डुप्लिकेट डेटा अक्सर भ्रम, त्रुटियां और विषम अंतर्दृष्टि पैदा कर सकता है। सौभाग्य से, Google शीट्स हमें इन अनावश्यक प्रविष्टियों को पहचानने और हटाने के कार्य को सरल बनाने के लिए कई उपकरण और तकनीकें प्रदान करता है। बुनियादी सेल तुलनाओं से लेकर उन्नत फॉर्मूला-आधारित दृष्टिकोणों तक, आप अव्यवस्थित शीटों को व्यवस्थित, मूल्यवान संसाधनों में बदलने में सक्षम होंगे।
चाहे आप ग्राहक सूची, सर्वेक्षण परिणाम, या कोई अन्य डेटासेट संभाल रहे हों, डुप्लिकेट प्रविष्टियों को समाप्त करना विश्वसनीय विश्लेषण और निर्णय लेने की दिशा में एक मौलिक कदम है।
इस गाइड में, हम आपको डुप्लिकेट मानों को पहचानने और हटाने की अनुमति देने के लिए दो तरीकों पर चर्चा करेंगे।
टेबल निर्माण
हमने सबसे पहले Google शीट्स में एक तालिका बनाई, जिसका उपयोग इस आलेख में बाद के उदाहरणों में किया जाएगा। इस तालिका में 3 कॉलम हैं: कॉलम ए, शीर्षक 'नाम' के साथ, नाम संग्रहीत करता है; कॉलम बी में शीर्षक 'आयु' है, जिसमें लोगों की उम्र दर्ज है; और अंत में, कॉलम सी, शीर्षक 'शहर' में शहर शामिल हैं। यदि हम देखें, तो इस तालिका में कुछ प्रविष्टियाँ दोहराई गई हैं, जैसे 'जॉन' और 'सारा' की प्रविष्टियाँ।
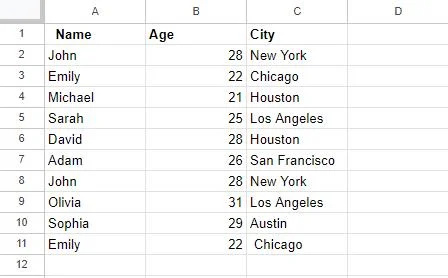
हम विभिन्न तरीकों से इन डुप्लिकेट मानों को हटाने के लिए इस तालिका पर काम करेंगे।
विधि 1: Google शीट्स में 'डुप्लिकेट हटाएं' सुविधा का उपयोग करना
पहली विधि जिस पर हम यहां चर्चा कर रहे हैं वह Google शीट की 'डुप्लिकेट हटाएं' सुविधा का उपयोग करके डुप्लिकेट मानों को हटाना है। यह विधि चयनित कक्षों की श्रेणी से डुप्लिकेट प्रविष्टियों को स्थायी रूप से समाप्त कर देगी।
इस विधि को प्रदर्शित करने के लिए, हम फिर से ऊपर दी गई तालिका पर विचार करेंगे।
इस पद्धति पर काम शुरू करने के लिए, सबसे पहले, हमें हेडर सहित अपने डेटा वाली संपूर्ण श्रृंखला का चयन करना होगा। इस परिदृश्य में, हमने कक्षों को चुना है A1:C11 .
Google शीट विंडो के शीर्ष पर, आपको विभिन्न मेनू के साथ एक नेविगेशन बार दिखाई देगा। नेविगेशन बार में 'डेटा' विकल्प ढूंढें और उस पर क्लिक करें।
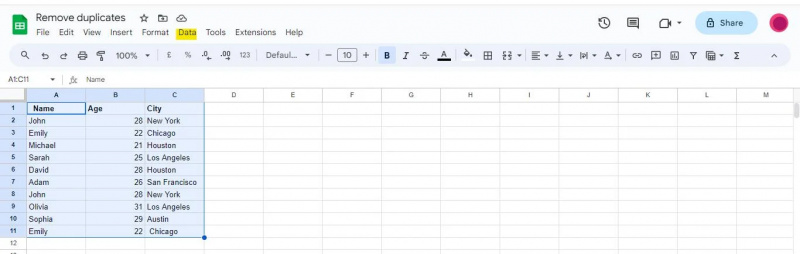
जब आप 'डेटा' विकल्प पर क्लिक करेंगे तो एक ड्रॉपडाउन मेनू दिखाई देगा, जो आपको विभिन्न डेटा-संबंधित टूल और फ़ंक्शंस प्रस्तुत करेगा जिनका उपयोग आपके डेटा का विश्लेषण, साफ़ और हेरफेर करने के लिए किया जा सकता है।
इस उदाहरण के लिए, हमें 'डेटा क्लीनअप' विकल्प पर नेविगेट करने के लिए 'डेटा' मेनू तक पहुंचने की आवश्यकता होगी, जिसमें 'डुप्लिकेट हटाएं' सुविधा शामिल है।
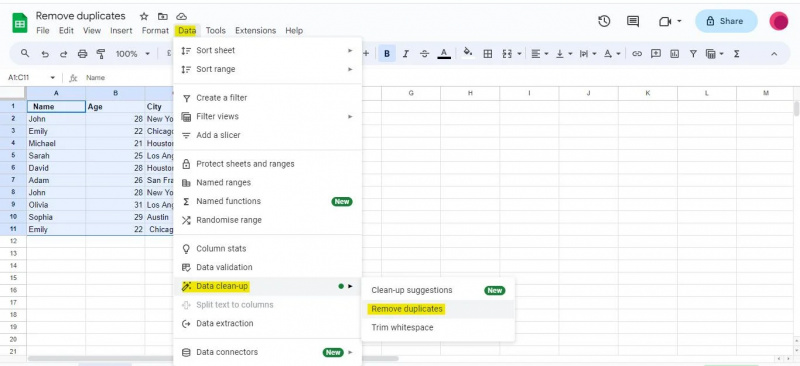
'डुप्लिकेट हटाएं' संवाद बॉक्स तक पहुंचने के बाद, हमें अपने डेटासेट में कॉलम की एक सूची प्रस्तुत की जाएगी। इन कॉलमों के आधार पर डुप्लिकेट ढूंढे जाएंगे और हटा दिए जाएंगे। डुप्लिकेट की पहचान के लिए हम किन कॉलमों का उपयोग करना चाहते हैं, इसके आधार पर हम डायलॉग बॉक्स में संबंधित चेकबॉक्स को चिह्नित करेंगे।
हमारे उदाहरण में, हमारे पास तीन कॉलम हैं: 'नाम,' 'आयु,' और 'शहर।' चूंकि हम सभी तीन कॉलमों के आधार पर डुप्लिकेट की पहचान करना चाहते हैं, इसलिए हमने सभी तीन चेकबॉक्स चेक कर लिए हैं। इसके अलावा, यदि आपकी तालिका में हेडर हैं तो आपको 'डेटा में हेडर पंक्ति है' चेकबॉक्स को चेक करना होगा। जैसा कि हमारे पास ऊपर दी गई तालिका में हेडर हैं, हमने 'डेटा में हेडर पंक्ति है' चेकबॉक्स को चेक किया है।
एक बार जब हम डुप्लिकेट की पहचान करने के लिए कॉलम चुन लेते हैं, तो हम उन डुप्लिकेट को अपने डेटासेट से हटाने के लिए आगे बढ़ सकते हैं।
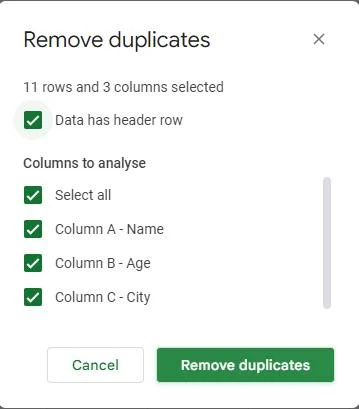
आपको 'डुप्लिकेट हटाएं' संवाद बॉक्स के नीचे 'डुप्लिकेट हटाएं' लेबल वाला एक बटन मिलेगा। इस बटन पर क्लिक करें.
'डुप्लिकेट हटाएं' पर क्लिक करने के बाद, Google शीट आपके अनुरोध पर कार्रवाई करेगा। कॉलम स्कैन किए जाएंगे, और उन कॉलमों में डुप्लिकेट मान वाली सभी पंक्तियों को हटा दिया जाएगा, डुप्लिकेट को सफलतापूर्वक हटा दिया जाएगा।
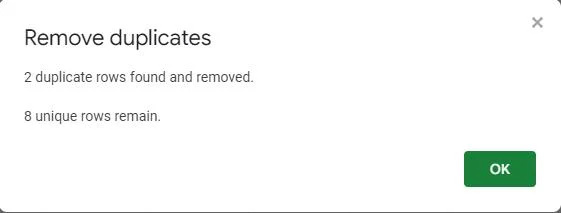
एक पॉप-अप स्क्रीन पुष्टि करती है कि डुप्लिकेट मान तालिका से हटा दिए गए हैं। यह दर्शाता है कि दो डुप्लिकेट पंक्तियाँ पाई गईं और हटा दी गईं, जिससे तालिका में आठ अद्वितीय प्रविष्टियाँ रह गईं।
'डुप्लिकेट हटाएं' सुविधा का उपयोग करने के बाद, हमारी तालिका निम्नानुसार अपडेट की जाती है:
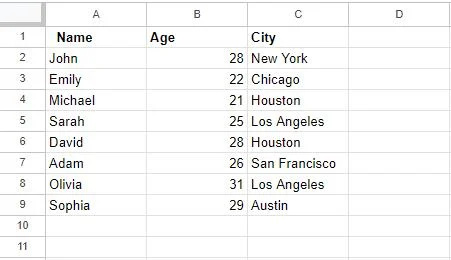
यहां विचार करने योग्य एक महत्वपूर्ण बात यह है कि इस सुविधा का उपयोग करके डुप्लिकेट को हटाना एक स्थायी कार्रवाई है। डुप्लिकेट पंक्तियाँ आपके डेटासेट से हटा दी जाएंगी, और जब तक आपके पास डेटा बैकअप नहीं होगा आप इस क्रिया को पूर्ववत नहीं कर पाएंगे। इसलिए, अपने चयन की दोबारा जांच करके सुनिश्चित करें कि आपने डुप्लिकेट खोजने के लिए सही कॉलम चुना है।
विधि 2: डुप्लिकेट हटाने के लिए अद्वितीय फ़ंक्शन का उपयोग करना
दूसरी विधि जिस पर हम यहां चर्चा करेंगे उसका उपयोग करना है अद्वितीय Google शीट्स में कार्य करें। अद्वितीय फ़ंक्शन डेटा की एक निर्दिष्ट श्रेणी या कॉलम से अलग-अलग मान पुनर्प्राप्त करता है। हालाँकि यह सीधे मूल डेटा से डुप्लिकेट को नहीं हटाता है, यह अद्वितीय मानों की एक सूची बनाता है जिनका उपयोग आप डुप्लिकेट के बिना डेटा परिवर्तन या विश्लेषण के लिए कर सकते हैं।
आइए इस विधि को समझने के लिए एक उदाहरण बनाएं।
हम उस तालिका का उपयोग करेंगे जो इस ट्यूटोरियल के प्रारंभिक भाग में बनाई गई थी। जैसा कि हम पहले से ही जानते हैं, तालिका में कुछ डेटा डुप्लिकेट किया गया है। इसलिए, हमने लिखने के लिए एक सेल, 'E2' चुना है अद्वितीय सूत्र में. हमने जो सूत्र लिखा है वह इस प्रकार है:
=अद्वितीय(A2:A11)
जब Google शीट्स में उपयोग किया जाता है, तो UNIQUE सूत्र एक अलग कॉलम में अद्वितीय मान पुनर्प्राप्त करता है। इसलिए, हमने यह सूत्र सेल की एक सीमा के साथ प्रदान किया है ए2 को ए11 , जिसे कॉलम ए में लागू किया जाएगा। इस प्रकार, यह सूत्र कॉलम से अद्वितीय मान निकालता है ए और उन्हें उस कॉलम में प्रदर्शित करता है जहां सूत्र लिखा गया है।
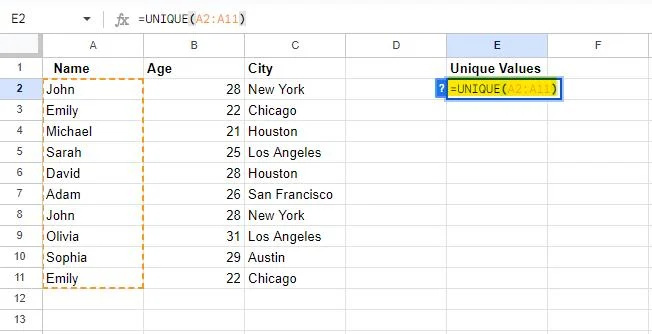
जब आप Enter कुंजी दबाएंगे तो सूत्र निर्दिष्ट सीमा पर लागू हो जाएगा।
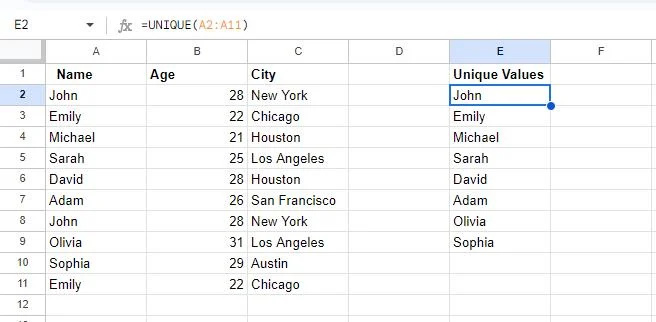
इस स्नैपशॉट में, हम देख सकते हैं कि दो सेल खाली हैं। ऐसा इसलिए है क्योंकि तालिका में दो मानों को दोहराया गया है, अर्थात्, जॉन और एमिली। अद्वितीय फ़ंक्शन प्रत्येक मान का केवल एक उदाहरण प्रदर्शित करता है।
इस पद्धति ने निर्दिष्ट कॉलम से सीधे डुप्लिकेट किए गए मानों को नहीं हटाया, बल्कि डुप्लिकेट को हटाकर हमें उस कॉलम की अद्वितीय प्रविष्टियाँ प्रदान करने के लिए एक और कॉलम बनाया।
निष्कर्ष
डेटा का विश्लेषण करने के लिए Google शीट्स में डुप्लिकेट हटाना एक लाभकारी तरीका है। इस गाइड ने दो तरीकों का प्रदर्शन किया जो आपको अपने डेटा से डुप्लिकेट प्रविष्टियों को आसानी से हटाने में सक्षम बनाता है। पहली विधि में डुप्लिकेट सुविधा को हटाने के लिए Google शीट्स के उपयोग के बारे में बताया गया। यह विधि निर्दिष्ट सेल रेंज को स्कैन करती है और डुप्लिकेट को हटा देती है। जिस अन्य विधि पर हमने चर्चा की है वह डुप्लिकेट मानों को पुनः प्राप्त करने के लिए सूत्र का उपयोग करना है। हालाँकि यह सीधे डुप्लिकेट को सीमा से नहीं हटाता है, इसके बजाय यह एक नए कॉलम में अद्वितीय मान प्रदर्शित करता है।