इस लेख में, हम के महत्व का पता लगाएंगे डेटा संरचनाएं , विभिन्न प्रकार डेटा संरचनाएं सी ++ में उपलब्ध है, और उन्हें अपने कार्यक्रमों में प्रभावी ढंग से कैसे उपयोग करें।
C++ में डेटा स्ट्रक्चर क्या है
डेटा संरचना प्रोग्रामिंग में एक आवश्यक अवधारणा है और डेटा को संग्रहीत करने और व्यवस्थित करने में महत्वपूर्ण भूमिका निभाता है। सी ++ में, डेटा संरचना को डेटा को संग्रहीत करने और डेटा को एक विशिष्ट प्रारूप में प्रबंधित करने के तरीके के रूप में परिभाषित किया जा सकता है। यह डेटा के कुशल उपयोग और हेरफेर की अनुमति देता है, जिससे प्रोग्रामर के लिए कोड लिखना और बनाए रखना आसान हो जाता है।
सी ++ में, डेटा संरचनाएं निम्न सिंटैक्स है:
struct structure_name {
डेटाटाइप 1 नाम 1 ;
डेटाटाइप 2 नाम 2 ;
डेटाटाइप 3 नाम 3 ;
डेटाटाइप 4 नाम 4 ;
..
..
..
} obj_name ;
उपरोक्त सिंटैक्स में, संरचना कीवर्ड संरचना को परिभाषित करने के लिए प्रयोग किया जाता है और structure_name संरचना का उपयोगकर्ता परिभाषित नाम है और यह भिन्न हो सकता है। डेटाटाइप1 संरचना के सदस्य का डेटा प्रकार है और नाम1 संरचना के सदस्य का नाम है और obj_name उस वस्तु का नाम है जिसके लिए संरचना परिभाषित की गई है।
उदाहरण
नीचे दिए गए उदाहरण में, संरचना जानकारी तीन सदस्य होते हैं: नाम उम्र, और नागरिकता।
struct जानकारी
{
चार नाम [ पचास ] ;
int यहाँ सिटिज़नशिप ;
int यहाँ आयु ;
}
इस कोड को C++ में चलाते हैं, हमने इन सभी सदस्यों को संरचना व्यक्ति में परिभाषित किया है और कोई स्थान आवंटित नहीं किया है। मुख्य कार्य में, हमने इन सदस्यों को विशिष्ट मूल्यों के साथ प्रारंभ किया और उन्हें मुद्रित किया:
#शामिलनेमस्पेस एसटीडी का उपयोग करना ;
struct जानकारी
{
स्ट्रिंग नाम ;
int यहाँ आयु ;
} ;
int यहाँ मुख्य ( खालीपन ) {
struct जानकारी प ;
पी। नाम = 'ज़ैनब' ;
पी। आयु = 23 ;
अदालत << 'व्यक्ति का नाम:' << पी। नाम << endl ;
अदालत << 'व्यक्ति की उम्र:' << पी। आयु << endl ;
वापस करना 0 ;
}
कोड नामित संरचना को परिभाषित करता है जानकारी दो विशेषताओं के साथ: नाम और आयु। मुख्य कार्य में, एक नया जानकारी वस्तु बनाई जाती है और उसका नाम और आयु निर्धारित की जाती है। अंत में, इन क्षेत्रों के मान cout का उपयोग करके कंसोल पर प्रिंट किए जाते हैं।
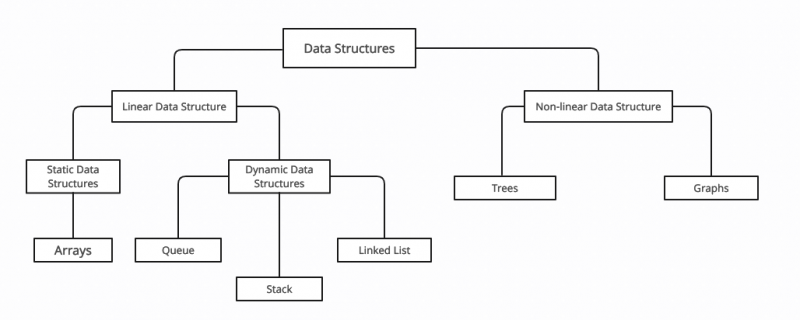
C++ में डेटा संरचना का वर्गीकरण
सी ++ में डेटा संरचना दो व्यापक श्रेणियों में बांटा गया है: रेखीय और अरैखिक डेटा संरचनाएं . डेटा संरचनाओं को निम्नलिखित विशेषताओं के आधार पर विभाजित किया गया है:
| विशेषता | व्याख्या | उदाहरण |
| रेखीय | डेटा को रैखिक क्रम में व्यवस्थित किया जाता है | सरणियों |
| गैर रेखीय | डेटा के आइटम रैखिक क्रम में नहीं हैं | ग्राफ, ट्री |
| स्थिर | स्थान, आकार और मेमोरी निश्चित हैं | सरणियों |
| गतिशील | प्रोग्राम के निष्पादन के आधार पर आकार बदलता है | लिंक्ड सूची |
| समरूप | वस्तुएँ एक ही प्रकार की होती हैं | सरणियों |
| गैर समरूप | आइटम एक ही प्रकार के हो सकते हैं या नहीं भी हो सकते हैं | संरचनाएं |
C++ में डेटा स्ट्रक्चर्स की श्रेणियां हैं:
1: सरणियाँ
Arrays C++ की सबसे मौलिक डेटा संरचनाएं हैं। सरणी समान डेटा प्रकार वाले तत्वों का समूह है। Arrays पूरे डेटा सेट पर संचालन करना आसान बनाता है। सरणियों में संग्रहीत मूल्यों को तत्वों के रूप में जाना जाता है।
2: लिंक्ड लिस्ट
लिंक की गई सूची में डेटा के तत्व नोड्स के माध्यम से जुड़े हुए हैं। प्रत्येक नोड के बाद नोड का पता और डेटा होता है। वे नोड्स जोड़ने और हटाने के लिए सर्वश्रेष्ठ हैं। लिंक्ड लिस्ट दो प्रकार की होती है एक सिंगल और दूसरी डबलली लिंक्ड लिस्ट। एक एकल लिंक्ड सूची में, पिछले नोड में उसके बाद के नोड का डेटा होता है लेकिन अगले नोड को पिछले नोड के बारे में पता नहीं होता है। दोगुनी जुड़ी हुई सूची में, दिशा आगे और साथ ही पीछे की ओर है।
3: ढेर
स्टैक अमूर्त डेटा प्रकार है जो LIFO (लास्ट इन फ़र्स्ट आउट) सिद्धांत का पालन करता है। इस नियम का अर्थ है कि अंत में डाला गया तत्व पहले हटा दिया जाएगा। उनका उपयोग पुनरावर्ती बैकट्रैकिंग एल्गोरिदम के साथ किया जाता है।
4: पूंछ
कतारें सार डेटा प्रकार भी हैं और फीफो (फर्स्ट इन एंड फर्स्ट आउट) नियम का पालन करती हैं। इस नियम का अर्थ है कि पहले डाला गया तत्व पहले हटा दिया जाएगा। रीयल-टाइम सिस्टम व्याख्याओं को संभालने में वे सहायक होते हैं।
5: पेड़
पेड़ कई नोड्स के साथ गैर-रैखिक डेटा संरचनाओं का एक सेट है। यह केवल एक किनारे को दो सिरों के साथ अनुमति देता है।
6: रेखांकन
एक ग्राफ में, प्रत्येक नोड एक शीर्ष है और प्रत्येक शीर्ष एक किनारे के माध्यम से दूसरे शीर्ष से जुड़ा हुआ है। गोले शीर्ष हैं और तीर किनारे हैं, उनका उपयोग वास्तविक जीवन परिदृश्यों या तंत्रिका नेटवर्क को लागू करने के लिए किया जाता है। ग्राफ़ के तीन अलग-अलग प्रकार होते हैं: अप्रत्यक्ष ग्राफ़, द्वि-निर्देशित ग्राफ़ और भारित ग्राफ़।
संचालन डेटा संरचनाओं पर प्रदर्शन करते हैं
हम C++ में डेटा संरचनाओं पर निम्नलिखित कार्य कर सकते हैं:
- डेटा संरचनाओं में नए डेटा तत्वों का सम्मिलन।
- डेटा संरचना से मौजूदा डेटा तत्वों को हटाना।
- डेटा संरचना में सभी डेटा तत्वों को प्रदर्शित करें।
- डेटा संरचना में विशिष्ट तत्व के लिए खोजें।
- सभी तत्वों को आरोही या अवरोही क्रम में व्यवस्थित करें।
- तत्वों को दो डेटा संरचनाओं से मिलाएं और नया बनाएं।
जमीनी स्तर
C++ में डेटा स्ट्रक्चर डेटा को कुशलतापूर्वक संभालने का तरीका है ताकि इसे एक्सेस किया जा सके। अपने प्रोजेक्ट के लिए उपयुक्त डेटा संरचना चुनना महत्वपूर्ण है, यदि आप डेटा को क्रमिक रूप से जोड़ना चाहते हैं तो सरणियों के लिए जाएं। डेटा संरचना अवधारणा को समझने से आपको प्रोग्रामिंग और एल्गोरिथम डिज़ाइन की कला में महारत हासिल करने में मदद मिलेगी।