यह मार्गदर्शिका बताएगी कि लैंगचेन फ्रेमवर्क का उपयोग करके वेक्टरस्टोररिट्रीवरमेमोरी का उपयोग कैसे करें।
लैंगचेन में वेक्टरस्टोररिट्रीवरमेमोरी का उपयोग कैसे करें?
वेक्टरस्टोररिट्रीवरमेमोरी लैंगचेन की लाइब्रेरी है जिसका उपयोग वेक्टर स्टोर्स का उपयोग करके मेमोरी से जानकारी/डेटा निकालने के लिए किया जा सकता है। प्रॉम्प्ट या क्वेरी के अनुसार जानकारी को कुशलतापूर्वक निकालने के लिए डेटा को संग्रहीत और प्रबंधित करने के लिए वेक्टर स्टोर का उपयोग किया जा सकता है।
लैंगचेन में वेक्टरस्टोररिट्रीवरमेमोरी का उपयोग करने की प्रक्रिया सीखने के लिए, बस निम्नलिखित गाइड पर जाएं:
चरण 1: मॉड्यूल स्थापित करें
पाइप कमांड का उपयोग करके लैंगचेन स्थापित करके मेमोरी रिट्रीवर का उपयोग करने की प्रक्रिया शुरू करें:
पाइप लैंगचैन स्थापित करें
सिमेंटिक समानता खोज का उपयोग करके डेटा प्राप्त करने के लिए FAISS मॉड्यूल स्थापित करें:
पिप इंस्टाल faiss-gpu 
Chroma डेटाबेस का उपयोग करने के लिए chromadb मॉड्यूल स्थापित करें। यह रिट्रीवर के लिए मेमोरी बनाने के लिए वेक्टर स्टोर के रूप में काम करता है:
पाइप क्रोमैडबी स्थापित करें 
इंस्टॉल करने के लिए एक अन्य मॉड्यूल टिकटोकन की आवश्यकता होती है जिसका उपयोग डेटा को छोटे टुकड़ों में परिवर्तित करके टोकन बनाने के लिए किया जा सकता है:
पिप टिकटोकन इंस्टॉल करें 
अपने वातावरण का उपयोग करके एलएलएम या चैटबॉट बनाने के लिए अपनी लाइब्रेरी का उपयोग करने के लिए ओपनएआई मॉड्यूल स्थापित करें:
पिप इंस्टाल ओपनाई 
वातावरण स्थापित करें OpenAI खाते से API कुंजी का उपयोग करके Python IDE या नोटबुक पर:
आयात आपआयात पास ले लो
आप . लगभग [ 'OPENAI_API_KEY' ] = पास ले लो . पास ले लो ( 'ओपनएआई एपीआई कुंजी:' )
चरण 2: पुस्तकालय आयात करें
अगला कदम लैंगचेन में मेमोरी रिट्रीवर का उपयोग करने के लिए इन मॉड्यूल से लाइब्रेरी प्राप्त करना है:
से लैंगचैन. संकेतों आयात संकेत टेम्पलेटसे दिनांक समय आयात दिनांक समय
से लैंगचैन. एलएमएस आयात ओपनएआई
से लैंगचैन. एम्बेडिंग . openai आयात ओपनएआईएम्बेडिंग्स
से लैंगचैन. चेन आयात वार्तालाप शृंखला
से लैंगचैन. याद आयात वेक्टरस्टोररिट्रीवरमेमोरी
चरण 3: वेक्टर स्टोर प्रारंभ करना
यह गाइड इनपुट कमांड का उपयोग करके डेटा निकालने के लिए FAISS लाइब्रेरी को आयात करने के बाद क्रोमा डेटाबेस का उपयोग करता है:
आयात faissसे लैंगचैन. डॉक्टर की दुकान आयात इनमेमोरीडॉकस्टोर
#डेटाबेस या वेक्टर स्टोर को कॉन्फ़िगर करने के लिए लाइब्रेरी आयात करना
से लैंगचैन. वेक्टरस्टोर्स आयात FAISS
#वेक्टर स्टोर्स में संग्रहीत करने के लिए एम्बेडिंग और टेक्स्ट बनाएं
एम्बेडिंग_आकार = 1536
अनुक्रमणिका = faiss. IndexFlatL2 ( एम्बेडिंग_आकार )
एम्बेडिंग_एफएन = ओपनएआईएम्बेडिंग्स ( ) . एंबेड_क्वेरी
वेक्टरस्टोर = FAISS ( एम्बेडिंग_एफएन , अनुक्रमणिका , इनमेमोरीडॉकस्टोर ( { } ) , { } )
चरण 4: वेक्टर स्टोर द्वारा समर्थित रिट्रीवर का निर्माण
बातचीत में नवीनतम संदेशों को संग्रहीत करने और चैट का संदर्भ प्राप्त करने के लिए मेमोरी बनाएं:
कुत्ता = वेक्टरस्टोर। as_retriever ( search_kwargs = हुक्म ( क = 1 ) )याद = वेक्टरस्टोररिट्रीवरमेमोरी ( कुत्ता = कुत्ता )
याद। save_context ( { 'इनपुट' : 'मुझे पिज़्ज़ा खाना पसंद है' } , { 'आउटपुट' : 'ज़बरदस्त' } )
याद। save_context ( { 'इनपुट' : 'मैं फुटबॉल में अच्छा हूँ' } , { 'आउटपुट' : 'ठीक है' } )
याद। save_context ( { 'इनपुट' : 'मुझे राजनीति पसंद नहीं' } , { 'आउटपुट' : 'ज़रूर' } )
उपयोगकर्ता द्वारा उसके इतिहास के साथ प्रदान किए गए इनपुट का उपयोग करके मॉडल की मेमोरी का परीक्षण करें:
छपाई ( याद। लोड_मेमोरी_वेरिएबल्स ( { 'तत्पर' : 'मुझे कौन सा खेल देखना चाहिए?' } ) [ 'इतिहास' ] ) 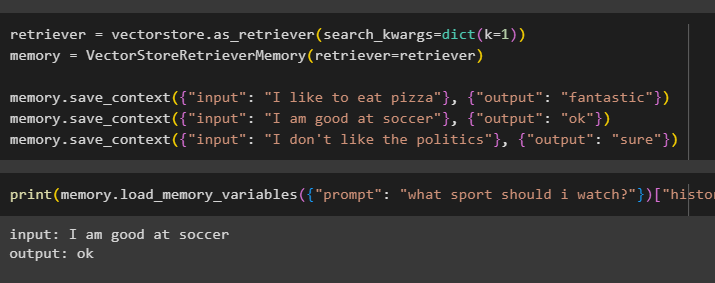
चरण 5: एक श्रृंखला में रिट्रीवर का उपयोग करना
अगला चरण OpenAI() विधि का उपयोग करके एलएलएम का निर्माण करके और प्रॉम्प्ट टेम्पलेट को कॉन्फ़िगर करके श्रृंखलाओं के साथ मेमोरी रिट्रीवर का उपयोग करना है:
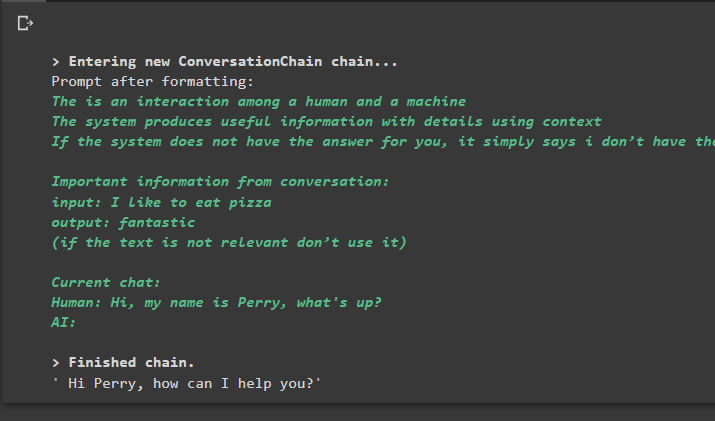
एलएलएम = ओपनएआई ( तापमान = 0 )_डिफ़ॉल्ट टेम्पलेट = '''यह एक इंसान और एक मशीन के बीच की बातचीत है
सिस्टम संदर्भ का उपयोग करके विवरण के साथ उपयोगी जानकारी तैयार करता है
यदि सिस्टम के पास आपके लिए उत्तर नहीं है, तो वह बस यही कहता है कि मेरे पास उत्तर नहीं है
बातचीत से महत्वपूर्ण जानकारी:
{इतिहास}
(यदि पाठ प्रासंगिक नहीं है तो इसका उपयोग न करें)
वर्तमान चैट:
मानव: {इनपुट}
ऐ:'''
तत्पर = संकेत टेम्पलेट (
इनपुट_चर = [ 'इतिहास' , 'इनपुट' ] , खाका = _डिफ़ॉल्ट टेम्पलेट
)
#ConversationChain() को इसके पैरामीटर्स के मानों का उपयोग करके कॉन्फ़िगर करें
बातचीत_साथ_सारांश = वार्तालाप शृंखला (
एलएलएम = एलएलएम ,
तत्पर = तत्पर ,
याद = याद ,
वाचाल = सत्य
)
बातचीत_साथ_सारांश. भविष्यवाणी करना ( इनपुट = 'हाय, मेरा नाम पेरी है, क्या हाल है?' )
उत्पादन
कमांड निष्पादित करने से श्रृंखला चलती है और मॉडल या एलएलएम द्वारा प्रदान किया गया उत्तर प्रदर्शित होता है:
वेक्टर स्टोर में संग्रहीत डेटा के आधार पर संकेत का उपयोग करके बातचीत जारी रखें:
बातचीत_साथ_सारांश. भविष्यवाणी करना ( इनपुट = 'मेरा पसंदीदा खेल क्या है?' ) 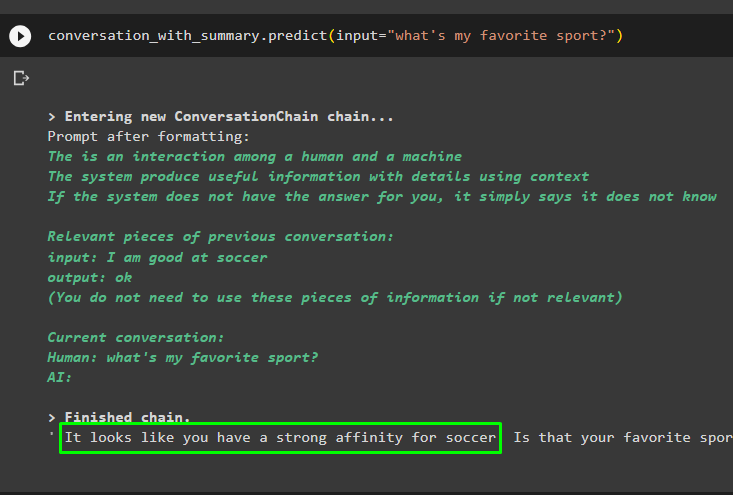
पिछले संदेशों को मॉडल की मेमोरी में संग्रहीत किया जाता है जिसका उपयोग मॉडल द्वारा संदेश के संदर्भ को समझने के लिए किया जा सकता है:
बातचीत_साथ_सारांश. भविष्यवाणी करना ( इनपुट = 'मेरा पसंदीदा खाना क्या है' ) 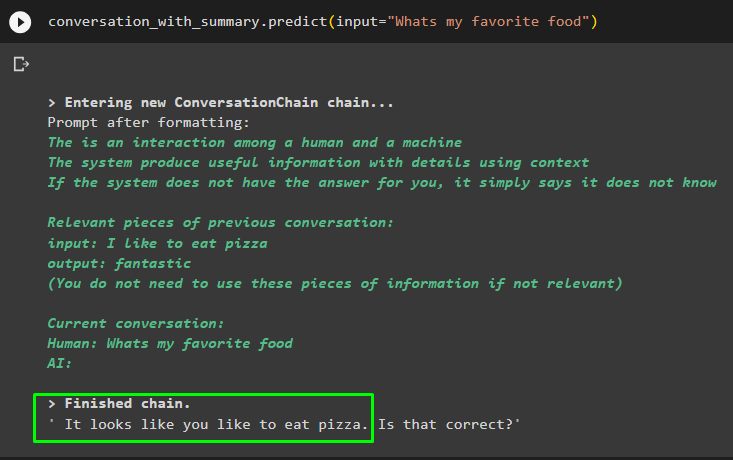
यह जांचने के लिए कि मेमोरी रिट्रीवर चैट मॉडल के साथ कैसे काम कर रहा है, पिछले संदेशों में से एक में मॉडल को दिया गया उत्तर प्राप्त करें:
बातचीत_साथ_सारांश. भविष्यवाणी करना ( इनपुट = 'मेरा नाम क्या है?' )मॉडल ने मेमोरी में संग्रहीत डेटा से समानता खोज का उपयोग करके आउटपुट को सही ढंग से प्रदर्शित किया है:
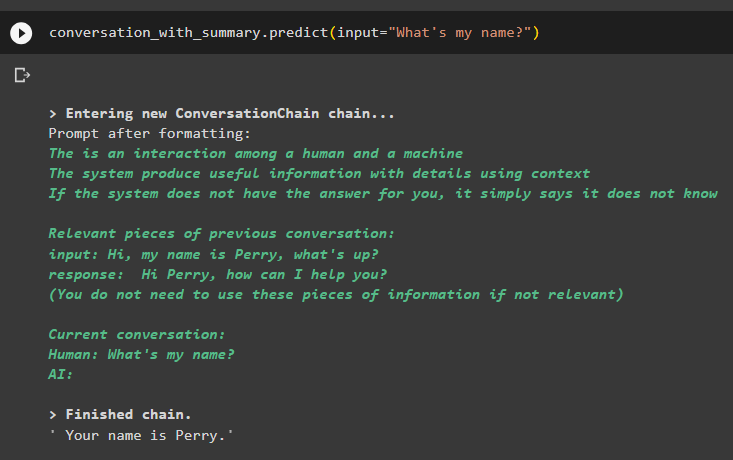
यह सब लैंगचेन में वेक्टर स्टोर रिट्रीवर का उपयोग करने के बारे में है।
निष्कर्ष
लैंगचेन में वेक्टर स्टोर पर आधारित मेमोरी रिट्रीवर का उपयोग करने के लिए, बस मॉड्यूल और फ्रेमवर्क स्थापित करें और पर्यावरण सेट करें। उसके बाद, क्रोमा का उपयोग करके डेटाबेस बनाने के लिए मॉड्यूल से लाइब्रेरी आयात करें और फिर प्रॉम्प्ट टेम्पलेट सेट करें। मेमोरी में डेटा संग्रहीत करने के बाद बातचीत शुरू करके और पिछले संदेशों से संबंधित प्रश्न पूछकर रिट्रीवर का परीक्षण करें। इस गाइड में लैंगचेन में वेक्टरस्टोररिट्रीवरमेमोरी लाइब्रेरी का उपयोग करने की प्रक्रिया के बारे में विस्तार से बताया गया है।