उदाहरण 1: आर में ग्रेप() फ़ंक्शन का उपयोग करके स्ट्रिंग से पैटर्न की स्थिति प्राप्त करें
स्ट्रिंग से निर्दिष्ट पैटर्न की स्थिति निकालने के लिए, R का grep() फ़ंक्शन नियोजित किया जाता है।
grep('i+', c('fix', 'split', 'corn n', 'paint'), perl=TRUE, value=FALSE)यहां, हम grep() फ़ंक्शन को नियोजित करते हैं जहां '+i' पैटर्न को स्ट्रिंग्स के वेक्टर के भीतर मिलान किए जाने वाले तर्क के रूप में निर्दिष्ट किया जाता है। हम कैरेक्टर वेक्टर सेट करते हैं जिसमें चार स्ट्रिंग होते हैं। उसके बाद, हम 'पर्ल' तर्क को TRUE मान के साथ सेट करते हैं जो इंगित करता है कि R एक पर्ल संगत रेगुलर एक्सप्रेशन लाइब्रेरी का उपयोग करता है, और 'मान' पैरामीटर को 'FALSE' मान के साथ निर्दिष्ट किया जाता है जिसका उपयोग तत्वों के सूचकांक को पुनः प्राप्त करने के लिए किया जाता है। वेक्टर में जो पैटर्न से मेल खाता है।
वेक्टर वर्णों की प्रत्येक स्ट्रिंग से '+i' पैटर्न स्थिति निम्नलिखित आउटपुट में प्रदर्शित होती है:

उदाहरण 2: आर में ग्रेगएक्सपीआर () फ़ंक्शन का उपयोग करके पैटर्न का मिलान करें
इसके बाद, हम gregexpr() फ़ंक्शन का उपयोग करके R में विशेष स्ट्रिंग की लंबाई के साथ सूचकांक स्थिति प्राप्त करते हैं।
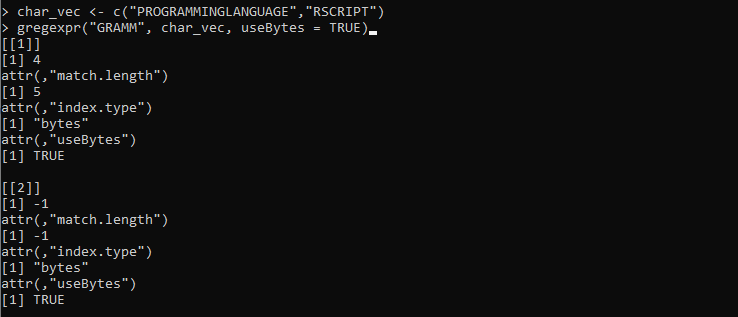
char_vec <- c('प्रोग्रामिंगभाषा','आरएसक्रिप्ट')
gregexpr ('GRAMM', char_vec, useBytes = TRUE)
यहां, हम 'char_vect' वेरिएबल सेट करते हैं जहां स्ट्रिंग्स को विभिन्न वर्णों के साथ प्रदान किया जाता है। उसके बाद, हम gregexpr() फ़ंक्शन को परिभाषित करते हैं जो 'GRAMM' स्ट्रिंग पैटर्न को 'char_vec' में संग्रहीत स्ट्रिंग्स से मिलान करने के लिए लेता है। फिर, हम 'TRUE' मान के साथ यूज़बाइट्स पैरामीटर सेट करते हैं। यह पैरामीटर इंगित करता है कि मिलान वर्ण-दर-वर्ण के बजाय बाइट-दर-बाइट प्राप्त किया जाना चाहिए।
निम्नलिखित आउटपुट जो gregexpr() फ़ंक्शन से पुनर्प्राप्त किया गया है, दोनों वेक्टर स्ट्रिंग्स के सूचकांक और लंबाई का प्रतिनिधित्व करता है:
उदाहरण 3: R में Nchar() फ़ंक्शन का उपयोग करके स्ट्रिंग में कुल वर्णों की गणना करें
nchar() विधि जिसे हम निम्नलिखित में लागू करते हैं, हमें यह निर्धारित करने की भी अनुमति देती है कि स्ट्रिंग में कितने अक्षर हैं:
Res <- nchar('प्रत्येक वर्ण की गणना करें')प्रिंट(Res)
यहां, हम nchar() विधि को कॉल करते हैं जो 'Res' वेरिएबल के भीतर सेट है। nchar() विधि वर्णों की लंबी स्ट्रिंग के साथ प्रदान की जाती है जिसे nchar() विधि द्वारा गिना जाता है और निर्दिष्ट स्ट्रिंग में काउंटर वर्णों की संख्या प्रदान की जाती है। फिर, हम nchar() विधि के परिणाम देखने के लिए 'Res' वेरिएबल को print() विधि में पास करते हैं।
परिणाम निम्नलिखित आउटपुट में प्राप्त होता है जो दर्शाता है कि निर्दिष्ट स्ट्रिंग में 20 अक्षर हैं:

उदाहरण 4: आर में सबस्ट्रिंग() फ़ंक्शन का उपयोग करके स्ट्रिंग से सबस्ट्रिंग निकालें
हम स्ट्रिंग से विशिष्ट सबस्ट्रिंग निकालने के लिए 'स्टार्ट' और 'स्टॉप' तर्कों के साथ सबस्ट्रिंग() विधि का उपयोग करते हैं।
str <- सबस्ट्रिंग ('सुबह', 2, 4)प्रिंट(str)
यहां, हमारे पास एक 'str' वेरिएबल है जहां सबस्ट्रिंग() विधि को कॉल किया जाता है। सबस्ट्रिंग () विधि 'MORNING' स्ट्रिंग को पहले तर्क के रूप में लेती है और '2' का मान दूसरे तर्क के रूप में लेती है जो इंगित करता है कि स्ट्रिंग से दूसरा अक्षर निकाला जाना है, और '4' तर्क का मान इंगित करता है कि चौथा अक्षर निकालना है. सबस्ट्रिंग() विधि निर्दिष्ट स्थिति के बीच स्ट्रिंग से वर्णों को निकालती है।
निम्नलिखित आउटपुट निकाले गए सबस्ट्रिंग को प्रदर्शित करता है जो स्ट्रिंग में दूसरे और चौथे स्थान के बीच स्थित है:

उदाहरण 5: आर में पेस्ट() फ़ंक्शन का उपयोग करके स्ट्रिंग को संयोजित करें
आर में पेस्ट() फ़ंक्शन का उपयोग स्ट्रिंग मैनिपुलेशन के लिए भी किया जाता है जो सीमांकक को अलग करके निर्दिष्ट स्ट्रिंग को जोड़ता है।
संदेश1 <- 'सामग्री'संदेश2 <- 'लिखना'
पेस्ट करें(msg1,msg2)
यहां, हम क्रमशः 'msg1' और 'msg2' वेरिएबल्स के लिए स्ट्रिंग निर्दिष्ट करते हैं। फिर, हम प्रदान की गई स्ट्रिंग को एक स्ट्रिंग में संयोजित करने के लिए R की पेस्ट() विधि का उपयोग करते हैं। पेस्ट() विधि स्ट्रिंग्स वेरिएबल को एक तर्क के रूप में लेती है और स्ट्रिंग्स के बीच डिफ़ॉल्ट स्थान के साथ एकल स्ट्रिंग लौटाती है।
पेस्ट() विधि के निष्पादन पर, आउटपुट रिक्त स्थान के साथ एकल स्ट्रिंग का प्रतिनिधित्व करता है।

उदाहरण 6: आर में सबस्ट्रिंग() फ़ंक्शन का उपयोग करके स्ट्रिंग को संशोधित करें
इसके अलावा, हम निम्नलिखित स्क्रिप्ट का उपयोग करके सबस्ट्रिंग() फ़ंक्शन का उपयोग करके स्ट्रिंग में सबस्ट्रिंग या किसी भी वर्ण को जोड़कर स्ट्रिंग को अपडेट भी कर सकते हैं:
str1 <- 'नायक'सबस्ट्रिंग(str1, 5, 6) <- 'ic'
cat(' संशोधित स्ट्रिंग:', str1)
हम 'हीरोज़' स्ट्रिंग को 'str1' वेरिएबल के भीतर सेट करते हैं। फिर, हम सबस्ट्रिंग() विधि को तैनात करते हैं जहां 'str1' को सबस्ट्रिंग के 'स्टार्ट' और 'स्टॉप' इंडेक्स मानों के साथ निर्दिष्ट किया जाता है। सबस्ट्रिंग() विधि को 'iz' सबस्ट्रिंग के साथ असाइन किया गया है जिसे दिए गए स्ट्रिंग के लिए फ़ंक्शन के भीतर निर्दिष्ट स्थिति पर रखा गया है। उसके बाद, हम R के cat() फ़ंक्शन का उपयोग करते हैं जो अद्यतन स्ट्रिंग मान का प्रतिनिधित्व करता है।
स्ट्रिंग को प्रदर्शित करने वाला आउटपुट सबस्ट्रिंग () विधि का उपयोग करके नए के साथ अपडेट किया जाता है:

उदाहरण 7: आर में फ़ॉर्मेट() फ़ंक्शन का उपयोग करके स्ट्रिंग को प्रारूपित करें
हालाँकि, R में स्ट्रिंग मैनिपुलेशन ऑपरेशन में स्ट्रिंग को तदनुसार स्वरूपित करना भी शामिल है। इसके लिए, हम प्रारूप() फ़ंक्शन का उपयोग करते हैं जहां स्ट्रिंग को संरेखित किया जा सकता है और विशिष्ट स्ट्रिंग की चौड़ाई निर्धारित की जा सकती है।
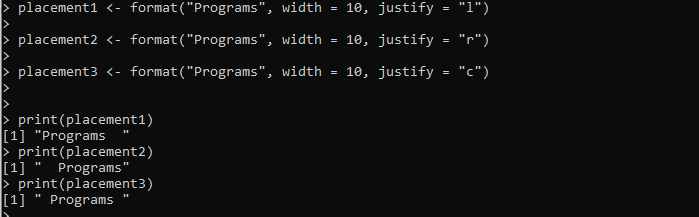
प्लेसमेंट1 <- प्रारूप ('प्रोग्राम', चौड़ाई = 10, औचित्य = 'एल')प्लेसमेंट2 <- प्रारूप ('प्रोग्राम', चौड़ाई = 10, औचित्य = 'आर')
प्लेसमेंट3 <- प्रारूप ('प्रोग्राम', चौड़ाई = 10, औचित्य = 'सी')
प्रिंट(प्लेसमेंट1)
प्रिंट(प्लेसमेंट2)
प्रिंट(प्लेसमेंट3)
यहां, हम 'प्लेसमेंट1' वेरिएबल सेट करते हैं जो प्रारूप() विधि के साथ प्रदान किया गया है। हम 'प्रोग्राम्स' स्ट्रिंग को प्रारूप() विधि में स्वरूपित करने के लिए पास करते हैं। चौड़ाई सेट की गई है, और स्ट्रिंग का संरेखण 'औचित्य' तर्क का उपयोग करके बाईं ओर सेट किया गया है। इसी तरह, हम दो और वेरिएबल, 'प्लेसमेंट2' और 'प्लेसमेंट2' बनाते हैं, और तदनुसार प्रदान की गई स्ट्रिंग को प्रारूपित करने के लिए प्रारूप() विधि लागू करते हैं।
आउटपुट निम्न छवि में एक ही स्ट्रिंग के लिए बाएँ, दाएँ और केंद्र संरेखण सहित तीन स्वरूपण शैलियाँ प्रदर्शित करता है:
उदाहरण 8: स्ट्रिंग को आर में निचले और ऊपरी मामलों में बदलें
इसके अतिरिक्त, हम निम्नानुसार tolower() और toupper() फ़ंक्शंस का उपयोग करके स्ट्रिंग को लोअर केस और अपर केस में भी बदल सकते हैं:
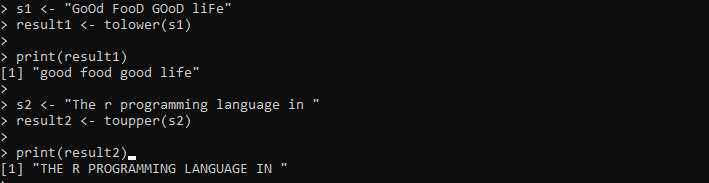
s1 <- 'अच्छा भोजन, अच्छा जीवन'परिणाम1 <- निचला(एस1)
प्रिंट(परिणाम1)
s2 <- 'आर प्रोग्रामिंग भाषा'
परिणाम2 <- टॉपर(एस2)
प्रिंट(परिणाम2)
यहां, हम वह स्ट्रिंग प्रदान करते हैं जिसमें अपरकेस और लोअरकेस वर्ण हैं। उसके बाद, स्ट्रिंग को 's1' वेरिएबल में रखा जाता है। फिर, हम tolower() विधि को कॉल करते हैं और स्ट्रिंग के अंदर सभी वर्णों को लोअरकेस में बदलने के लिए इसके अंदर 's1' स्ट्रिंग पास करते हैं। फिर, हम tolower() विधि के परिणामों को प्रिंट करते हैं जो 'result1' वेरिएबल में संग्रहीत होता है। इसके बाद, हम 's2' वेरिएबल में एक और स्ट्रिंग सेट करते हैं जिसमें सभी अक्षर लोअरकेस में होते हैं। मौजूदा स्ट्रिंग को अपरकेस में बदलने के लिए हम इस 's2' स्ट्रिंग पर टॉपर() विधि लागू करते हैं।
आउटपुट निम्नलिखित छवि में निर्दिष्ट मामले में दोनों स्ट्रिंग प्रदर्शित करता है:
निष्कर्ष
हमने स्ट्रिंग्स को प्रबंधित और विश्लेषण करने के विभिन्न तरीके सीखे जिन्हें स्ट्रिंग मैनिपुलेशन कहा जाता है। हमने स्ट्रिंग से चरित्र की स्थिति निकाली, विभिन्न स्ट्रिंग्स को संयोजित किया, और स्ट्रिंग को निर्दिष्ट मामले में बदल दिया। इसके अलावा, हमने स्ट्रिंग को स्वरूपित किया, स्ट्रिंग को संशोधित किया, और स्ट्रिंग में हेरफेर करने के लिए यहां कई अन्य ऑपरेशन किए गए।