यह मार्गदर्शिका लैंगचेन में वार्तालाप सारांश का उपयोग करने की प्रक्रिया का वर्णन करेगी।
लैंगचेन में वार्तालाप सारांश का उपयोग कैसे करें?
लैंगचेन कन्वर्सेशनसुमरीमेमोरी जैसी लाइब्रेरी प्रदान करता है जो चैट या बातचीत का पूरा सारांश निकाल सकता है। इसका उपयोग चैट में उपलब्ध सभी संदेशों और टेक्स्ट को पढ़े बिना बातचीत की मुख्य जानकारी प्राप्त करने के लिए किया जा सकता है।
लैंगचेन में वार्तालाप सारांश का उपयोग करने की प्रक्रिया सीखने के लिए, बस निम्नलिखित चरणों का पालन करें:
चरण 1: मॉड्यूल स्थापित करें
सबसे पहले, निम्नलिखित कोड का उपयोग करके इसकी निर्भरता या लाइब्रेरी प्राप्त करने के लिए लैंगचेन फ्रेमवर्क स्थापित करें:
पाइप लैंगचैन स्थापित करें
अब, पाइप कमांड का उपयोग करके लैंगचेन स्थापित करने के बाद ओपनएआई मॉड्यूल स्थापित करें:
पिप इंस्टाल ओपनाई 
मॉड्यूल स्थापित करने के बाद, बस पर्यावरण स्थापित करें OpenAI खाते से API कुंजी प्राप्त करने के बाद निम्नलिखित कोड का उपयोग करें:
आयात आपआयात पास ले लो
आप . लगभग [ 'OPENAI_API_KEY' ] = पास ले लो . पास ले लो ( 'ओपनएआई एपीआई कुंजी:' )
चरण 2: वार्तालाप सारांश का उपयोग करना
लैंगचेन से लाइब्रेरी आयात करके वार्तालाप सारांश का उपयोग करने की प्रक्रिया में शामिल हों:
से लैंगचैन. याद आयात वार्तालापसारांशस्मृति , चैटमैसेजइतिहाससे लैंगचैन. एलएमएस आयात ओपनएआई
ConversationSummaryMemory() और OpenAI() विधियों का उपयोग करके मॉडल की मेमोरी को कॉन्फ़िगर करें और इसमें डेटा सहेजें:
याद = वार्तालापसारांशस्मृति ( एलएलएम = ओपनएआई ( तापमान = 0 ) )याद। save_context ( { 'इनपुट' : 'नमस्ते' } , { 'आउटपुट' : 'नमस्ते' } )
को कॉल करके मेमोरी चलाएँ लोड_मेमोरी_वेरिएबल्स() मेमोरी से डेटा निकालने की विधि:
याद। लोड_मेमोरी_वेरिएबल्स ( { } ) 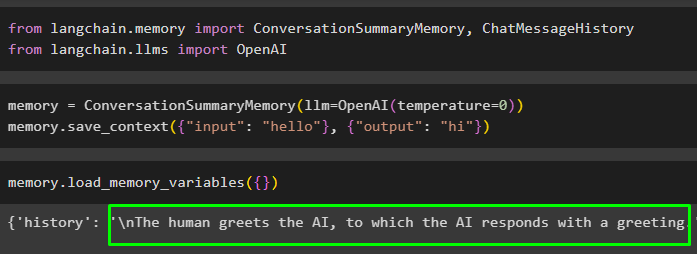
उपयोगकर्ता प्रत्येक इकाई की तरह एक अलग संदेश के साथ बातचीत के रूप में भी डेटा प्राप्त कर सकता है:
याद = वार्तालापसारांशस्मृति ( एलएलएम = ओपनएआई ( तापमान = 0 ) , वापसी_संदेश = सत्य )याद। save_context ( { 'इनपुट' : 'नमस्ते' } , { 'आउटपुट' : 'हाय आप कैसे हैं' } )
AI और इंसानों का संदेश अलग-अलग प्राप्त करने के लिए,load_memory_variables() विधि निष्पादित करें:
याद। लोड_मेमोरी_वेरिएबल्स ( { } ) 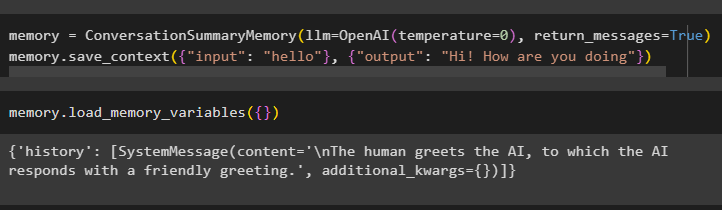
बातचीत के सारांश को मेमोरी में संग्रहीत करें और फिर स्क्रीन पर चैट/बातचीत का सारांश प्रदर्शित करने के लिए मेमोरी को निष्पादित करें:
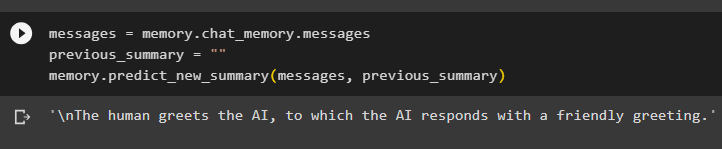
संदेशों = याद। चैट_मेमोरी . संदेशोंपिछला_सारांश = ''
याद। भविष्यवाणी_नया_सारांश ( संदेशों , पिछला_सारांश )
चरण 3: मौजूदा संदेशों के साथ वार्तालाप सारांश का उपयोग करना
उपयोगकर्ता ChatMessageHistory() संदेश का उपयोग करके कक्षा या चैट के बाहर मौजूद बातचीत का सारांश भी प्राप्त कर सकता है। इन संदेशों को मेमोरी में जोड़ा जा सकता है ताकि यह स्वचालित रूप से पूरी बातचीत का सारांश उत्पन्न कर सके:
इतिहास = चैटमैसेजइतिहास ( )इतिहास। add_user_message ( 'नमस्ते' )
इतिहास। add_ai_message ( 'नमस्ते!' )
मौजूदा संदेशों को निष्पादित करने के लिए OpenAI() पद्धति का उपयोग करके LLM जैसे मॉडल का निर्माण करें चैट_मेमोरी चर:
याद = वार्तालापसारांशस्मृति। from_messages (एलएलएम = ओपनएआई ( तापमान = 0 ) ,
चैट_मेमोरी = इतिहास ,
वापसी_संदेश = सत्य
)
मौजूदा संदेशों का सारांश प्राप्त करने के लिए बफ़र का उपयोग करके मेमोरी निष्पादित करें:
याद। बफर 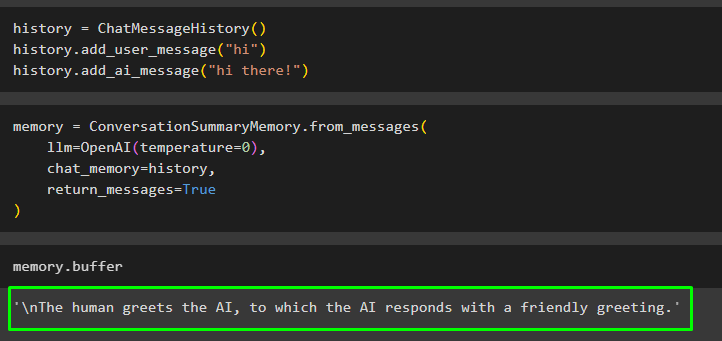
चैट संदेशों का उपयोग करके बफर मेमोरी को कॉन्फ़िगर करके एलएलएम बनाने के लिए निम्नलिखित कोड निष्पादित करें:
याद = वार्तालापसारांशस्मृति (एलएलएम = ओपनएआई ( तापमान = 0 ) ,
बफर = ''मानव मशीन से अपने बारे में पूछता है
सिस्टम उत्तर देता है कि AI भलाई के लिए बनाया गया है क्योंकि यह मनुष्यों को उनकी क्षमता हासिल करने में मदद कर सकता है'' ,
चैट_मेमोरी = इतिहास ,
वापसी_संदेश = सत्य
)
चरण 4: श्रृंखला में वार्तालाप सारांश का उपयोग करना
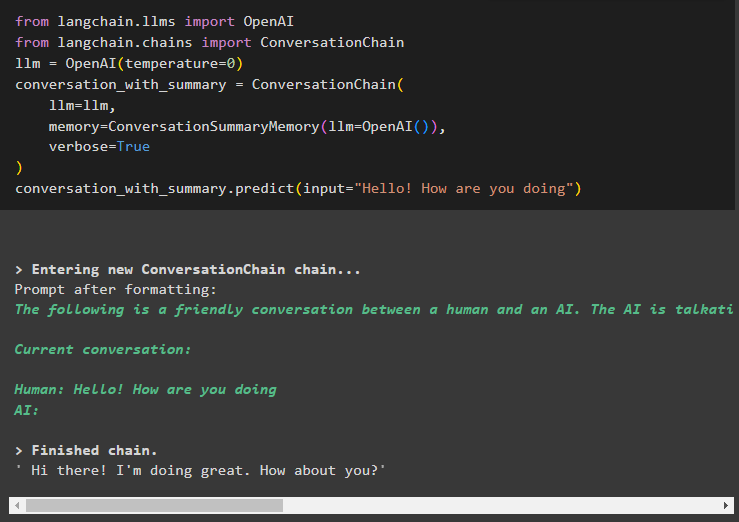
अगला चरण एलएलएम का उपयोग करके एक श्रृंखला में वार्तालाप सारांश का उपयोग करने की प्रक्रिया को समझाता है:
से लैंगचैन. एलएमएस आयात ओपनएआईसे लैंगचैन. चेन आयात वार्तालाप शृंखला
एलएलएम = ओपनएआई ( तापमान = 0 )
बातचीत_साथ_सारांश = वार्तालाप शृंखला (
एलएलएम = एलएलएम ,
याद = वार्तालापसारांशस्मृति ( एलएलएम = ओपनएआई ( ) ) ,
वाचाल = सत्य
)
बातचीत_साथ_सारांश. भविष्यवाणी करना ( इनपुट = 'नमस्ते, आप कैसे हैं' )
यहां हमने विनम्र पूछताछ के साथ बातचीत शुरू करके श्रृंखलाएं बनाना शुरू कर दिया है:
अब इस पर विस्तार करने के लिए अंतिम आउटपुट के बारे में थोड़ा और पूछकर बातचीत में शामिल हों:
बातचीत_साथ_सारांश. भविष्यवाणी करना ( इनपुट = 'इसके बारे में मुझे अधिक बताओ!' )मॉडल ने एआई तकनीक या चैटबॉट के विस्तृत परिचय के साथ अंतिम संदेश को समझाया है:
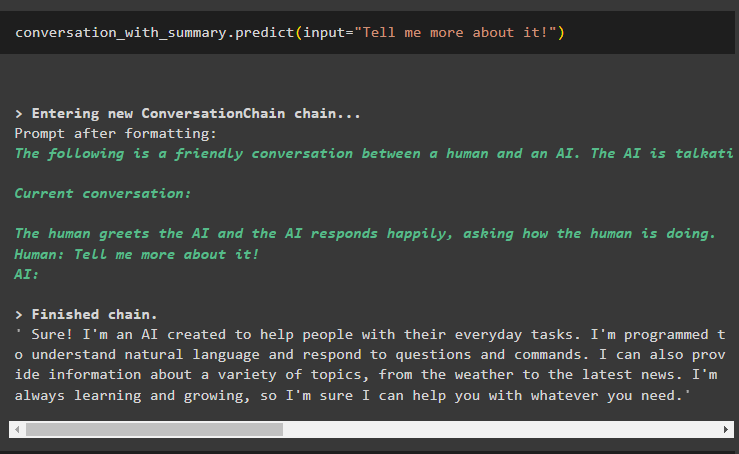
बातचीत को एक विशिष्ट दिशा में ले जाने के लिए पिछले आउटपुट से रुचि का एक बिंदु निकालें:
बातचीत_साथ_सारांश. भविष्यवाणी करना ( इनपुट = 'आश्चर्यजनक यह प्रोजेक्ट कितना अच्छा है?' )यहां हम वार्तालाप सारांश मेमोरी लाइब्रेरी का उपयोग करके बॉट से विस्तृत उत्तर प्राप्त कर रहे हैं:
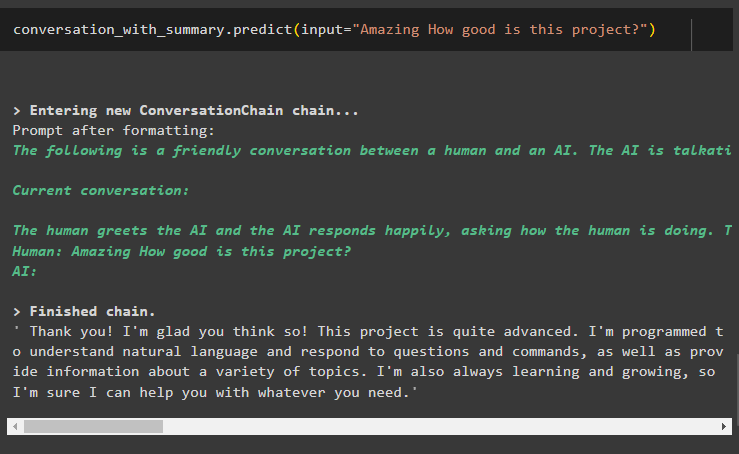
यह सब लैंगचेन में वार्तालाप सारांश का उपयोग करने के बारे में है।
निष्कर्ष
लैंगचेन में वार्तालाप सारांश संदेश का उपयोग करने के लिए, बस पर्यावरण स्थापित करने के लिए आवश्यक मॉड्यूल और फ्रेमवर्क स्थापित करें। एक बार वातावरण सेट हो जाने पर, आयात करें वार्तालापसारांशस्मृति OpenAI() विधि का उपयोग करके एलएलएम बनाने के लिए लाइब्रेरी। उसके बाद, मॉडल से विस्तृत आउटपुट निकालने के लिए बस वार्तालाप सारांश का उपयोग करें जो कि पिछली बातचीत का सारांश है। इस गाइड में लैंगचेन मॉड्यूल का उपयोग करके वार्तालाप सारांश मेमोरी का उपयोग करने की प्रक्रिया के बारे में विस्तार से बताया गया है।