यह मार्गदर्शिका AWS सेवा का उपयोग करके क्रॉस-सत्यापन और इसकी कार्यप्रणाली के बारे में बताएगी।
क्रॉस-वैलिडेशन क्या है?
क्रॉस-वैलिडेशन डेवलपर्स को विभिन्न मशीन-लर्निंग मॉडल की तुलना करने और वास्तविक जीवन में उनके काम करने की भावना प्राप्त करने की अनुमति देता है। यह उपयोगकर्ता को यह पता लगाने में मदद करता है कि कौन सा मशीन लर्निंग (एमएल) या डीप लर्निंग (डीएल) मॉडल एक विशेष डेटा या परिदृश्य के लिए बेहतर काम करेगा। ऐसी स्थितियाँ होती हैं जब एक डेटासेट के लिए कई मॉडल का उपयोग किया जा सकता है, यहाँ डेवलपर्स अनुकूलित परिणाम प्राप्त करने के लिए एक फिट मॉडल प्राप्त करने के लिए क्रॉस-वैलिडेशन का उपयोग करते हैं:
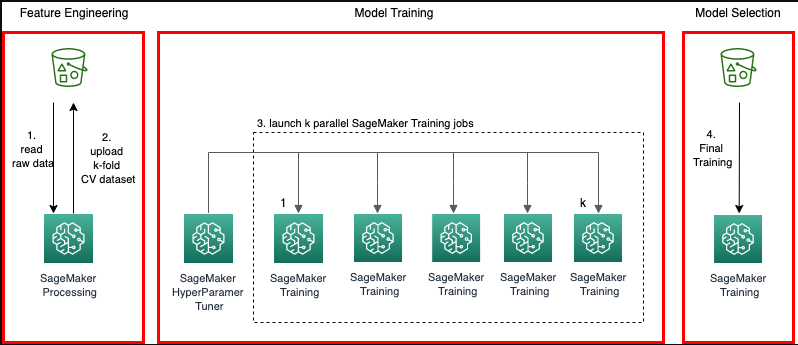
क्रॉस-वैलिडेशन कैसे काम करता है?
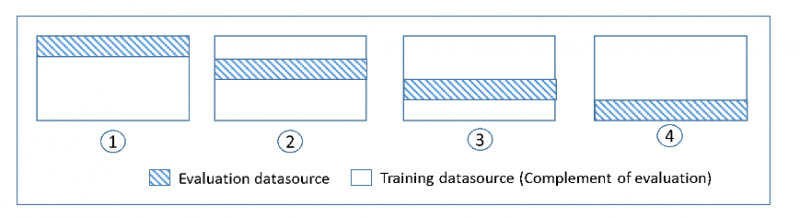
डेटासेट पर एमएल मॉडल की जांच करने के लिए, उपयोगकर्ता को उस मॉडल की विशेषताओं का अनुमान लगाने की आवश्यकता होती है जिसे एल्गोरिथम का प्रशिक्षण कहा जाता है। जांच करने के लिए एक और चीज मॉडल का मूल्यांकन है कि यह कितना अच्छा प्रदर्शन करता है और इसे मॉडल का परीक्षण कहा जाता है। सभी डेटा पर मॉडल का परीक्षण करना एक अच्छा विचार नहीं है, हालांकि बेहतर परिणाम प्राप्त करने के लिए हम प्रशिक्षण के लिए 75% डेटा और परीक्षण के लिए 25% का उपयोग करते हैं। कौन सा ब्लॉक सबसे अच्छा प्रदर्शन करता है यह जांचने के लिए क्रॉस-सत्यापन प्रत्येक 25% डेटा पर परीक्षण करता है:
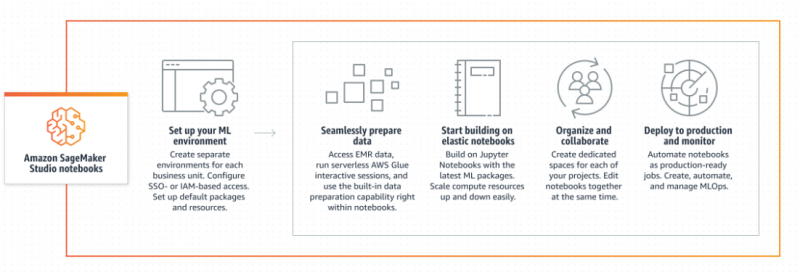
अमेज़न सैजमेकर क्या है?
AWS में क्रॉस-वैलिडेशन Amazon SageMaker सेवा का उपयोग करके किया जा सकता है क्योंकि इसे मशीन लर्निंग मॉडल बनाने, प्रशिक्षित करने और तैनात करने के लिए डिज़ाइन किया गया है। यह डेटा वैज्ञानिकों और डेवलपर्स को उद्देश्य-निर्मित क्षमताओं को एक साथ लाकर कुशल एमएल या डीएल मॉडल बनाने के लिए डेटा तैयार करने में मदद करता है। ये क्षमताएँ अनुकूलित और सटीक मॉडल बनाने के लिए उपयोगी हैं जिनमें समय के साथ सुधार करने की क्षमता होगी:

अमेज़न सैजमेकर की विशेषताएं
Amazon SageMaker एक प्रबंधित सेवा है और इसके लिए ML परिवेशों के प्रबंधन की आवश्यकता नहीं है। एमएल मॉडल को प्रशिक्षित करने और बनाने के लिए इसे बहुत अधिक डेटा की आवश्यकता होती है, इसलिए यह डेटा एकत्र करने के लिए Amazon S3 या Amazon Redshift सेवाओं के साथ अच्छी तरह से जुड़ता है। कच्चे डेटा से जानकारी प्राप्त करना मुश्किल हो सकता है इसलिए मॉडल बनाने के लिए सुविधाओं की भी आवश्यकता होती है। फिर मॉडल को प्रशिक्षित करने के लिए डेटा का उपयोग करें और फिर बेहतर परिणाम/भविष्यवाणियां प्राप्त करने के लिए प्रत्येक 25% डेटा का उपयोग करके उस पर परीक्षण करें:
यह सब AWS में क्रॉस-वैलिडेशन के बारे में है।
निष्कर्ष
क्रॉस-वैलिडेशन बेहतर परिणाम प्राप्त करने के लिए डेटा के लिए इष्टतम मशीन लर्निंग या डीप लर्निंग मॉडल प्राप्त करने की प्रक्रिया है। यह डेटा के प्रत्येक 25% खंड के लिए यह समझने के लिए परीक्षण करेगा कि कौन सा ब्लॉक अधिकतम आउटपुट प्रदान करता है जिससे यह एक उपयुक्त फिट मॉडल बन जाता है। AWS क्लाउड पर क्रॉस-वैलिडेशन करने और मशीन लर्निंग मॉडल बनाने के लिए SageMaker सेवा प्रदान करता है। इस गाइड ने क्रॉस-वैलिडेशन प्रक्रिया और AWS में इसके काम करने की व्याख्या की है।