आर्टिफिशियल इंटेलिजेंस मशीन लर्निंग एल्गोरिदम का उपयोग करके विशाल डेटा का उपयोग करके मॉडलों को प्रशिक्षित और परीक्षण करने के लिए सबसे तेजी से बढ़ती प्रौद्योगिकियों में से एक है। डेटा को विभिन्न प्रारूपों में संग्रहीत किया जा सकता है लेकिन लैंगचेन का उपयोग करके बड़े भाषा मॉडल बनाने के लिए, सबसे अधिक उपयोग किया जाने वाला प्रकार JSON है। प्रशिक्षण और परीक्षण डेटा बिना किसी अस्पष्टता के स्पष्ट और पूर्ण होना चाहिए ताकि मॉडल प्रभावी ढंग से प्रदर्शन कर सके।
यह मार्गदर्शिका लैंगचेन में पाइडेंटिक JSON पार्सर का उपयोग करने की प्रक्रिया को प्रदर्शित करेगी।
लैंगचेन में पाइडेंटिक (JSON) पार्सर का उपयोग कैसे करें?
JSON डेटा में डेटा का पाठ्य प्रारूप शामिल होता है जिसे वेब स्क्रैपिंग और कई अन्य स्रोतों जैसे लॉग आदि के माध्यम से इकट्ठा किया जा सकता है। डेटा की सटीकता को मान्य करने के लिए, लैंगचेन प्रक्रिया को सरल बनाने के लिए पायथन से पाइडेंटिक लाइब्रेरी का उपयोग करता है। लैंगचेन में पाइडेंटिक JSON पार्सर का उपयोग करने के लिए, बस इस गाइड को पढ़ें:
चरण 1: मॉड्यूल स्थापित करें
प्रक्रिया शुरू करने के लिए, लैंगचेन में पार्सर का उपयोग करने के लिए इसकी लाइब्रेरी का उपयोग करने के लिए बस लैंगचेन मॉड्यूल स्थापित करें:
रंज स्थापित करना लैंगचैन
अब, 'का उपयोग करें पाइप स्थापित करें ओपनएआई फ्रेमवर्क प्राप्त करने और उसके संसाधनों का उपयोग करने के लिए कमांड:
रंज स्थापित करना openai
मॉड्यूल स्थापित करने के बाद, बस 'का उपयोग करके इसकी एपीआई कुंजी प्रदान करके ओपनएआई वातावरण से कनेक्ट करें' आप ' और ' पास ले लो 'पुस्तकालय:
हमें आयात करेंगेटपास आयात करें
ओएस.पर्यावरण [ 'ओपेनएआई_एपीआई_कुंजी' ] = गेटपास.गेटपास ( 'ओपनएआई एपीआई कुंजी:' )

चरण 2: पुस्तकालय आयात करें
आवश्यक लाइब्रेरीज़ को आयात करने के लिए लैंगचेन मॉड्यूल का उपयोग करें जिनका उपयोग प्रॉम्प्ट के लिए टेम्पलेट बनाने के लिए किया जा सकता है। प्रॉम्प्ट का टेम्प्लेट प्राकृतिक भाषा में प्रश्न पूछने की विधि का वर्णन करता है ताकि मॉडल प्रॉम्प्ट को प्रभावी ढंग से समझ सके। इसके अलावा, चैटबॉट बनाने के लिए एलएलएम का उपयोग करके श्रृंखला बनाने के लिए ओपनएआई और चैटओपनएआई जैसी लाइब्रेरी आयात करें:
langchin.prompts आयात से (प्रॉम्प्टटेम्पलेट,
चैटप्रॉम्प्टटेम्पलेट,
ह्यूमनमैसेजप्रॉम्प्टटेम्पलेट,
)
langchan.llms से OpenAI आयात करें
langchan.chat_models से ChatOpenAI आयात करें
उसके बाद, लैंगचेन में JSON पार्सर का उपयोग करने के लिए बेसमॉडल, फ़ील्ड और वैलिडेटर जैसी पाइडेंटिक लाइब्रेरी आयात करें:
langchan.output_parsers से PydanticOutputParser आयात करेंपाइडेंटिक आयात से बेसमॉडल, फ़ील्ड, सत्यापनकर्ता
आयात सूची टाइप करने से
चरण 3: एक मॉडल बनाना
पाइडेंटिक JSON पार्सर का उपयोग करने के लिए सभी लाइब्रेरी प्राप्त करने के बाद, बस OpenAI() विधि के साथ पूर्व-डिज़ाइन किया गया परीक्षण मॉडल प्राप्त करें:
मॉडल_नाम = 'टेक्स्ट-डेविन्सी-003'तापमान = 0.0
मॉडल = ओपनएआई ( मॉडल नाम =मॉडल_नाम, तापमान =तापमान )
चरण 4: एक्टर बेसमॉडल कॉन्फ़िगर करें
अभिनेता की फिल्मोग्राफी के बारे में पूछकर अभिनेताओं से संबंधित उनके नाम और फिल्मों जैसे उत्तर पाने के लिए एक और मॉडल बनाएं:
श्रेणी अभिनेता ( बेसमॉडल ) :नाम: str = फ़ील्ड ( विवरण = 'मुख्य अभिनेता का नाम' )
फ़िल्म_नाम: सूची [ एसटीआर ] = फ़ील्ड ( विवरण = 'फ़िल्में जिनमें अभिनेता मुख्य भूमिका में थे' )
अभिनेता_क्वेरी = 'मैं किसी अभिनेता की फ़िल्मोग्राफी देखना चाहता हूँ'
पार्सर = PydanticOutputParser ( pydantic_object =अभिनेता )
प्रॉम्प्ट = प्रॉम्प्ट टेम्पलेट (
खाका = 'उपयोगकर्ता के संकेत का उत्तर दें। \एन {format_instructions} \एन {सवाल} \एन ' ,
इनपुट_चर = [ 'सवाल' ] ,
आंशिक_चर = { 'प्रारूप_निर्देश' : parser.get_format_instructions ( ) } ,
)
चरण 5: बेस मॉडल का परीक्षण
बस पार्स() फ़ंक्शन का उपयोग करके आउटपुट वैरिएबल के साथ आउटपुट प्राप्त करें जिसमें प्रॉम्प्ट के लिए उत्पन्न परिणाम शामिल हों:
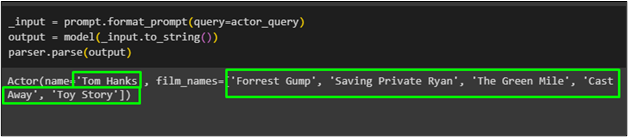
_इनपुट = प्रॉम्प्ट.फॉर्मेट_प्रॉम्प्ट ( सवाल =अभिनेता_क्वेरी )आउटपुट = मॉडल ( _input.to_string ( ) )
पार्सर.पार्स ( आउटपुट )
अभिनेता का नाम ' टौम हैंक्स उनकी फिल्मों की सूची मॉडल से पाइडेंटिक फ़ंक्शन का उपयोग करके प्राप्त की गई है:
यह सब लैंगचेन में पाइडेंटिक JSON पार्सर का उपयोग करने के बारे में है।
निष्कर्ष
लैंगचेन में पाइडेंटिक JSON पार्सर का उपयोग करने के लिए, बस अपने संसाधनों और पुस्तकालयों से जुड़ने के लिए लैंगचेन और ओपनएआई मॉड्यूल स्थापित करें। उसके बाद, बेस मॉडल बनाने और JSON के रूप में डेटा को सत्यापित करने के लिए OpenAI और pydantic जैसी लाइब्रेरी आयात करें। बेस मॉडल बनाने के बाद, पार्स() फ़ंक्शन निष्पादित करें, और यह प्रॉम्प्ट के उत्तर लौटाता है। इस पोस्ट ने लैंगचेन में पाइडेंटिक JSON पार्सर का उपयोग करने की प्रक्रिया का प्रदर्शन किया।