त्वरित रूपरेखा
यह पोस्ट निम्नलिखित प्रदर्शित करेगी:
- लैंगचेन में ओपनएआई फ़ंक्शंस एजेंट में मेमोरी कैसे जोड़ें
- चरण 1: फ्रेमवर्क स्थापित करना
- चरण 2: वातावरण स्थापित करना
- चरण 3: पुस्तकालय आयात करना
- चरण 4: डेटाबेस बनाना
- चरण 5: डेटाबेस अपलोड करना
- चरण 6: भाषा मॉडल को कॉन्फ़िगर करना
- चरण 7: मेमोरी जोड़ना
- चरण 8: एजेंट को आरंभ करना
- चरण 9: एजेंट का परीक्षण
- निष्कर्ष
लैंगचेन में ओपनएआई फ़ंक्शंस एजेंट में मेमोरी कैसे जोड़ें?
OpenAI एक आर्टिफिशियल इंटेलिजेंस (AI) संगठन है जिसका गठन 2015 में हुआ था और शुरुआत में यह एक गैर-लाभकारी संगठन था। माइक्रोसॉफ्ट 2020 से बहुत अधिक निवेश कर रहा है क्योंकि एआई के साथ प्राकृतिक भाषा प्रसंस्करण (एनएलपी) चैटबॉट और भाषा मॉडल के साथ तेजी से बढ़ रहा है।
OpenAI एजेंटों का निर्माण डेवलपर्स को इंटरनेट से अधिक पठनीय और प्रासंगिक परिणाम प्राप्त करने में सक्षम बनाता है। एजेंटों में मेमोरी जोड़ने से वे चैट के संदर्भ को बेहतर ढंग से समझ सकते हैं और पिछली बातचीत को भी अपनी मेमोरी में संग्रहीत कर सकते हैं। लैंगचेन में ओपनएआई फ़ंक्शंस एजेंट में मेमोरी जोड़ने की प्रक्रिया सीखने के लिए, बस निम्नलिखित चरणों से गुजरें:
चरण 1: फ्रेमवर्क स्थापित करना
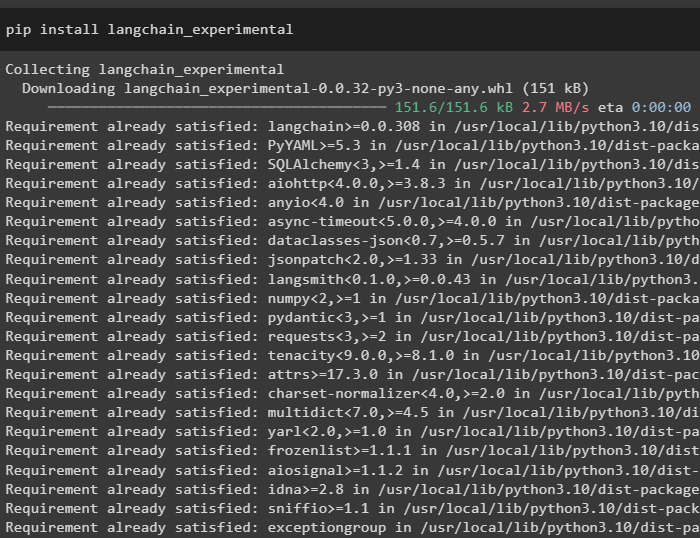
सबसे पहले, लैंगचेन निर्भरताएँ स्थापित करें 'लैंगचैन-प्रयोगात्मक' निम्नलिखित कोड का उपयोग कर ढांचा:
पाइप लैंगचैन स्थापित करें - प्रयोगात्मक
स्थापित करें 'Google-खोज-परिणाम' Google सर्वर से खोज परिणाम प्राप्त करने के लिए मॉड्यूल:
पिप इंस्टॉल गूगल - खोज - परिणाम 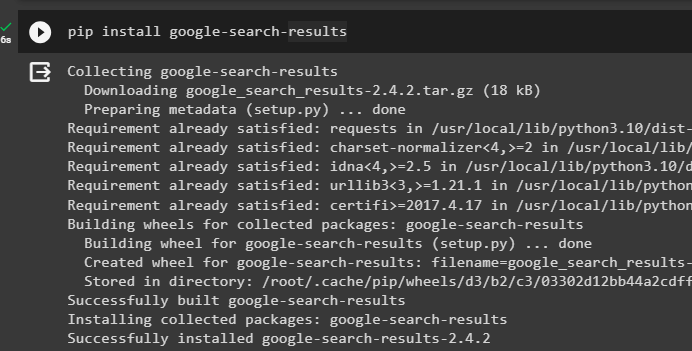
इसके अलावा, OpenAI मॉड्यूल स्थापित करें जिसका उपयोग लैंगचेन में भाषा मॉडल बनाने के लिए किया जा सकता है:
पिप इंस्टाल ओपनाई 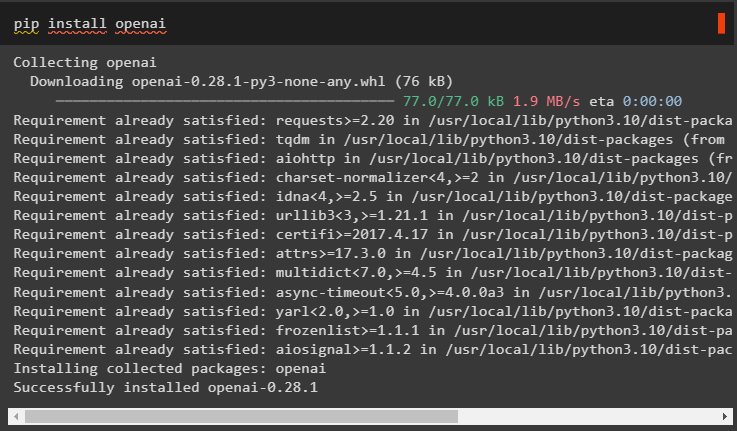
चरण 2: वातावरण स्थापित करना
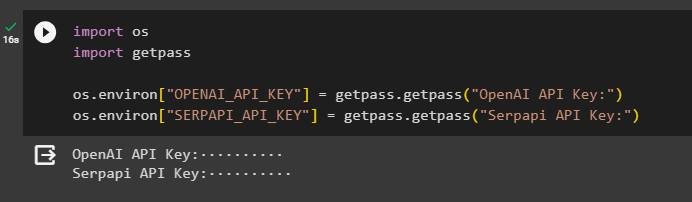
मॉड्यूल प्राप्त करने के बाद, एपीआई कुंजियों का उपयोग करके वातावरण सेट करें ओपनएआई और सर्पएपीआई हिसाब किताब:
आयात आपआयात पास ले लो
आप। लगभग [ 'OPENAI_API_KEY' ] = पास ले लो। पास ले लो ( 'ओपनएआई एपीआई कुंजी:' )
आप। लगभग [ 'SERPAPI_API_KEY' ] = पास ले लो। पास ले लो ( 'सेरपापी एपीआई कुंजी:' )
दोनों परिवेशों तक पहुँचने के लिए एपीआई कुंजियाँ दर्ज करने के लिए उपरोक्त कोड निष्पादित करें और पुष्टि करने के लिए एंटर दबाएँ:
चरण 3: पुस्तकालय आयात करना
अब जब सेटअप पूरा हो गया है, तो मेमोरी और एजेंटों के निर्माण के लिए आवश्यक लाइब्रेरी आयात करने के लिए लैंगचेन से स्थापित निर्भरता का उपयोग करें:
लैंगचैन से. चेन आयात एलएलएममैथचेनलैंगचैन से. एलएमएस आयात ओपनएआई
#इंटरनेट पर Google से खोजने के लिए लाइब्रेरी प्राप्त करें
लैंगचैन से. उपयोगिताओं आयात सर्पएपिरैपर
लैंगचैन से. उपयोगिताओं आयात एसक्यूएलडेटाबेस
लैंगचैन_एक्सपेरिमेंटल से। एसक्यूएल आयात SQLडेटाबेसश्रृंखला
#उपकरण बनाने के लिए लाइब्रेरी प्राप्त करें के लिए एजेंट को प्रारंभ करना
लैंगचैन से. एजेंट आयात एजेंट प्रकार , औजार , इनिशियलाइज़_एजेंट
लैंगचैन से. चैट_मॉडल आयात चैटओपनएआई
चरण 4: डेटाबेस बनाना
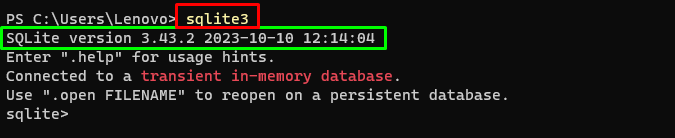
इस गाइड के साथ आगे बढ़ने के लिए, हमें डेटाबेस बनाने और उससे उत्तर निकालने के लिए एजेंट से जुड़ने की आवश्यकता है। डेटाबेस बनाने के लिए, इसका उपयोग करके SQLite डाउनलोड करना आवश्यक है मार्गदर्शक और निम्न आदेश का उपयोग करके स्थापना की पुष्टि करें:
sqlite3में उपरोक्त कमांड चला रहा हूं विंडोज़ टर्मिनल SQLite का स्थापित संस्करण प्रदर्शित करता है (3.43.2):
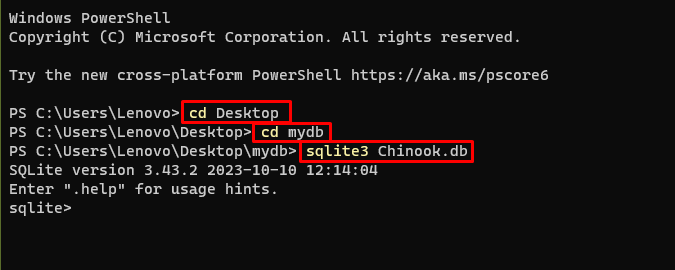
उसके बाद, बस अपने कंप्यूटर पर उस निर्देशिका पर जाएं जहां डेटाबेस बनाया और संग्रहीत किया जाएगा:
सीडी डेस्कटॉपसीडी mydb
sqlite3 चिनूक। डाटाबेस
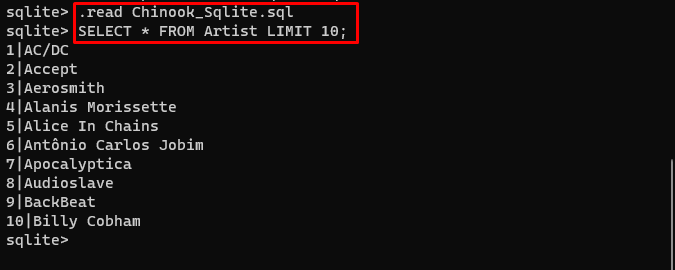
उपयोगकर्ता इससे आसानी से डेटाबेस की सामग्री डाउनलोड कर सकता है जोड़ना निर्देशिका में और डेटाबेस बनाने के लिए निम्नलिखित कमांड निष्पादित करें:
. पढ़ना चिनूक_स्क्लाइट। एसक्यूएलचुनना * कलाकार सीमा से 10 ;
डेटाबेस सफलतापूर्वक बनाया गया है और उपयोगकर्ता विभिन्न प्रश्नों का उपयोग करके इसमें से डेटा खोज सकता है:
चरण 5: डेटाबेस अपलोड करना
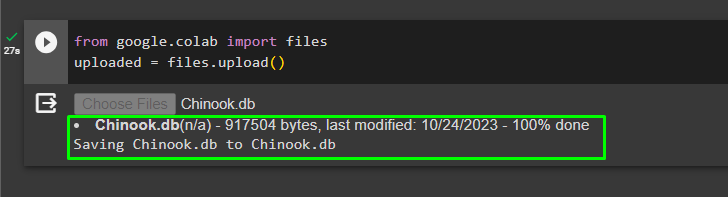
एक बार डेटाबेस सफलतापूर्वक बन जाने के बाद, अपलोड करें '.db' निम्नलिखित कोड का उपयोग करके Google सहयोगात्मक में फ़ाइल करें:
गूगल से. और अन्य आयात फ़ाइलेंअपलोड किए गए = फ़ाइलें. डालना ( )
पर क्लिक करके स्थानीय सिस्टम से फ़ाइल चुनें 'फ़ाइलों का चयन करें' उपरोक्त कोड निष्पादित करने के बाद बटन:
एक बार फ़ाइल अपलोड हो जाने के बाद, बस फ़ाइल का पथ कॉपी करें जिसका उपयोग अगले चरण में किया जाएगा:
चरण 6: भाषा मॉडल को कॉन्फ़िगर करना
निम्नलिखित कोड का उपयोग करके भाषा मॉडल, श्रृंखला, उपकरण और श्रृंखला बनाएं:
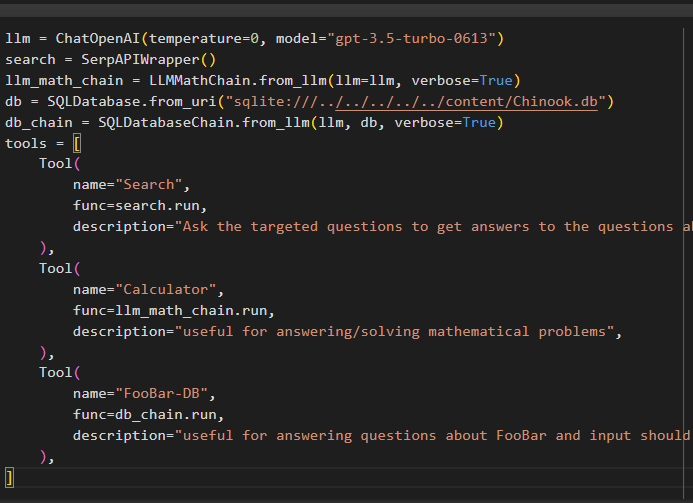
एलएलएम = चैटओपनएआई ( तापमान = 0 , नमूना = 'जीपीटी-3.5-टर्बो-0613' )खोज = सर्पएपिरैपर ( )
एलएलएम_गणित_श्रृंखला = एलएलएममैथचेन। from_llm ( एलएलएम = एलएलएम , वाचाल = सत्य )
डाटाबेस = SQLडेटाबेस। from_uri ( 'sqlite:///../../../../../content/Chinook.db' )
db_चेन = SQLडेटाबेसश्रृंखला। from_llm ( एलएलएम , डाटाबेस , वाचाल = सत्य )
औजार = [
औजार (
नाम = 'खोज' ,
समारोह = खोजना। दौड़ना ,
विवरण = 'हाल के मामलों के बारे में प्रश्नों के उत्तर पाने के लिए लक्षित प्रश्न पूछें' ,
) ,
औजार (
नाम = 'कैलकुलेटर' ,
समारोह = एलएलएम_मैथ_चेन. दौड़ना ,
विवरण = 'गणितीय समस्याओं का उत्तर देने/हल करने के लिए उपयोगी' ,
) ,
औजार (
नाम = 'फूबार-डीबी' ,
समारोह = db_चेन. दौड़ना ,
विवरण = 'FooBar के बारे में प्रश्नों के उत्तर देने के लिए उपयोगी और इनपुट पूर्ण संदर्भ वाले प्रश्न के रूप में होना चाहिए' ,
) ,
]
- एलएलएम वेरिएबल में मॉडल के नाम के साथ ChatOpenAI() विधि का उपयोग करके भाषा मॉडल की कॉन्फ़िगरेशन शामिल है।
- खोज वेरिएबल में एजेंट के लिए उपकरण बनाने के लिए SerpAPIWrapper() विधि शामिल है।
- का निर्माण करें एलएलएम_गणित_श्रृंखला LLMMathChain() विधि का उपयोग करके गणित डोमेन से संबंधित उत्तर प्राप्त करने के लिए।
- डीबी वेरिएबल में फ़ाइल का पथ होता है जिसमें डेटाबेस की सामग्री होती है। उपयोगकर्ता को केवल अंतिम भाग को बदलने की आवश्यकता है जो कि है 'सामग्री/चिनूक.डीबी' पथ का ध्यान रखते हुए “sqlite:///../../../../../” जो उसी।
- का उपयोग करके डेटाबेस से प्रश्नों का उत्तर देने के लिए एक और श्रृंखला बनाएं db_चेन चर।
- जैसे टूल कॉन्फ़िगर करें खोज , कैलकुलेटर , और फूबार-डीबी डेटाबेस से क्रमशः उत्तर खोजने, गणित के प्रश्नों और प्रश्नों का उत्तर देने के लिए:
चरण 7: मेमोरी जोड़ना
OpenAI फ़ंक्शंस को कॉन्फ़िगर करने के बाद, बस एजेंट में मेमोरी बनाएं और जोड़ें:
लैंगचैन से. संकेतों आयात संदेशप्लेसहोल्डरलैंगचैन से. याद आयात कन्वर्सेशनबफरमेमोरी
एजेंट_क्वार्ग्स = {
'अतिरिक्त_प्रॉम्प्ट_संदेश' : [ संदेशप्लेसहोल्डर ( चर का नाम = 'याद' ) ] ,
}
याद = कन्वर्सेशनबफरमेमोरी ( मेमोरी_कुंजी = 'याद' , वापसी_संदेश = सत्य )
चरण 8: एजेंट को आरंभ करना
निर्माण और आरंभ करने वाला अंतिम घटक एजेंट है, जिसमें सभी घटक शामिल हैं एलएलएम , औजार , OPENAI_FUNCTIONS , और इस प्रक्रिया में उपयोग किए जाने वाले अन्य:
प्रतिनिधि = इनिशियलाइज़_एजेंट (औजार ,
एलएलएम ,
प्रतिनिधि = एजेंट प्रकार. OPENAI_FUNCTIONS ,
वाचाल = सत्य ,
एजेंट_क्वार्ग्स = एजेंट_क्वार्ग्स ,
याद = याद ,
)
चरण 9: एजेंट का परीक्षण
अंत में, 'का उपयोग करके चैट आरंभ करके एजेंट का परीक्षण करें नमस्ते ' संदेश:
प्रतिनिधि। दौड़ना ( 'नमस्ते' ) 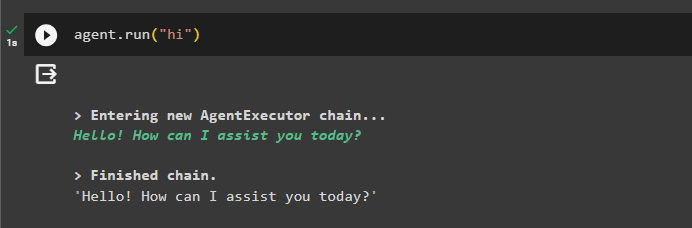
एजेंट को इसके साथ चलाकर मेमोरी में कुछ जानकारी जोड़ें:
प्रतिनिधि। दौड़ना ( 'मेरा नाम जॉन स्नो है' ) 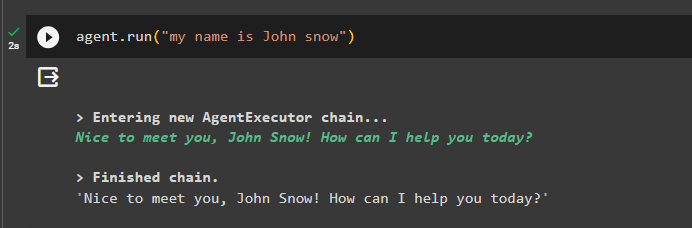
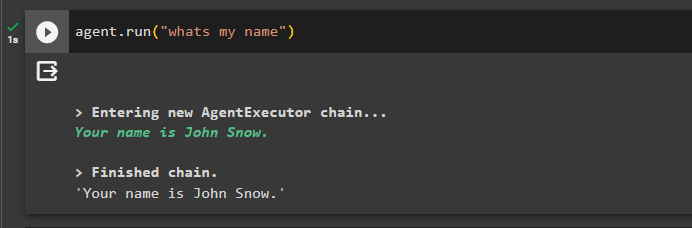
अब, पिछली चैट के बारे में प्रश्न पूछकर स्मृति का परीक्षण करें:
प्रतिनिधि। दौड़ना ( 'मेरा नाम क्या है' )एजेंट ने मेमोरी से प्राप्त नाम के साथ प्रतिक्रिया दी है, इसलिए एजेंट के साथ मेमोरी सफलतापूर्वक चल रही है:
अभी के लिए इतना ही।
निष्कर्ष
लैंगचेन में ओपनएआई फ़ंक्शंस एजेंट में मेमोरी जोड़ने के लिए, लाइब्रेरी आयात करने के लिए निर्भरता प्राप्त करने के लिए मॉड्यूल स्थापित करें। उसके बाद, बस डेटाबेस बनाएं और इसे पायथन नोटबुक पर अपलोड करें ताकि इसका उपयोग मॉडल के साथ किया जा सके। मॉडल, टूल, चेन और डेटाबेस को एजेंट में जोड़ने और इसे आरंभ करने से पहले कॉन्फ़िगर करें। मेमोरी का परीक्षण करने से पहले, ConversationalBufferMemory() का उपयोग करके मेमोरी बनाएं और परीक्षण करने से पहले इसे एजेंट में जोड़ें। इस गाइड में लैंगचेन में ओपनएआई फ़ंक्शंस एजेंट में मेमोरी जोड़ने के तरीके के बारे में विस्तार से बताया गया है।