∗∗∗ मानक सबरूटीन उपसंहार ∗∗∗
पॉप आरबीपी; कैली को पुनर्प्राप्त करें, रजिस्टर सहेजें
पॉप आरबीएक्स; धक्का देने पर उलटा
आरएसपी जोड़ें, 8 ; स्थानीय चर का आवंटन रद्द करें। 8 का अर्थ है 8 बाइट्स
रिट ; स्टैक से शीर्ष मान पॉप करें, वहां जाएं
6.39 x64 के लिए व्यवधान और अपवाद
प्रोसेसर प्रोग्राम निष्पादन को बाधित करने, व्यवधान और अपवाद के लिए दो तंत्र प्रदान करता है:
- रुकावट एक अतुल्यकालिक (किसी भी समय हो सकती है) घटना है जो आम तौर पर I/O डिवाइस द्वारा ट्रिगर होती है।
- अपवाद एक तुल्यकालिक घटना है (ऐसा तब होता है जब कोड निष्पादित होता है, पूर्व-प्रोग्राम किया जाता है, कुछ घटनाओं के आधार पर) जो तब उत्पन्न होता है जब प्रोसेसर किसी निर्देश को निष्पादित करते समय एक या अधिक पूर्वनिर्धारित स्थितियों का पता लगाता है। अपवादों के तीन वर्ग निर्दिष्ट हैं: दोष, जाल और गर्भपात।
प्रोसेसर अनिवार्य रूप से उसी तरह से रुकावटों और अपवादों पर प्रतिक्रिया करता है। जब किसी रुकावट या अपवाद का संकेत दिया जाता है, तो प्रोसेसर वर्तमान प्रोग्राम या कार्य के निष्पादन को रोक देता है और एक हैंडलर प्रक्रिया पर स्विच कर देता है जो विशेष रूप से रुकावट या अपवाद स्थिति को संभालने के लिए लिखी जाती है। प्रोसेसर इंटरप्ट डिस्क्रिप्टर टेबल (आईडीटी) में एक प्रविष्टि के माध्यम से हैंडलर प्रक्रिया तक पहुंचता है। जब हैंडलर ने रुकावट या अपवाद को संभालना पूरा कर लिया है, तो प्रोग्राम नियंत्रण बाधित प्रोग्राम या कार्य पर वापस आ जाता है।
ऑपरेटिंग सिस्टम, एक्जीक्यूटिव और/या डिवाइस ड्राइवर आमतौर पर एप्लिकेशन प्रोग्राम या कार्यों से स्वतंत्र रूप से व्यवधान और अपवाद को संभालते हैं। हालाँकि, एप्लिकेशन प्रोग्राम किसी ऑपरेटिंग सिस्टम में शामिल किए गए इंटरप्ट और अपवाद हैंडलर तक पहुंच सकते हैं या असेंबली-भाषा कॉल के माध्यम से इसे निष्पादित कर सकते हैं।
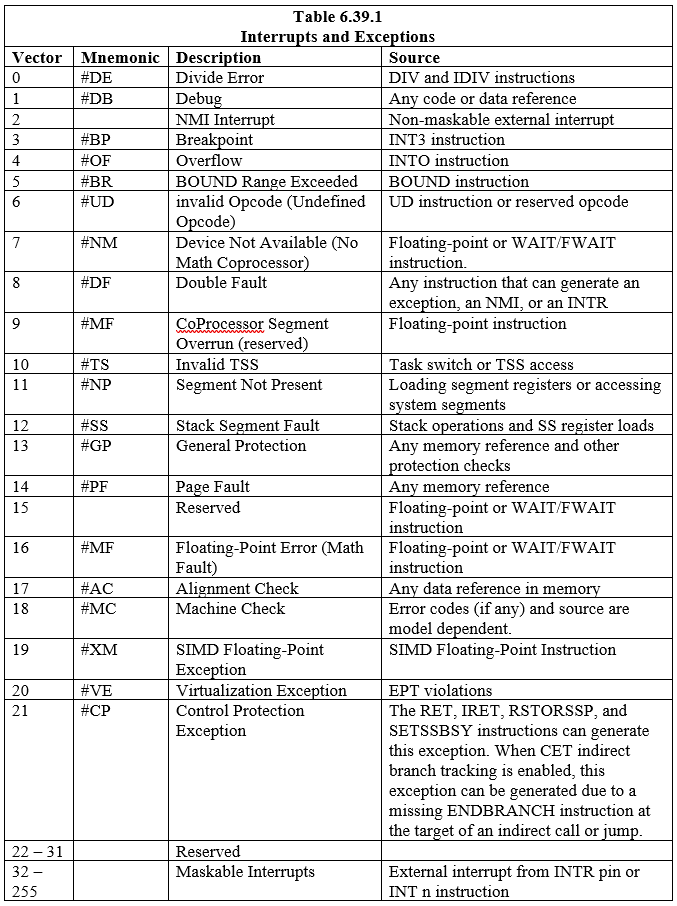
अठारह (18) पूर्वनिर्धारित व्यवधान और अपवाद, जो आईडीटी में प्रविष्टियों से जुड़े हैं, परिभाषित हैं। दो सौ चौबीस (224) उपयोगकर्ता परिभाषित इंटरप्ट भी बनाए जा सकते हैं और तालिका के साथ संबद्ध किए जा सकते हैं। आईडीटी में प्रत्येक व्यवधान और अपवाद को एक संख्या से पहचाना जाता है जिसे 'वेक्टर' कहा जाता है। तालिका 6.39.1 आईडीटी और उनके संबंधित वैक्टर में प्रविष्टियों के साथ व्यवधानों और अपवादों को सूचीबद्ध करती है। वेक्टर 0 से 8, 10 से 14, और 16 से 19 पूर्वनिर्धारित व्यवधान और अपवाद हैं। वैक्टर 32 से 255 सॉफ्टवेयर-परिभाषित इंटरप्ट (उपयोगकर्ता) के लिए हैं जो या तो सॉफ्टवेयर इंटरप्ट या मास्केबल हार्डवेयर इंटरप्ट के लिए हैं।
जब प्रोसेसर किसी रुकावट या अपवाद का पता लगाता है, तो यह निम्नलिखित में से एक कार्य करता है:
- हैंडलर प्रक्रिया के लिए एक अंतर्निहित कॉल निष्पादित करें
- हैंडलर कार्य के लिए एक अंतर्निहित कॉल निष्पादित करें
6.4 64-बिट एआरएम कंप्यूटर आर्किटेक्चर मूल बातें
एआरएम आर्किटेक्चर आरआईएससी प्रोसेसर के एक परिवार को परिभाषित करते हैं जो विभिन्न प्रकार के अनुप्रयोगों में उपयोग के लिए उपयुक्त हैं। एआरएम एक लोड/स्टोर आर्किटेक्चर है जिसके लिए एएलयू (अरिथमेटिक लॉजिक यूनिट) ऑपरेशन जैसे किसी भी प्रसंस्करण से पहले डेटा को मेमोरी से रजिस्टर में लोड करने की आवश्यकता होती है। बाद का निर्देश परिणाम को वापस मेमोरी में संग्रहीत करता है। हालांकि यह x86 और x64 आर्किटेक्चर से एक कदम पीछे की तरह लग सकता है, जो एक ही निर्देश में मेमोरी में ऑपरेंड पर सीधे काम करता है (प्रोसेसर रजिस्टरों का उपयोग करके, निश्चित रूप से), लोड/स्टोर दृष्टिकोण, व्यवहार में, कई अनुक्रमिक संचालन की अनुमति देता है एक बार इसे कई प्रोसेसर रजिस्टरों में से एक में लोड करने के बाद ऑपरेंड पर उच्च गति से निष्पादित किया जाना है। एआरएम प्रोसेसर में छोटी एंडियननेस या बिग-एंडियननेस का विकल्प होता है। डिफ़ॉल्ट एआरएम 64 सेटिंग लिटिल-एंडियन है जो वह कॉन्फ़िगरेशन है जो आमतौर पर ऑपरेटिंग सिस्टम द्वारा उपयोग किया जाता है। 64-बिट एआरएम आर्किटेक्चर आधुनिक है और यह 32-बिट एआरएम आर्किटेक्चर को बदलने के लिए तैयार है।
टिप्पणी : 64-बिट ARM µP के लिए प्रत्येक निर्देश 4 बाइट्स (32 बिट्स) लंबा है।
6.41 64-बिट एआरएम रजिस्टर सेट
64-बिट एआरएम µP के लिए 64-बिट रजिस्टरों के 31 सामान्य उद्देश्य हैं। निम्नलिखित चित्र सामान्य प्रयोजन रजिस्टरों और कुछ महत्वपूर्ण रजिस्टरों को दर्शाता है:
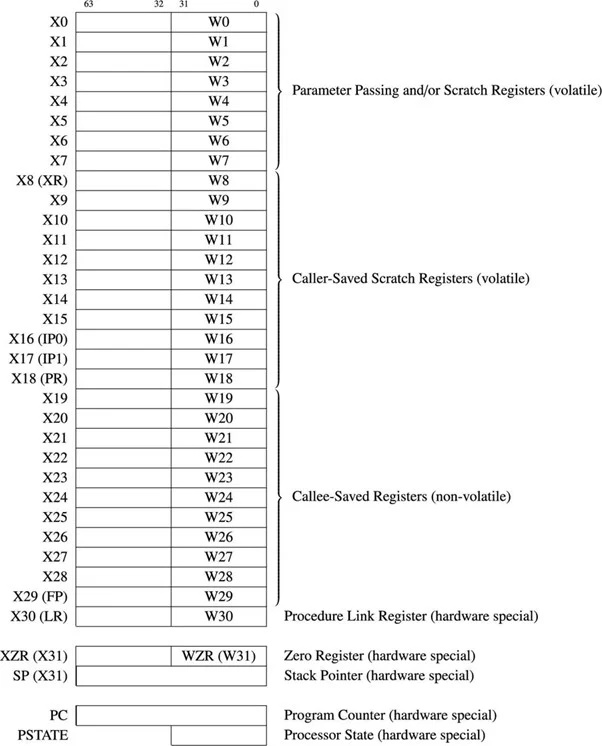
चित्र.4.11.1 64-बिट सामान्य प्रयोजन और कुछ महत्वपूर्ण रजिस्टर
सामान्य प्रयोजन रजिस्टरों को X0 से X30 तक कहा जाता है। प्रत्येक रजिस्टर के पहले 32-बिट भाग को W0 से W30 तक कहा जाता है। जब 32 बिट्स और 64 बिट्स के बीच अंतर पर जोर नहीं दिया जाता है, तो 'आर' उपसर्ग का उपयोग किया जाता है। उदाहरण के लिए, R14, W14 या X14 को संदर्भित करता है।
6502 µP में 16-बिट प्रोग्राम काउंटर है और यह 2 को संबोधित कर सकता है 16 मेमोरी बाइट स्थान. 64-बिट ARM µP में 64-बिट प्रोग्राम काउंटर है और यह 2 तक को संबोधित कर सकता है 64 = 1.844674407 x 1019 (वास्तव में 18,446,744,073,709,551,616) मेमोरी बाइट स्थान। प्रोग्राम काउंटर निष्पादित होने वाले अगले निर्देश का पता रखता है। ARM64 या AArch64 के निर्देश की लंबाई आम तौर पर चार बाइट्स होती है। मेमोरी से प्रत्येक निर्देश प्राप्त होने के बाद प्रोसेसर स्वचालित रूप से इस रजिस्टर को चार से बढ़ा देता है।
स्टैक पॉइंटर रजिस्टर या एसपी 31 सामान्य प्रयोजन रजिस्टरों में से नहीं है। किसी भी आर्किटेक्चर का स्टैक पॉइंटर मेमोरी में अंतिम स्टैक प्रविष्टि की ओर इशारा करता है। एआरएम-64 के लिए, स्टैक नीचे की ओर बढ़ता है।
6502 µP में 8-बिट प्रोसेसर स्टेटस रजिस्टर है। ARM64 में समतुल्य को PSTATE रजिस्टर कहा जाता है। यह रजिस्टर उन झंडों को संग्रहीत करता है जिनका उपयोग संचालन के परिणामों और प्रोसेसर (μP) को नियंत्रित करने के लिए किया जाता है। यह 32-बिट चौड़ा है. निम्न तालिका PSTATE रजिस्टर में आमतौर पर उपयोग किए जाने वाले बिट्स के नाम, सूचकांक और अर्थ देती है:
| तालिका 6.41.1 सर्वाधिक प्रयुक्त PSTATE झंडे (बिट्स) |
||
|---|---|---|
| प्रतीक | अंश | उद्देश्य |
| एम | 0-3 | मोड: वर्तमान निष्पादन विशेषाधिकार स्तर (यूएसआर, एसवीसी, और इसी तरह)। |
| टी | 4 | अंगूठा: यदि T32 (अंगूठा) निर्देश सेट सक्रिय है तो यह सेट किया जाता है। यदि स्पष्ट है, तो एआरएम निर्देश सेट सक्रिय है। उपयोगकर्ता कोड इस बिट को सेट और साफ़ कर सकता है। |
| और | 9 | एंडियननेस: इस बिट को सेट करने से बिग-एंडियन मोड सक्षम हो जाता है। यदि स्पष्ट है, तो लिटिल-एंडियन मोड सक्रिय है। डिफ़ॉल्ट लिटिल-एंडियन मोड है। |
| क्यू | 27 | संचयी संतृप्ति ध्वज: यह तब सेट किया जाता है, जब संचालन की श्रृंखला में किसी बिंदु पर, अतिप्रवाह या संतृप्ति होती है |
| में | 28 | ओवरफ़्लो फ़्लैग: यह तब सेट किया जाता है जब ऑपरेशन के परिणामस्वरूप हस्ताक्षरित ओवरफ़्लो होता है। |
| सी | 29 | कैरी फ़्लैग: यह इंगित करता है कि जोड़ से कैरी उत्पन्न हुआ या घटाव से उधार उत्पन्न हुआ। |
| साथ | 30 | शून्य ध्वज: यदि किसी ऑपरेशन का परिणाम शून्य है तो इसे सेट किया जाता है। |
| एन | 31 | नकारात्मक ध्वज: यदि किसी ऑपरेशन का परिणाम नकारात्मक है तो इसे सेट किया जाता है। |
ARM-64 µP में कई अन्य रजिस्टर हैं।
SIMD
SIMD का मतलब सिंगल इंस्ट्रक्शन, मल्टीपल डेटा है। इसका मतलब यह है कि एक असेंबली भाषा निर्देश एक माइक्रोप्रोसेसर में एक ही समय में कई डेटा पर कार्य कर सकता है। SIMD और फ़्लोटिंग-पॉइंट संचालन के साथ उपयोग के लिए बत्तीस 128 बिट चौड़े रजिस्टर हैं।
6.42 मेमोरी मैपिंग
RAM और DRAM दोनों रैंडम एक्सेस मेमोरी हैं। DRAM, RAM की तुलना में धीमी गति से काम करता है। DRAM RAM से सस्ता है. यदि मेमोरी में 32 गीगाबाइट (जीबी) से अधिक निरंतर डीआरएएम है, तो अधिक मेमोरी प्रबंधन समस्याएं होंगी: 32 जीबी = 32 x 1024 x 1024 x 1024 बाइट्स। पूरे मेमोरी स्पेस के लिए जो 32 जीबी से कहीं बड़ा है, बेहतर मेमोरी प्रबंधन के लिए 32 जीबी से ऊपर के डीआरएएम को रैम के साथ जोड़ा जाना चाहिए। ARM-64 मेमोरी मैप को समझने के लिए, आपको पहले 32-बिट ARM सेंट्रल प्रोसेसिंग यूनिट (CPU) के लिए 4GB मेमोरी मैप को समझना चाहिए। CPU का अर्थ है µP. 32-बिट कंप्यूटर के लिए, अधिकतम मेमोरी एड्रेसेबल स्पेस 2 है 32 = 4 x 2 10 एक्स 2 10 एक्स 2 10 = 4 x 1024 x 1024 x 1024 = 4,294,967,296 = 4 जीबी।
32-बिट एआरएम मेमोरी मैप
32-बिट एआरएम के लिए मेमोरी मैप है:

32-बिट कंप्यूटर के लिए, संपूर्ण मेमोरी का अधिकतम आकार 4GB है। 0GB पते से 1GB पते तक ROM ऑपरेटिंग सिस्टम, RAM और I/O स्थान हैं। ROM OS, RAM और I/O पतों का पूरा विचार संभावित 6502 CPU के साथ कमोडोर-64 की स्थिति के समान है। कमोडोर-64 के लिए OS ROM मेमोरी स्पेस के शीर्ष-छोर पर है। यहां ROM OS कमोडोर-64 की तुलना में बहुत बड़ा है, और यह संपूर्ण मेमोरी एड्रेस स्पेस की शुरुआत में है। जब अन्य आधुनिक कंप्यूटरों से तुलना की जाती है, तो यहां ROM OS पूर्ण है, इस अर्थ में कि यह उनकी हार्ड ड्राइव में OS की मात्रा के बराबर है। ROM इंटीग्रेटेड सर्किट में OS होने के दो मुख्य कारण हैं: 1) ARM CPU का उपयोग ज्यादातर स्मार्टफोन जैसे छोटे उपकरणों में किया जाता है। कई हार्ड ड्राइव स्मार्टफोन और अन्य छोटे उपकरणों से बड़ी होती हैं, 2) सुरक्षा के लिए। जब ओएस रीड ओनली मेमोरी में होता है, तो इसे हैकर्स द्वारा दूषित (कुछ हिस्सों में ओवरराइट) नहीं किया जा सकता है। कमोडोर-64 की तुलना में रैम अनुभाग और इनपुट/आउटपुट अनुभाग भी बहुत बड़े हैं।
जब पावर को 32-बिट ROM OS के साथ चालू किया जाता है, तो HiVECs सक्षम होने पर OS को 0x00000000 पते या 0xFFFF0000 पते पर (बूट से) शुरू करना होगा। इसलिए, जब रीसेट चरण के बाद बिजली चालू की जाती है, तो सीपीयू हार्डवेयर प्रोग्राम काउंटर पर 0x00000000 या 0xFFFF0000 लोड करता है। '0x' उपसर्ग का अर्थ हेक्साडेसिमल है। ARMv8 64bit CPU का बूट पता एक परिभाषित कार्यान्वयन है। हालाँकि, लेखक कंप्यूटर इंजीनियर को बैकवर्ड अनुकूलता के लिए 0x00000000 या 0xFFFF0000 से शुरू करने की सलाह देता है।
1GB से 2GB तक मैप किया गया इनपुट/आउटपुट है। मैप किए गए I/O और केवल I/O के बीच अंतर है जो 0GB और 1GB के बीच पाए जाते हैं। I/O के साथ, प्रत्येक पोर्ट का पता कमोडोर-64 की तरह तय किया जाता है। मैप किए गए I/O के साथ, कंप्यूटर के प्रत्येक ऑपरेशन (डायनामिक) के लिए प्रत्येक पोर्ट का पता आवश्यक रूप से समान नहीं होता है।
2GB से 4GB तक DRAM है. यह अपेक्षित (या सामान्य) रैम है। DRAM का मतलब डायनामिक रैम है, यह कंप्यूटर ऑपरेशन के दौरान बदलते पते का अर्थ नहीं है, बल्कि इस अर्थ में है कि भौतिक रैम में प्रत्येक सेल के मूल्य को प्रत्येक घड़ी पल्स पर ताज़ा करना पड़ता है।
टिप्पणी :
- 0x0000,0000 से 0x0000 तक, FFFF OS ROM है।
- 0x0001,0000 से 0x3FFF,FFFF तक, अधिक ROM, फिर RAM और फिर कुछ I/O हो सकते हैं।
- 0x4000,0000 से 0x7FFF,FFFF तक, एक अतिरिक्त I/O और/या मैप किए गए I/O की अनुमति है।
- 0x8000,0000 से 0xFFFF तक, FFFF अपेक्षित DRAM है।
इसका मतलब यह है कि व्यवहार में अपेक्षित DRAM को 2GB मेमोरी सीमा पर शुरू करने की आवश्यकता नहीं है। प्रोग्रामर को आदर्श सीमाओं का सम्मान क्यों करना चाहिए जब मदरबोर्ड पर पर्याप्त भौतिक रैम बैंक नहीं हैं? ऐसा इसलिए है क्योंकि ग्राहक के पास सभी रैम बैंकों के लिए पर्याप्त पैसा नहीं है।
36-बिट एआरएम मेमोरी मैप
64-बिट एआरएम कंप्यूटर के लिए, सभी 32 बिट्स का उपयोग संपूर्ण मेमोरी को संबोधित करने के लिए किया जाता है। 64-बिट एआरएम कंप्यूटर के लिए, पहले 36 बिट्स का उपयोग पूरी मेमोरी को संबोधित करने के लिए किया जा सकता है, जो इस मामले में, 2 है 36 = 68,719,476,736 = 64 जीबी। यह पहले से ही बहुत सारी मेमोरी है. आज के सामान्य कम्प्यूटरों को इतनी मेमोरी की आवश्यकता नहीं होती। यह अभी तक मेमोरी की अधिकतम सीमा तक नहीं है जिसे 64 बिट्स द्वारा एक्सेस किया जा सकता है। एआरएम सीपीयू के लिए 36-बिट्स का मेमोरी मैप है:
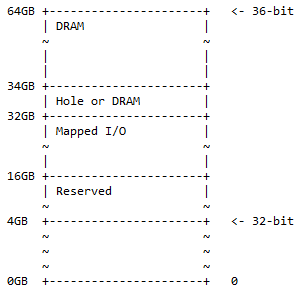
0GB एड्रेस से 4GB एड्रेस तक 32-बिट मेमोरी मैप है। 'आरक्षित' का अर्थ है उपयोग नहीं किया गया और भविष्य में उपयोग के लिए रखा गया है। इसमें भौतिक मेमोरी बैंक होने की आवश्यकता नहीं है जो उस स्थान के लिए मदरबोर्ड पर रखे गए हों। यहां, DRAM और मैप किए गए I/O का वही अर्थ है जो 32-बिट मेमोरी मैप के लिए है।
व्यवहार में निम्नलिखित स्थिति पाई जा सकती है:
- 0x1 0000 0000 - 0x3 FFFF FFFF; आरक्षित. 12GB पता स्थान भविष्य में उपयोग के लिए आरक्षित है।
- 0x4 0000 0000 - 0x7 FFFF FFFF; मैप किया गया I/O. डायनामिकली मैप किए गए I/O के लिए 16GB एड्रेस स्पेस उपलब्ध है।
- 0x8 0000 0000 - 0x8 7FFF FFFF FFFF; छेद या DRAM. 2GB एड्रेस स्पेस में निम्नलिखित में से कोई भी हो सकता है:
- DRAM डिवाइस विभाजन को सक्षम करने के लिए छेद (जैसा कि निम्नलिखित चर्चा में बताया गया है)।
- नाटक।
- 0x8 8000 0000 - 0xF FFFF FFFF; नाटक। DRAM के लिए 30GB का एड्रेस स्पेस।
यह मेमोरी मैप 32-बिट एड्रेस मैप का एक सुपरसेट है, जिसमें अतिरिक्त स्थान को 50% DRAM (1/2) के रूप में विभाजित किया गया है, जिसमें एक वैकल्पिक छेद है और 25% मैप किए गए I/O स्पेस और आरक्षित स्थान (1/4) ). शेष 25% (1/4) 32-बिट मेमोरी मैप ½ + ¼ + ¼ = 1 के लिए है।
टिप्पणी : 32 बिट्स से 360 बिट्स तक 36 बिट्स के सबसे महत्वपूर्ण पक्ष में 4 बिट्स का जोड़ है।
40-बिट मेमोरी मैप
40-बिट एड्रेस मैप 36-बिट एड्रेस मैप का एक सुपरसेट है और इसमें वैकल्पिक छेद के 50% DRAM, 25% मैप किए गए I/O स्पेस और आरक्षित स्थान और शेष 25% के समान पैटर्न का अनुसरण करता है। पिछले मेमोरी मैप के लिए स्थान (36-बिट)। मेमोरी मैप का आरेख है:
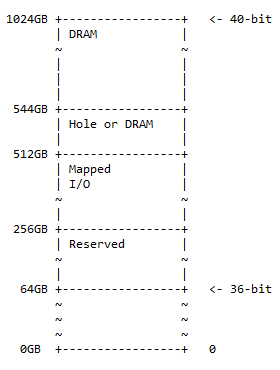
छेद का आकार 544 - 512 = 32GB है। व्यवहार में निम्नलिखित स्थिति पाई जा सकती है:
- 0x10 0000 0000 - 0x3F FFFF FFFF; आरक्षित. 192GB पता स्थान भविष्य में उपयोग के लिए आरक्षित है।
- 0x40 0000 0000 - 0x7F FFFF FFFF; मैप किया गया। गतिशील रूप से मैप किए गए I/O के लिए I/O 256GB पता स्थान उपलब्ध है।
- 0x80 0000 0000 - 0x87 एफएफएफएफ एफएफएफएफ; छेद या DRAM. 32GB एड्रेस स्पेस में निम्नलिखित में से कोई भी हो सकता है:
- DRAM डिवाइस विभाजन को सक्षम करने के लिए छेद (जैसा कि निम्नलिखित चर्चा में बताया गया है)
- घूंट
- 0x88 0000 0000 - 0xFF FFFF FFFF; नाटक। DRAM के लिए 480GB का एड्रेस स्पेस।
टिप्पणी : 36 बिट्स से 40 बिट्स तक 36 बिट्स के सबसे महत्वपूर्ण पक्ष में 4 बिट्स का जोड़ है।
DRAM होल
32-बिट से परे मेमोरी मैप में, यह या तो एक DRAM होल है या ऊपर से DRAM की निरंतरता है। जब यह एक छेद होता है, तो इसकी सराहना इस प्रकार की जानी चाहिए: DRAM छेद एक बड़े DRAM डिवाइस को कई एड्रेस रेंज में विभाजित करने का एक तरीका प्रदान करता है। वैकल्पिक DRAM छेद उच्च DRAM पता सीमा की शुरुआत में प्रस्तावित है। यह एक बड़ी क्षमता वाले DRAM डिवाइस को निचले भौतिक रूप से संबोधित क्षेत्र में विभाजित करते समय एक सरलीकृत डिकोडिंग योजना को सक्षम बनाता है।
उदाहरण के लिए, एक 64GB DRAM भाग को तीन क्षेत्रों में उप-विभाजित किया गया है, जिसमें उच्च ऑर्डर एड्रेस बिट्स में एक साधारण घटाव द्वारा किए गए एड्रेस ऑफसेट निम्नानुसार हैं:
| तालिका 6.42.1 छिद्रों के साथ 64GB DRAM विभाजन का उदाहरण |
|||
|---|---|---|---|
| एसओसी में भौतिक पते | ओफ़्सेट | आंतरिक DRAM पता | |
| 2 GBytes (32-बिट मानचित्र) | 0x00 8000 0000 - 0x00 FFFF FFFF | -0x00 8000 0000 | 0x00 0000 0000 - 0x00 7FFF FFFF |
| 30 GBytes (36-बिट मानचित्र) | 0x08 8000 0000 - 0x0F FFFF FFFF | -0x08 0000 0000 | 0x00 8000 0000 - 0x07 एफएफएफएफ एफएफएफएफ |
| 32 GBytes (40-बिट मानचित्र) | 0x88 0000 0000 - 0x8F FFFF FFFF | -0x80 0000 0000 | 0x08 0000 0000 - 0x0F FFFF FFFF |
एआरएम सीपीयू के लिए प्रस्तावित 44-बिट और 48-बिट एड्रेस्ड मेमोरी मैप
मान लें कि एक पर्सनल कंप्यूटर में 1024GB (= 1TB) मेमोरी है; वह बहुत अधिक स्मृति है. और इसलिए, क्रमशः 16 टीबी और 256 टीबी के लिए एआरएम सीपीयू के लिए 44-बिट और 48-बिट संबोधित मेमोरी मैप, भविष्य की कंप्यूटर आवश्यकताओं के लिए सिर्फ प्रस्ताव हैं। वास्तव में, एआरएम सीपीयू के लिए ये प्रस्ताव पिछले मेमोरी मैप के अनुपात में मेमोरी के समान विभाजन का पालन करते हैं। वह है: वैकल्पिक छेद के साथ 50% DRAM, 25% मैप किया गया I/O स्थान और आरक्षित स्थान, और शेष 25% स्थान पिछले मेमोरी मैप के लिए।
सुदूर भविष्य के लिए एआरएम 64 बिट्स के लिए 52-बिट, 56-बिट, 60-बिट और 64-बिट एड्रेस्ड मेमोरी मैप अभी भी प्रस्तावित किए जाने हैं। यदि उस समय के वैज्ञानिक अभी भी संपूर्ण मेमोरी स्पेस के 50:25:25 विभाजन को उपयोगी पाते हैं, तो वे अनुपात बनाए रखेंगे।
टिप्पणी : SoC का मतलब सिस्टम-ऑन-चिप है जो µP चिप में सर्किट को संदर्भित करता है जो अन्यथा वहां नहीं होता।
SRAM या स्टेटिक रैंडम एक्सेस मेमोरी अधिक पारंपरिक DRAM से तेज़ है, लेकिन इसके लिए अधिक सिलिकॉन क्षेत्र की आवश्यकता होती है। SRAM को रिफ्रेशिंग की आवश्यकता नहीं है। पाठक RAM की कल्पना SRAM के रूप में कर सकता है।
6.43 एआरएम 64 के लिए असेंबली लैंग्वेज एड्रेसिंग मोड
एआरएम एक लोड/स्टोर आर्किटेक्चर है जिसके लिए अंकगणित तर्क ऑपरेशन जैसे किसी भी प्रसंस्करण से पहले डेटा को मेमोरी से प्रोसेसर रजिस्टर में लोड करने की आवश्यकता होती है। बाद का निर्देश परिणाम को वापस मेमोरी में संग्रहीत करता है। हालांकि यह x86 और उसके बाद के x64 आर्किटेक्चर से एक कदम पीछे की तरह लग सकता है, जो एक ही निर्देश में मेमोरी में सीधे ऑपरेंड पर काम करता है, व्यवहार में, लोड/स्टोर दृष्टिकोण कई अनुक्रमिक संचालन को उच्च गति पर निष्पादित करने की अनुमति देता है। एक ऑपरेंड एक बार कई प्रोसेसर रजिस्टरों में से एक में लोड हो जाता है।
एआरएम असेंबली भाषा के प्रारूप में x64 (x86) श्रृंखला के साथ समानताएं और अंतर हैं।
- ओफ़्सेट : एक हस्ताक्षरित स्थिरांक को आधार रजिस्टर में जोड़ा जा सकता है। ऑफसेट को निर्देश के भाग के रूप में टाइप किया गया है। उदाहरण के लिए: ldr x0, [rx, #10] r1+10 पते पर शब्द के साथ r0 लोड करता है।
- पंजीकरण करवाना : एक अहस्ताक्षरित वेतन वृद्धि जो एक रजिस्टर में संग्रहीत होती है उसे आधार रजिस्टर में मूल्य से जोड़ा या घटाया जा सकता है। उदाहरण के लिए: ldr r0, [X1, x2] x1+x2 पते पर शब्द के साथ r0 लोड करता है। किसी भी रजिस्टर को आधार रजिस्टर माना जा सकता है।
- स्केल्ड रजिस्टर : किसी रजिस्टर में वृद्धि को आधार रजिस्टर मान में जोड़ने या घटाने से पहले एक निर्दिष्ट संख्या में बिट स्थितियों द्वारा बाएं या दाएं स्थानांतरित किया जाता है। उदाहरण के लिए: ldr x0, [x1, x2, lsl #3] r1+(r2×8) पते पर शब्द के साथ r0 लोड करता है। शिफ्ट एक तार्किक बाईं या दाईं शिफ्ट (एलएसएल या एलएसआर) हो सकती है जो खाली बिट स्थितियों में शून्य बिट्स डालती है या एक अंकगणितीय दाएं शिफ्ट (एएसआर) जो खाली स्थितियों में साइन बिट को दोहराती है।
जब दो ऑपरेंड शामिल होते हैं, तो गंतव्य स्रोत से पहले (बाईं ओर) आता है (इसके कुछ अपवाद हैं)। एआरएम असेंबली भाषा के लिए ऑपकोड केस असंवेदनशील हैं।
तत्काल ARM64 एड्रेसिंग मोड
उदाहरण:
mov r0, #0xFF000000 ; 32-बिट मान FF000000h को r0 में लोड करें
दशमलव मान 0x के बिना है लेकिन फिर भी # से पहले है।
सीधे रजिस्टर करें
उदाहरण:
mov x0, x1 ; X1 को x0 पर कॉपी करें
अप्रत्यक्ष पंजीकरण करें
उदाहरण:
str x0, [x3] ; x0 को x3 में पते पर संग्रहीत करें
ऑफसेट के साथ अप्रत्यक्ष पंजीकरण करें
उदाहरण:
एलडीआर x0, [X1, #32] ; पते पर मान के साथ r0 लोड करें [r1+32]; r1 आधार रजिस्टर है
str x0, [X1, #4] ; r0 को पते पर संग्रहीत करें [r1+4]; r1 आधार रजिस्टर है; संख्याएँ आधार 10 हैं
ऑफसेट के साथ अप्रत्यक्ष पंजीकरण (पूर्व-वृद्धि)
उदाहरण:
एलडीआर x0, [x1, #32]! ; [r1+32] के साथ r0 लोड करें और r1 को (r1+32) में अपडेट करें
str x0, [X1, #4]! ; r0 को [r1+4] में स्टोर करें और r1 को (r1+4) में अपडेट करें
'!' के उपयोग पर ध्यान दें प्रतीक।
ऑफसेट के साथ अप्रत्यक्ष पंजीकरण (पोस्ट-वृद्धि)
उदाहरण:
एलडीआर x0, [x1], #32; [x1] को x0 पर लोड करें, फिर x1 को (x1+32) में अपडेट करें
str x0, [X1], #4 ; x0 को [x1] में स्टोर करें, फिर x1 को (x1+4) में अपडेट करें
डबल रजिस्टर अप्रत्यक्ष
ऑपरेंड का पता आधार रजिस्टर और वेतन वृद्धि रजिस्टर का योग है। रजिस्टर नाम वर्गाकार कोष्ठकों से घिरे हुए हैं।
उदाहरण:
एलडीआर x0, [X1, x2] ; [x1+x2] के साथ x0 लोड करें
str x0, [rx, x2] ; x0 को [x1+x2] पर स्टोर करें
रिलेटिव एड्रेसिंग मोड
रिलेटिव एड्रेसिंग मोड में, प्रभावी निर्देश प्रोग्राम काउंटर में अगला निर्देश, साथ ही एक इंडेक्स होता है। सूचकांक सकारात्मक या नकारात्मक हो सकता है.
उदाहरण:
एलडीआर x0, [पीसी, #24]
इसका मतलब है लोड रजिस्टर X0 उस शब्द के साथ जो पीसी सामग्री प्लस 24 द्वारा इंगित किया गया है।
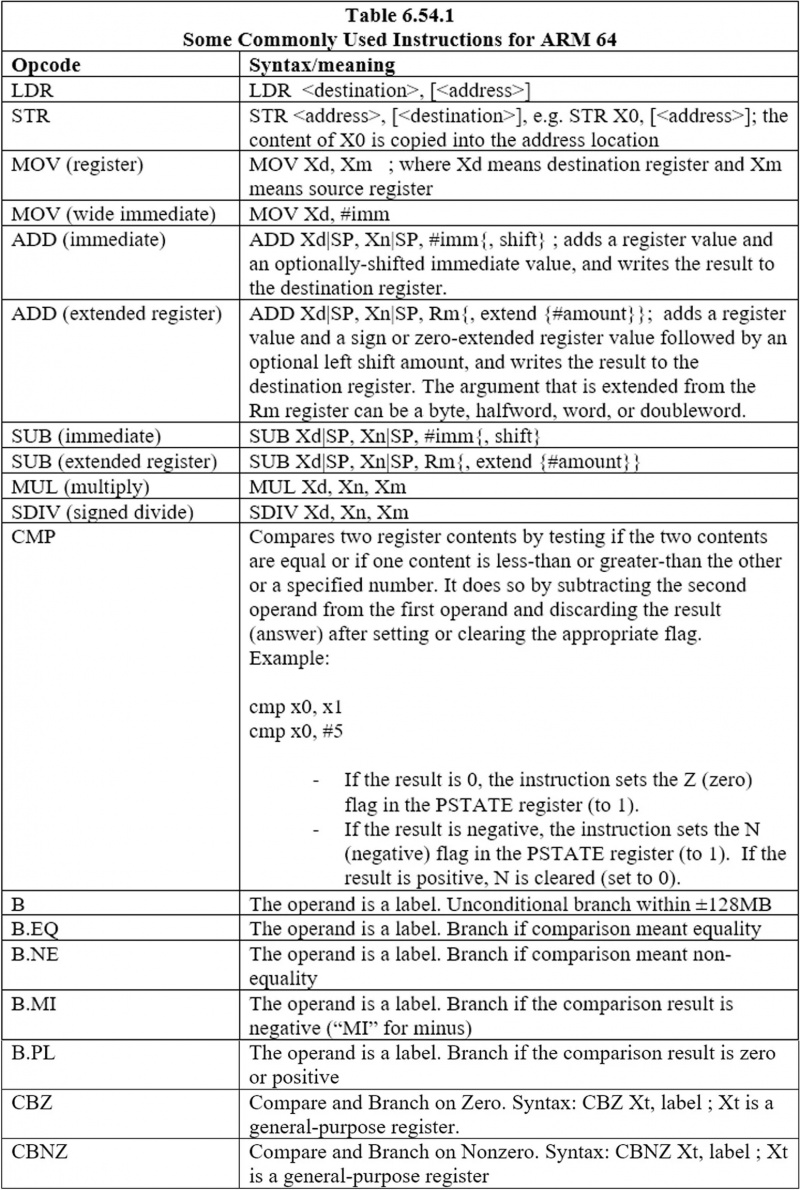
6.44 एआरएम 64 के लिए कुछ सामान्य रूप से प्रयुक्त निर्देश
यहां आमतौर पर उपयोग किए जाने वाले निर्देश दिए गए हैं:
6.45 लूपिंग
चित्रण
निम्नलिखित कोड X10 रजिस्टर में मान को X9 के मान में तब तक जोड़ता रहता है जब तक कि X8 में मान शून्य न हो जाए। मान लें कि सभी मान पूर्णांक हैं। प्रत्येक पुनरावृत्ति में X8 का मान 1 से घटाया जाता है:
कुंडली:
सीबीजेड एक्स8, छोड़ें
X9, X9, X10 जोड़ें; पहला X9 गंतव्य है और दूसरा X9 स्रोत है
उप X8, X8, #1 ; पहला X8 गंतव्य है और दूसरा X8 स्रोत है
बी लूप
छोडना:
6502 µP और X64 µP की तरह, ARM 64 µP में लेबल लाइन की शुरुआत में शुरू होता है। बाकी निर्देश पंक्ति की शुरुआत के बाद कुछ स्थानों पर शुरू होते हैं। x64 और एआरएम 64 के साथ, लेबल के बाद एक कोलन और एक नई लाइन आती है। जबकि 6502 के साथ, लेबल के बाद एक स्थान के बाद एक निर्देश होता है। पिछले कोड में, पहला निर्देश जो 'CBZ 'छोडना:'। 'बी लूप' 'लूप' लेबल पर बिना शर्त छलांग है। 'लूप' के स्थान पर किसी अन्य लेबल नाम का उपयोग किया जा सकता है।
तो, 6502 µP की तरह, ARM 64 के साथ एक लूप बनाने के लिए शाखा निर्देशों का उपयोग करें।
6.46 एआरएम 64 इनपुट/आउटपुट
सभी एआरएम परिधीय (आंतरिक पोर्ट) मेमोरी मैप किए गए हैं। इसका मतलब है कि प्रोग्रामिंग इंटरफ़ेस मेमोरी एड्रेस्ड रजिस्टरों (आंतरिक पोर्ट) का एक सेट है। ऐसे रजिस्टर का पता एक विशिष्ट मेमोरी बेस पते से ऑफसेट होता है। यह उसी के समान है कि 6502 इनपुट/आउटपुट कैसे करता है। एआरएम के पास अलग I/O एड्रेस स्पेस का विकल्प नहीं है।
6.47 एआरएम 64 का ढेर
एआरएम 64 में मेमोरी (रैम) का ढेर उसी तरह है जैसे 6502 और x64 में है। हालाँकि, ARM64 के साथ, कोई पुश या पॉप ऑपकोड नहीं है। एआरएम 64 में स्टैक भी नीचे की ओर बढ़ता है। स्टैक पॉइंटर में पता स्टैक में रखे गए अंतिम मान के अंतिम बाइट के ठीक बाद इंगित करता है।
ARM64 के लिए कोई सामान्य पॉप या पुश ऑपकोड नहीं होने का कारण यह है कि ARM 64 लगातार 16 बाइट्स के समूहों में अपने स्टैक का प्रबंधन करता है। हालाँकि, मान एक बाइट, दो बाइट्स, चार बाइट्स और 8 बाइट्स के बाइट समूहों में मौजूद हैं। तो, एक मान को स्टैक में रखा जा सकता है, और 16 बाइट्स बनाने के लिए बाकी स्थानों (बाइट स्थानों) को डमी बाइट्स के साथ गद्देदार किया जाता है। इससे मेमोरी बर्बाद होने का नुकसान होता है। एक बेहतर समाधान 16-बाइट स्थान को छोटे मानों से भरना है और कुछ प्रोग्रामर लिखित कोड है जो ट्रैक करता है कि 16-बाइट स्थान में मान कहां से आते हैं (रजिस्टर)। मूल्यों को वापस खींचने में भी इस अतिरिक्त कोड की आवश्यकता होती है। इसका एक विकल्प दो 8-बाइट सामान्य प्रयोजन रजिस्टरों को अलग-अलग मानों से भरना है, और फिर दो 8-बाइट रजिस्टरों की सामग्री को एक स्टैक में भेजना है। स्टैक में जाने और स्टैक छोड़ने वाले विशिष्ट छोटे मानों को ट्रैक करने के लिए यहां अभी भी एक अतिरिक्त कोड की आवश्यकता है।
निम्नलिखित कोड चार 4-बाइट डेटा को स्टैक में संग्रहीत करता है:
str w0, [एसपी, #-4]!
str w1, [एसपी, #-8]!
str w2, [एसपी, #-12]!
str w3, [एसपी, #-16]!
रजिस्टरों के पहले चार बाइट्स (w) - x0, x1, x2, और x3 - स्टैक में लगातार 16 बाइट स्थानों पर भेजे जाते हैं। 'str' के उपयोग पर ध्यान दें न कि 'पुश' के। प्रत्येक निर्देश के अंत में विस्मयादिबोधक चिह्न पर ध्यान दें। चूँकि मेमोरी स्टैक नीचे की ओर बढ़ता है, पहला चार-बाइट मान उस स्थिति पर शुरू होता है जो पिछले स्टैक पॉइंटर स्थिति से माइनस-चार बाइट्स नीचे होता है। शेष चार-बाइट मान नीचे जाते हुए अनुसरण करते हैं। निम्नलिखित कोड खंड चार बाइट्स को पॉप करने के बराबर सही (और क्रम में) काम करेगा:
एलडीआर डब्ल्यू3, [एसपी], #0
एलडीआर डब्ल्यू2, [एसपी], #4
एलडीआर डब्ल्यू1, [एसपी], #8
एलडीआर डब्ल्यू0, [एसपी], #12
पॉप के स्थान पर एलडीआर ऑपकोड के उपयोग पर ध्यान दें। यह भी ध्यान रखें कि यहां विस्मयादिबोधक चिह्न का प्रयोग नहीं किया गया है।
X0 (8 बाइट्स) और X1 (8 बाइट्स) के सभी बाइट्स को स्टैक में 16 बाइट-स्थान पर निम्नानुसार भेजा जा सकता है:
एसटीपी x0, x1, [एसपी, #-16]! ; 8 + 8 = 16
इस स्थिति में, x2 (w2) और x3 (w3) रजिस्टरों की आवश्यकता नहीं है। सभी वांछित बाइट्स X0 और X2 रजिस्टर में हैं। रैम में रजिस्टर सामग्री के जोड़े को संग्रहीत करने के लिए एसटीपी ऑपकोड पर ध्यान दें। विस्मयादिबोधक चिह्न का भी ध्यान रखें। पॉप समतुल्य है:
एलडीपी x0, x1, [एसपी], #0
इस निर्देश के लिए कोई विस्मयादिबोधक चिह्न नहीं है. मेमोरी से दो μP रजिस्टरों में लगातार दो डेटा स्थानों को लोड करने के लिए एलडीआर के बजाय ऑपकोड एलडीपी पर ध्यान दें। यह भी याद रखें कि मेमोरी से µP रजिस्टर में कॉपी करना लोड हो रहा है, डिस्क से RAM में फ़ाइल लोड करने में भ्रमित न हों, और µP रजिस्टर से RAM में कॉपी करना स्टोर हो रहा है।
6.48 सबरूटीन
सबरूटीन कोड का एक ब्लॉक है जो वैकल्पिक रूप से कुछ तर्कों के आधार पर एक कार्य करता है और वैकल्पिक रूप से एक परिणाम देता है। परंपरा के अनुसार, R0 से R3 रजिस्टर (चार रजिस्टर) का उपयोग तर्कों (पैरामीटर) को सबरूटीन में पास करने के लिए किया जाता है, और R0 का उपयोग कॉल करने वाले को परिणाम वापस भेजने के लिए किया जाता है। एक सबरूटीन जिसे 4 से अधिक इनपुट की आवश्यकता होती है वह अतिरिक्त इनपुट के लिए स्टैक का उपयोग करता है। सबरूटीन को कॉल करने के लिए, लिंक या सशर्त शाखा निर्देश का उपयोग करें। लिंक निर्देश का सिंटैक्स है:
बीएल लेबल
जहां बीएल ऑपकोड है और लेबल सबरूटीन की शुरुआत (पता) को दर्शाता है। यह शाखा 128 एमबी के भीतर बिना शर्त, आगे या पीछे है। सशर्त शाखा निर्देश के लिए वाक्यविन्यास है:
बी.कॉन्ड लेबल
जहां cond स्थिति है, उदाहरण के लिए, eq (बराबर) या ne (बराबर नहीं)। निम्नलिखित प्रोग्राम में doadd सबरूटीन है जो दो तर्कों के मान जोड़ता है और R0 में परिणाम देता है:
क्षेत्र सबरूट, कोड, केवल पढ़ने के लिए; कोड के इस ब्लॉक को नाम दें
प्रवेश ; निष्पादित करने के लिए पहले निर्देश को चिह्नित करें
MOV r0, #10 प्रारंभ करें; पैरामीटर सेट करें
एमओवी आर1, #3
बीएल डोड; सबरूटीन को कॉल करें
MOV r0, #0x18 रोकें; angel_SWIreason_ReportException
एलडीआर आर1, =0x20026; ADP_Stopped_ApplicationExit
एसवीसी #0x123456 ; एआरएम सेमीहोस्टिंग (पूर्व में एसडब्ल्यूआई)
doadd ADD r0, r0, r1 ; सबरूटीन कोड
बीएक्स एलआर; सबरूटीन से वापसी
;
अंत ; फ़ाइल के अंत को चिह्नित करें
जोड़ने योग्य संख्याएँ दशमलव 10 और दशमलव 3 हैं। कोड के इस ब्लॉक (प्रोग्राम) में पहली दो पंक्तियों को बाद में समझाया जाएगा। अगली तीन पंक्तियाँ 10 से R0 रजिस्टर और 3 से R1 रजिस्टर भेजती हैं, और डोएड सबरूटीन को भी कॉल करती हैं। 'डोएड' वह लेबल है जो सबरूटीन की शुरुआत का पता रखता है।
सबरूटीन में केवल दो पंक्तियाँ होती हैं। पहली पंक्ति R की सामग्री 3 को R0 की सामग्री 10 में जोड़ती है जो R0 में 13 के परिणाम की अनुमति देती है। बीएक्स ऑपकोड और एलआर ऑपरेंड के साथ दूसरी पंक्ति सबरूटीन से कॉलर कोड पर लौटती है।
सही
एआरएम 64 में आरईटी ऑपकोड अभी भी सबरूटीन से संबंधित है, लेकिन 6502 में आरटीएस या x64 पर आरईटी, या एआरएम 64 में 'बीएक्स एलआर' संयोजन से अलग तरीके से संचालित होता है। एआरएम 64 में, आरईटी के लिए सिंटैक्स है:
सीधा {Xn}
यह निर्देश प्रोग्राम को एक ऐसे सबरूटीन के साथ जारी रखने का अवसर देता है जो कॉलर सबरूटीन नहीं है, या बस किसी अन्य निर्देश और उसके निम्नलिखित कोड सेगमेंट के साथ जारी रखता है। Xn एक सामान्य प्रयोजन रजिस्टर है जिसमें वह पता होता है जिस पर कार्यक्रम जारी रहना चाहिए। यह निर्देश बिना किसी शर्त के शाखा करता है। यदि Xn नहीं दिया गया है तो यह X30 की सामग्री के लिए डिफ़ॉल्ट है।
प्रक्रिया कॉल मानक
यदि प्रोग्रामर चाहता है कि उसका कोड किसी अन्य द्वारा लिखे गए कोड के साथ या कंपाइलर द्वारा निर्मित कोड के साथ इंटरैक्ट करे, तो प्रोग्रामर को रजिस्टर उपयोग के नियमों पर व्यक्ति या कंपाइलर लेखक से सहमत होना होगा। एआरएम आर्किटेक्चर के लिए, इन नियमों को प्रक्रिया कॉल मानक या पीसीएस कहा जाता है। ये दो या तीन पक्षों के बीच समझौते हैं। पीसीएस निम्नलिखित निर्दिष्ट करता है:
- फ़ंक्शन (सबरूटीन) में तर्कों को पारित करने के लिए कौन से µP रजिस्टर का उपयोग किया जाता है
- कौन से µP रजिस्टरों का उपयोग उस फ़ंक्शन पर परिणाम लौटाने के लिए किया जाता है जो कॉलिंग करता है जिसे कॉलर के रूप में जाना जाता है
- कौन सा µP उस फ़ंक्शन को पंजीकृत करता है जिसे कॉल किया जा रहा है, जिसे कैली के रूप में जाना जाता है, भ्रष्ट हो सकता है
- जो µP रजिस्टर करता है उसे कैली भ्रष्ट नहीं कर सकता
6.49 व्यवधान
एआरएम प्रोसेसर के लिए दो प्रकार के इंटरप्ट कंट्रोलर सर्किट उपलब्ध हैं:
- स्टैंडर्ड इंटरप्ट कंट्रोलर: इंटरप्ट हैंडलर इंटरप्ट कंट्रोलर में डिवाइस बिटमैप रजिस्टर को पढ़कर यह निर्धारित करता है कि किस डिवाइस को सर्विसिंग की आवश्यकता है।
- वेक्टर इंटरप्ट कंट्रोलर (VIC): इंटरप्ट को प्राथमिकता देता है और यह निर्धारित करना सरल बनाता है कि किस डिवाइस के कारण रुकावट आई। प्रत्येक इंटरप्ट के साथ एक प्राथमिकता और एक हैंडलर पते को जोड़ने के बाद, वीआईसी केवल प्रोसेसर को एक इंटरप्ट सिग्नल का दावा करता है यदि नए इंटरप्ट की प्राथमिकता वर्तमान में निष्पादित इंटरप्ट हैंडलर से अधिक है।
टिप्पणी : अपवाद का तात्पर्य त्रुटि से है। 32-बिट एआरएम कंप्यूटर के लिए वेक्टर इंटरप्ट कंट्रोलर का विवरण इस प्रकार है (64 बिट समान है):
| तालिका 6.49.1 32-बिट कंप्यूटर के लिए एआरएम वेक्टर अपवाद/व्यवधान |
|||
|---|---|---|---|
| अपवाद/व्यवधान | छोटा हाथ | पता | ऊँचा पता |
| रीसेट | रीसेट | 0x00000000 | 0xffff0000 |
| अपरिभाषित अनुदेश | यूएनडीईएफ | 0x00000004 | 0xffff0004 |
| सॉफ़्टवेयर व्यवधान | एसडब्ल्यूआई | 0x00000008 | 0xffff0008 |
| प्रीफ़ेच गर्भपात | PABT | 0x0000000C | 0xffff000C |
| गर्भपात की तिथि | DABT | 0x00000010 | 0xffff0010 |
| सुरक्षित | – | 0x00000014 | 0xffff0014 |
| व्यवधान अनुरोध | आईआरक्यू | 0x00000018 | 0xffff0018 |
| त्वरित व्यवधान अनुरोध | FIQ | 0x0000001C | 0xffff001C |
यह 6502 आर्किटेक्चर के लिए व्यवस्था की तरह दिखता है एनएमआई , बीआर , और आईआरक्यू पेज शून्य में पॉइंटर्स हो सकते हैं, और संबंधित रूटीन मेमोरी (ROM OS) में उच्च स्तर पर होते हैं। पिछली तालिका की पंक्तियों का संक्षिप्त विवरण इस प्रकार है:
रीसेट
ऐसा तब होता है जब प्रोसेसर चालू हो जाता है। यह सिस्टम को आरंभ करता है और विभिन्न प्रोसेसर मोड के लिए स्टैक सेट करता है। यह सर्वोच्च प्राथमिकता वाला अपवाद है. रीसेट हैंडलर में प्रवेश करने पर, सीपीएसआर एसवीसी मोड में है और आईआरक्यू और एफआईक्यू दोनों बिट्स को 1 पर सेट किया गया है, जो किसी भी रुकावट को छुपाता है।
गर्भपात की तिथि
दूसरी सर्वोच्च प्राथमिकता. ऐसा तब होता है जब हम किसी अमान्य पते पर पढ़ने/लिखने या गलत एक्सेस अनुमति तक पहुंचने का प्रयास करते हैं। डेटा एबॉर्ट हैंडलर में प्रवेश करने पर, आईआरक्यू अक्षम कर दिया जाएगा (आई-बिट सेट 1) और एफआईक्यू सक्षम किया जाएगा। आईआरक्यू को छुपाया जाता है, लेकिन एफआईक्यू को बेनकाब रखा जाता है।
FIQ
सर्वोच्च प्राथमिकता वाले व्यवधान, आईआरक्यू और एफआईक्यू, एफआईक्यू को संभाले जाने तक अक्षम हैं।
आईआरक्यू
उच्च प्राथमिकता वाला इंटरप्ट, आईआरक्यू हैंडलर, केवल तभी दर्ज किया जाता है जब कोई चालू एफआईक्यू और डेटा निरस्त न हो।
प्री-फ़ेच गर्भपात
यह डेटा निरस्त करने के समान है लेकिन पता लाने में विफलता पर होता है। हैंडलर में प्रवेश करने पर, आईआरक्यू अक्षम हो जाते हैं लेकिन एफआईक्यू सक्षम रहते हैं और प्री-फ़ेच गर्भपात के दौरान हो सकते हैं।
एसडब्ल्यूआई
सॉफ़्टवेयर इंटरप्ट (एसडब्ल्यूआई) अपवाद तब होता है जब एसडब्ल्यूआई निर्देश निष्पादित होता है और अन्य उच्च-प्राथमिकता वाले अपवादों में से किसी को भी चिह्नित नहीं किया गया है।
अपरिभाषित निर्देश
अपरिभाषित निर्देश अपवाद तब होता है जब कोई निर्देश जो एआरएम या थंब निर्देश सेट में नहीं है पाइपलाइन के निष्पादन चरण तक पहुंचता है और अन्य अपवादों में से कोई भी चिह्नित नहीं किया गया है। यह एसडब्ल्यूआई जैसी ही प्राथमिकता है क्योंकि एक समय में एक ही हो सकता है। इसका मतलब यह है कि जो निर्देश निष्पादित किया जा रहा है वह एक ही समय में एक एसडब्ल्यूआई निर्देश और एक अपरिभाषित निर्देश दोनों नहीं हो सकता है।
एआरएम अपवाद हैंडलिंग
अपवाद होने पर निम्नलिखित घटनाएँ घटित होती हैं:
- सीपीएसआर को अपवाद मोड के एसपीएसआर में संग्रहीत करें।
- पीसी को अपवाद मोड के एलआर में संग्रहीत किया जाता है।
- लिंक रजिस्टर वर्तमान निर्देश के आधार पर एक विशिष्ट पते पर सेट किया गया है। उदाहरण के लिए: आईएसआर के लिए, एलआर = अंतिम निष्पादित निर्देश + 8।
- अपवाद के बारे में सीपीएसआर को अद्यतन करें।
- पीसी को अपवाद हैंडलर के पते पर सेट करें।
6.5 निर्देश और डेटा
डेटा वेरिएबल्स (उनके मूल्यों के साथ लेबल) और सरणी और अन्य संरचनाओं को संदर्भित करता है जो सरणी के समान हैं। स्ट्रिंग वर्णों की एक सरणी की तरह है। पिछले अध्यायों में से एक में पूर्णांकों की एक सरणी देखी गई है। निर्देश ऑपकोड और उनके ऑपरेंड को संदर्भित करते हैं। एक प्रोग्राम को ऑपकोड और मेमोरी के एक जारी अनुभाग में मिश्रित डेटा के साथ लिखा जा सकता है। उस दृष्टिकोण में नुकसान हैं लेकिन इसकी अनुशंसा नहीं की जाती है।
एक प्रोग्राम को पहले निर्देशों के साथ लिखा जाना चाहिए, उसके बाद डेटा (डेटम का बहुवचन डेटा है) के साथ लिखा जाना चाहिए। निर्देशों और डेटा के बीच का अंतर केवल कुछ बाइट्स का हो सकता है। किसी प्रोग्राम के लिए, निर्देश और डेटा दोनों मेमोरी में एक या दो अलग-अलग अनुभागों में हो सकते हैं।
6.6 हार्वर्ड वास्तुकला
शुरुआती कंप्यूटरों में से एक को हार्वर्ड मार्क I (1944) कहा जाता है। एक सख्त हार्वर्ड आर्किटेक्चर प्रोग्राम निर्देशों के लिए एक एड्रेस स्पेस और डेटा के लिए एक अलग एड्रेस स्पेस का उपयोग करता है। इसका मतलब है कि दो अलग-अलग यादें हैं। निम्नलिखित वास्तुकला को दर्शाता है:
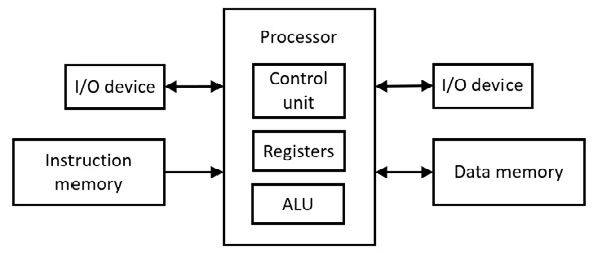
चित्र 6.71 हार्वर्ड वास्तुकला
नियंत्रण इकाई निर्देश डिकोडिंग करती है। अंकगणित तर्क इकाई (एएलयू) संयोजन तर्क (गेट्स) के साथ अंकगणितीय संचालन करती है। ALU तार्किक संचालन (जैसे शिफ्टिंग) भी करता है।
6502 माइक्रोप्रोसेसर के साथ, एक निर्देश पहले माइक्रोप्रोसेसर (नियंत्रण इकाई) को जाता है, इससे पहले कि डेटम (डेटा के लिए एकवचन) इंटरैक्ट करने से पहले µP रजिस्टर में जाता है। इसके लिए कम से कम दो क्लॉक पल्स की आवश्यकता होती है और यह निर्देश और डेटाम तक एक साथ पहुंच नहीं है। दूसरी ओर, हार्वर्ड आर्किटेक्चर निर्देशों और डेटा तक एक साथ पहुंच प्रदान करता है, निर्देश और डेटाम दोनों एक ही समय में µP में प्रवेश करते हैं (यूनिट को नियंत्रित करने के लिए ऑपकोड और µP रजिस्टर में डेटाम), कम से कम एक क्लॉक पल्स की बचत करते हैं। यह समानता का एक रूप है. समानता के इस रूप का उपयोग आधुनिक मदरबोर्ड में हार्डवेयर कैश में किया जाता है (निम्नलिखित चर्चा देखें)।
6.7 कैश मेमोरी
कैश मेमोरी (रैम) एक उच्च गति वाला मेमोरी क्षेत्र है (मुख्य मेमोरी की गति की तुलना में) जो भविष्य में उपयोग के लिए प्रोग्राम निर्देशों या डेटा को अस्थायी रूप से संग्रहीत करता है। कैश मेमोरी मुख्य मेमोरी की तुलना में तेजी से काम करती है। आमतौर पर, ये निर्देश या डेटा आइटम हाल की मुख्य मेमोरी से पुनर्प्राप्त किए जाते हैं और शीघ्र ही इनकी दोबारा आवश्यकता पड़ने की संभावना होती है। कैश मेमोरी का प्राथमिक उद्देश्य समान मुख्य मेमोरी स्थानों तक बार-बार पहुंचने की गति को बढ़ाना है। प्रभावी होने के लिए, कैश्ड आइटम तक पहुंच निर्देशों या डेटा के मूल स्रोत तक पहुंचने की तुलना में काफी तेज होनी चाहिए जिसे बैकिंग स्टोर कहा जाता है।
जब कैशिंग उपयोग में होती है, तो मुख्य मेमोरी स्थान तक पहुंचने का प्रत्येक प्रयास कैश की खोज से शुरू होता है। यदि अनुरोधित वस्तु मौजूद है, तो प्रोसेसर तुरंत उसे पुनः प्राप्त करता है और उसका उपयोग करता है। इसे कैश हिट कहा जाता है. यदि कैश खोज असफल होती है (कैश छूट जाती है), तो निर्देश या डेटा आइटम को बैकिंग स्टोर (मुख्य मेमोरी) से पुनर्प्राप्त किया जाना चाहिए। अनुरोधित वस्तु को पुनः प्राप्त करने की प्रक्रिया में, निकट भविष्य में उपयोग के लिए कैश में एक प्रति जोड़ दी जाती है।
मेमोरी प्रबंधन इकाई
मेमोरी मैनेजमेंट यूनिट (एमएमयू) एक सर्किट है जो मदरबोर्ड पर मुख्य मेमोरी और संबंधित मेमोरी रजिस्टरों का प्रबंधन करता है। अतीत में, यह मदरबोर्ड पर एक अलग एकीकृत सर्किट था; लेकिन आज, यह आम तौर पर माइक्रोप्रोसेसर का हिस्सा है। एमएमयू को कैश (सर्किट) का भी प्रबंधन करना चाहिए जो आज माइक्रोप्रोसेसर का भी एक हिस्सा है। कैश सर्किट अतीत में एक अलग एकीकृत सर्किट है।
स्थैतिक रैम
स्टेटिक रैम (एसआरएएम) में डीआरएएम की तुलना में काफी तेज पहुंच समय होता है, हालांकि यह काफी अधिक जटिल सर्किटरी की कीमत पर होता है। SRAM बिट कोशिकाएं एकीकृत सर्किट डाई पर DRAM डिवाइस की कोशिकाओं की तुलना में बहुत अधिक जगह लेती हैं जो समान मात्रा में डेटा संग्रहीत करने में सक्षम हैं। मुख्य मेमोरी (RAM) में आमतौर पर DRAM (डायनामिक रैम) होती है।
कैश मेमोरी कंप्यूटर के प्रदर्शन में सुधार करती है क्योंकि ऑपरेटिंग सिस्टम और एप्लिकेशन द्वारा निष्पादित कई एल्गोरिदम संदर्भ के इलाके को प्रदर्शित करते हैं। संदर्भ का स्थान उस डेटा के पुन: उपयोग को संदर्भित करता है जिसे हाल ही में एक्सेस किया गया है। इसे टेम्पोरल लोकैलिटी कहा जाता है। आधुनिक मदरबोर्ड पर, कैश मेमोरी माइक्रोप्रोसेसर के समान एकीकृत सर्किट में होती है। मुख्य मेमोरी (DRAM) दूर है और बसों के माध्यम से पहुंच योग्य है। संदर्भ का स्थान स्थानिक इलाके को भी संदर्भित करता है। स्थानिक इलाके का संबंध भौतिक निकटता के कारण डेटा पहुंच की उच्च गति से है।
एक नियम के रूप में, कैश मेमोरी क्षेत्र बैकिंग स्टोर (मुख्य मेमोरी) की तुलना में छोटे (बाइट स्थानों की संख्या में) होते हैं। कैश मेमोरी डिवाइस अधिकतम गति के लिए डिज़ाइन किए गए हैं, जिसका आम तौर पर मतलब है कि वे बैकिंग स्टोर में उपयोग की जाने वाली डेटा स्टोरेज तकनीक की तुलना में प्रति बिट अधिक जटिल और महंगे हैं। अपने सीमित आकार के कारण, कैश मेमोरी डिवाइस जल्दी भर जाते हैं। जब कैश में नई प्रविष्टि संग्रहीत करने के लिए कोई स्थान उपलब्ध नहीं होता है, तो पुरानी प्रविष्टि को हटा दिया जाना चाहिए। कैश नियंत्रक यह चुनने के लिए कैश रिप्लेसमेंट नीति का उपयोग करता है कि कौन सी कैश प्रविष्टि नई प्रविष्टि द्वारा अधिलेखित की जाएगी।
माइक्रोप्रोसेसर कैश मेमोरी का लक्ष्य समय के साथ कैश हिट के प्रतिशत को अधिकतम करना है, इस प्रकार निर्देश निष्पादन की उच्चतम निरंतर दर प्रदान करना है। इस उद्देश्य को प्राप्त करने के लिए, कैशिंग लॉजिक को यह निर्धारित करना होगा कि कौन से निर्देश और डेटा कैश में रखे जाएंगे और निकट भविष्य में उपयोग के लिए बनाए रखे जाएंगे।
प्रोसेसर के कैशिंग लॉजिक में यह आश्वासन नहीं होता है कि एक बार कैश में डाले जाने के बाद कैश्ड डेटा आइटम का दोबारा उपयोग नहीं किया जाएगा।
कैशिंग का तर्क इस संभावना पर निर्भर करता है कि अस्थायी (समय के साथ दोहराव) और स्थानिक (अंतरिक्ष) इलाके के कारण, बहुत अच्छी संभावना है कि कैश्ड डेटा को निकट भविष्य में एक्सेस किया जाएगा। आधुनिक प्रोसेसर पर व्यावहारिक कार्यान्वयन में, कैश हिट आमतौर पर 95 से 97 प्रतिशत मेमोरी एक्सेस पर होती है। चूँकि कैश मेमोरी की विलंबता DRAM की विलंबता का एक छोटा सा अंश है, एक उच्च कैश हिट दर कैश-मुक्त डिज़ाइन की तुलना में पर्याप्त प्रदर्शन सुधार की ओर ले जाती है।
कैश के साथ कुछ समानता
जैसा कि पहले उल्लेख किया गया है, मेमोरी में एक अच्छे प्रोग्राम में निर्देश डेटा से अलग होते हैं। कुछ कैश सिस्टम में, प्रोसेसर के 'बाएं' पर एक कैश सर्किट होता है और प्रोसेसर के 'दाएं' पर एक और कैश सर्किट होता है। बायां कैश किसी प्रोग्राम (या एप्लिकेशन) के निर्देशों को संभालता है और दायां कैश उसी प्रोग्राम (या उसी एप्लिकेशन) के डेटा को संभालता है। इससे गति में बेहतर वृद्धि होती है।
6.8 प्रक्रियाएँ और सूत्र
सीआईएससी और आरआईएससी दोनों कंप्यूटरों में प्रक्रियाएं होती हैं। सॉफ्टवेयर पर एक प्रक्रिया चल रही है. एक प्रोग्राम जो चल रहा है (निष्पादित हो रहा है) एक प्रक्रिया है। ऑपरेटिंग सिस्टम अपने स्वयं के प्रोग्राम के साथ आता है। जब कंप्यूटर चल रहा होता है, तो ऑपरेटिंग सिस्टम के प्रोग्राम भी चल रहे होते हैं जो कंप्यूटर को काम करने में सक्षम बनाते हैं। ये ऑपरेटिंग सिस्टम प्रक्रियाएं हैं। उपयोगकर्ता या प्रोग्रामर अपना स्वयं का प्रोग्राम लिख सकता है। जब उपयोगकर्ता का प्रोग्राम चल रहा होता है, तो यह एक प्रक्रिया है। इससे कोई फर्क नहीं पड़ता कि प्रोग्राम असेंबली भाषा में लिखा गया है या C या C++ जैसी उच्च स्तरीय भाषा में। सभी प्रक्रियाओं (उपयोगकर्ता या OS) को 'अनुसूचक' नामक एक अन्य प्रक्रिया द्वारा प्रबंधित किया जाता है।
एक धागा एक प्रक्रिया से संबंधित उप-प्रक्रिया की तरह है। एक प्रक्रिया शुरू हो सकती है और धागों में विभाजित हो सकती है और फिर भी एक प्रक्रिया के रूप में जारी रहती है। बिना थ्रेड वाली प्रक्रिया को मुख्य थ्रेड माना जा सकता है। प्रक्रियाओं और उनके थ्रेड्स को एक ही शेड्यूलर द्वारा प्रबंधित किया जाता है। शेड्यूलर स्वयं एक प्रोग्राम है जब वह ओएस डिस्क में रेजिडेंट होता है। मेमोरी में चलते समय, शेड्यूलर एक प्रक्रिया है।
6.9 मल्टीप्रोसेसिंग
थ्रेड्स को लगभग प्रक्रियाओं की तरह प्रबंधित किया जाता है। मल्टीप्रोसेसिंग का अर्थ है एक ही समय में एक से अधिक प्रोसेस चलाना। ऐसे कंप्यूटर हैं जिनमें केवल एक माइक्रोप्रोसेसर होता है। एक से अधिक माइक्रोप्रोसेसर वाले कंप्यूटर होते हैं। एकल माइक्रोप्रोसेसर के साथ, प्रक्रियाएं और/या थ्रेड इंटरलीविंग (या टाइम-स्लाइसिंग) तरीके से एक ही माइक्रोप्रोसेसर का उपयोग करते हैं। इसका मतलब है कि एक प्रक्रिया प्रोसेसर का उपयोग करती है और बिना ख़त्म हुए रुक जाती है। कोई अन्य प्रक्रिया या थ्रेड प्रोसेसर का उपयोग करता है और बिना ख़त्म हुए रुक जाता है। फिर, एक अन्य प्रक्रिया या थ्रेड माइक्रोप्रोसेसर का उपयोग करता है और बिना परिष्करण के बंद हो जाता है। यह तब तक जारी रहता है जब तक शेड्यूलर द्वारा कतारबद्ध सभी प्रक्रियाओं और थ्रेड्स में प्रोसेसर का हिस्सा नहीं हो जाता। इसे समवर्ती मल्टीप्रोसेसिंग कहा जाता है।
जब एक से अधिक माइक्रोप्रोसेसर होते हैं, तो समवर्ती के विपरीत, समानांतर मल्टीप्रोसेसिंग होती है। इस मामले में, प्रत्येक प्रोसेसर एक विशेष प्रक्रिया या थ्रेड चलाता है, जो दूसरे प्रोसेसर द्वारा चलाए जा रहे प्रक्रिया से भिन्न होता है। एक ही मदरबोर्ड पर सभी प्रोसेसर एक ही समय में समानांतर मल्टीप्रोसेसिंग में अपनी अलग-अलग प्रक्रियाएं और/या अलग-अलग थ्रेड चलाते हैं। समानांतर मल्टीप्रोसेसिंग में प्रक्रियाओं और थ्रेड्स को अभी भी शेड्यूलर द्वारा प्रबंधित किया जाता है। समांतर मल्टीप्रोसेसिंग समवर्ती मल्टीप्रोसेसिंग से तेज़ है।
इस बिंदु पर, पाठक आश्चर्यचकित हो सकता है कि समवर्ती प्रसंस्करण की तुलना में समानांतर प्रसंस्करण कितना तेज़ है। ऐसा इसलिए है क्योंकि प्रोसेसर एक ही मेमोरी और इनपुट/आउटपुट पोर्ट साझा करते हैं (अलग-अलग समय पर उपयोग करना पड़ता है)। खैर, कैश के उपयोग से, मदरबोर्ड का समग्र संचालन तेज़ होता है।
6.10 पेजिंग
मेमोरी मैनेजमेंट यूनिट (एमएमयू) एक सर्किट है जो माइक्रोप्रोसेसर या माइक्रोप्रोसेसर चिप के करीब होता है। यह मेमोरी मैप या पेजिंग और अन्य मेमोरी समस्याओं को संभालता है। न तो 6502 µP और न ही कमोडोर-64 कंप्यूटर में एमएमयू है (हालाँकि कमोडोर-64 में अभी भी कुछ मेमोरी प्रबंधन है)। कमोडोर-64 पेजिंग द्वारा मेमोरी को संभालता है जहां प्रत्येक पृष्ठ 256 है 10 बाइट्स लंबे (100 16 बाइट्स लंबे)। पेजिंग द्वारा मेमोरी को संभालना इसके लिए अनिवार्य नहीं था। इसमें अभी भी केवल एक मेमोरी मैप और फिर ऐसे प्रोग्राम हो सकते हैं जो अपने अलग-अलग निर्दिष्ट क्षेत्रों में खुद को फिट करते हैं। खैर, पेजिंग कई मेमोरी अनुभागों के बिना मेमोरी का कुशल उपयोग प्रदान करने का एक तरीका है जिसमें कोई डेटा या प्रोग्राम नहीं हो सकता है।
x86 386 कंप्यूटर आर्किटेक्चर 1985 में जारी किया गया था। एड्रेस बस 32-बिट चौड़ी है। तो, कुल 2 32 = 4,294,967,296 पता स्थान संभव है। यह पता स्थान 1,048,576 पृष्ठों = 1,024 KB पृष्ठों में विभाजित है। पृष्ठों की इस संख्या के साथ, एक पृष्ठ में 4,096 बाइट्स = 4 KB होते हैं। निम्न तालिका x86 32-बिट आर्किटेक्चर के लिए भौतिक पता पृष्ठ दिखाती है:
| तालिका 6.10.1 x86 आर्किटेक्चर के लिए भौतिक पतायोग्य पृष्ठ |
||
|---|---|---|
| आधार 16 पते | पृष्ठों | आधार 10 पते |
| FFFFF000 - FFFFFFFF | पृष्ठ 1,048,575 | 4,294,963,200 – 4,294,967,295 |
| FFFFE000 - FFFFEFFF | पृष्ठ 1,044,479 | 4,294,959,104 – 4,294,963,199 |
| FFFFD000 - FFFFDFFF | पृष्ठ 1,040,383 | 4,294,955,008 – 4,294,959,103 |
| | | | |
| | | |
| | | |
| 00002000 - 00002FFF | पेज 2 | 8,192 – 12,288 |
| 00001000 - 00001FFF | पृष्ठ 1 | 4,096 – 8,191 |
| 00000000 - 00000FFF | पृष्ठ 0 | 0-4,095 |
आज एक एप्लिकेशन में एक से अधिक प्रोग्राम शामिल होते हैं। एक प्रोग्राम एक पेज से कम (4096 से कम) ले सकता है या दो या अधिक पेज ले सकता है। तो, एक एप्लिकेशन एक या अधिक पृष्ठ ले सकता है जहां प्रत्येक पृष्ठ 4096 बाइट लंबा है। अलग-अलग लोग एक आवेदन पत्र लिख सकते हैं, प्रत्येक व्यक्ति को एक या अधिक पृष्ठ सौंपे गए हैं।
ध्यान दें कि पेज 0 00000000H से 00000FFF तक है
पेज 1 00001000H से 00001FFFH तक है, पेज 2 00002000 तक है एच - 00002FFF एच , और इसी तरह। 32-बिट कंप्यूटर के लिए, भौतिक पेज एड्रेसिंग के लिए प्रोसेसर में दो 32-बिट रजिस्टर होते हैं: एक बेस एड्रेस के लिए और दूसरा इंडेक्स एड्रेस के लिए। उदाहरण के लिए, पेज 2 के बाइट स्थानों तक पहुंचने के लिए, आधार पते के लिए रजिस्टर 00002 होना चाहिए एच जो पेज 2 के आरंभिक पतों के लिए पहले 20 बिट्स (बाएं से) है। बाकी बिट्स 000 की रेंज में हैं एच एफएफएफ को एच रजिस्टर में हैं जिसे 'इंडेक्स रजिस्टर' कहा जाता है। इसलिए, इंडेक्स रजिस्टर में सामग्री को 000 से बढ़ाकर पेज के सभी बाइट्स तक पहुंचा जा सकता है एच एफएफएफ को एच . प्रभावी पता प्राप्त करने के लिए इंडेक्स रजिस्टर की सामग्री को उस सामग्री में जोड़ा जाता है जो आधार रजिस्टर में नहीं बदलती है। यह इंडेक्स एड्रेसिंग स्कीम अन्य पेजों के लिए सही है।
हालाँकि, यह वास्तव में ऐसा नहीं है कि प्रत्येक पृष्ठ के लिए असेंबली भाषा प्रोग्राम कैसे लिखा जाता है। प्रत्येक पेज के लिए, प्रोग्रामर पेज 000 से शुरू होने वाला कोड लिखता है एच पेज एफएफएफ के लिए एच . चूंकि विभिन्न पृष्ठों में कोड जुड़े हुए हैं, कंपाइलर विभिन्न पृष्ठों में सभी संबंधित पतों को जोड़ने के लिए इंडेक्स एड्रेसिंग का उपयोग करता है। उदाहरण के लिए, मान लें कि पेज 0, पेज 1 और पेज 2 एक ही एप्लिकेशन के लिए हैं और प्रत्येक में 555 हैं एच जो एड्रेस एक दूसरे से जुड़े होते हैं, कंपाइलर इस तरह से कंपाइल करता है कि जब 555 एच पेज 0 का एक्सेस करना है, 00000 एच आधार रजिस्टर में होगा और 555 एच इंडेक्स रजिस्टर में होगा. जब 555 एच पृष्ठ 1 का उपयोग करना है, 00001 एच आधार रजिस्टर में होगा और 555 एच इंडेक्स रजिस्टर में होगा. जब 555 एच पृष्ठ 2 का उपयोग करना है, 00002 एच बेस रजिस्टर में होगा और 555H इंडेक्स रजिस्टर में होगा। यह संभव है क्योंकि पते को लेबल (चर) का उपयोग करके पहचाना जा सकता है। विभिन्न प्रोग्रामर को अलग-अलग कनेक्टिंग पतों के लिए उपयोग किए जाने वाले लेबल के नाम पर सहमत होना होगा।
पेज वर्चुअल मेमोरी
पेजिंग, जैसा कि पहले बताया गया है, को एक तकनीक में मेमोरी के आकार को बढ़ाने के लिए संशोधित किया जा सकता है जिसे 'पेज वर्चुअल मेमोरी' कहा जाता है। यह मानते हुए कि सभी भौतिक मेमोरी पृष्ठों में, जैसा कि पहले बताया गया है, कुछ न कुछ (निर्देश और डेटा) है, सभी पृष्ठ वर्तमान में सक्रिय नहीं हैं। जो पेज वर्तमान में सक्रिय नहीं हैं उन्हें हार्ड डिस्क पर भेज दिया जाता है और हार्ड डिस्क के उन पेजों से बदल दिया जाता है जिन्हें चलाने की आवश्यकता होती है। इस प्रकार, मेमोरी का आकार बढ़ जाता है। जैसे-जैसे कंप्यूटर काम करना जारी रखता है, जो पेज निष्क्रिय हो जाते हैं उन्हें हार्ड डिस्क के पेजों के साथ बदल दिया जाता है, जो अभी भी मेमोरी से डिस्क पर भेजे गए पेज हो सकते हैं। यह सब मेमोरी मैनेजमेंट यूनिट (एमएमयू) द्वारा किया जाता है।
6.11 समस्याएँ
पाठक को अगले अध्याय पर जाने से पहले एक अध्याय की सभी समस्याओं को हल करने की सलाह दी जाती है।
1) सीआईएससी और आरआईएससी कंप्यूटर आर्किटेक्चर की समानताएं और अंतर बताएं। एसआईएससी और आरआईएससी कंप्यूटर का एक-एक उदाहरण बताइए।
2) ए) बिट्स के संदर्भ में सीआईएससी कंप्यूटर के निम्नलिखित नाम क्या हैं: बाइट, वर्ड, डबलवर्ड, क्वाडवर्ड और डबल क्वाडवर्ड।
बी) बिट्स के संदर्भ में आरआईएससी कंप्यूटर के लिए निम्नलिखित नाम क्या हैं: बाइट, हाफवर्ड, वर्ड और डबलवर्ड।
ग) हां या नहीं। क्या सीआईएससी और आरआईएससी आर्किटेक्चर दोनों में डबलवर्ड और क्वाडवर्ड का मतलब समान है?
3 ए) x64 के लिए, असेंबली भाषा निर्देशों के लिए बाइट्स की संख्या क्या से लेकर कितनी तक होती है?
बी) क्या एआरएम 64 के लिए सभी असेंबली भाषा निर्देशों के लिए बाइट्स की संख्या तय है? यदि हां, तो सभी निर्देशों के लिए बाइट्स की संख्या क्या है?
4) x64 के लिए सबसे अधिक उपयोग किए जाने वाले असेंबली भाषा निर्देशों और उनके अर्थों की सूची बनाएं।
5) एआरएम 64 के लिए सबसे अधिक उपयोग किए जाने वाले असेंबली भाषा निर्देशों और उनके अर्थों की सूची बनाएं।
6) पुराने कंप्यूटर हार्वर्ड आर्किटेक्चर का एक लेबल ब्लॉक आरेख बनाएं। बताएं कि आधुनिक कंप्यूटर के कैश में इसके निर्देशों और डेटा सुविधाओं का उपयोग कैसे किया जाता है।
7) एक प्रक्रिया और एक थ्रेड के बीच अंतर करें और उस प्रक्रिया का नाम दें जो अधिकांश कंप्यूटर सिस्टम में प्रक्रियाओं और थ्रेड को संभालती है।
8) संक्षेप में बताएं कि मल्टीप्रोसेसिंग क्या है।
9) ए) x86 386 μP कंप्यूटर आर्किटेक्चर पर लागू पेजिंग की व्याख्या करें।
ख) संपूर्ण मेमोरी का आकार बढ़ाने के लिए इस पेजिंग को कैसे संशोधित किया जा सकता है?