उलटना (नॉलेज एक्सट्रैक्शन बेस्ड ऑन इवोल्यूशनरी लर्निंग) एक जावा-आधारित सॉफ्टवेयर टूल है जो विकासवादी एल्गोरिदम के कार्यान्वयन में माहिर है। चूंकि यह एक खुला स्रोत है, इसलिए यह विभिन्न प्रकार के ज्ञान खोज एल्गोरिदम प्रदान करता है जिनका प्रयोग उन प्रयोगों में किया जा सकता है जो डेटा खनन और विश्लेषण समुदाय को शक्ति प्रदान करते हैं। यह एक सरल और उपयोग में आसान ग्राफिकल यूजर इंटरफेस प्रदान करता है जो इस टूल की समग्र जटिलता को काफी कम कर देता है। बाजार पर अधिकांश समान उपकरणों के लिए उपयोगकर्ताओं को कोड लिखकर उनके साथ बातचीत करने की आवश्यकता होती है, जबकि कील इस आवश्यकता को एक सहज ज्ञान युक्त जीयूआई प्रदान करके हटा देता है जिसका उपयोग शुरुआती और विशेषज्ञों द्वारा समान रूप से किया जा सकता है।
कील वर्गीकरण, प्रतिगमन, सुविधा निष्कर्षण, पैटर्न विश्लेषण, क्लस्टरिंग, और अधिक सहित विभिन्न कम्प्यूटेशनल इंटेलिजेंस-आधारित एल्गोरिदम की एक विस्तृत विविधता प्रदान करता है। मुख्य धारा के मॉडल को एप्लिकेशन में ही बेक करने के साथ, कच्चे डेटा सेट पर खोजपूर्ण डेटा विश्लेषण करने की बात आने पर कील एक बहुत ही उपयोगी उपकरण है। कार्यक्षमता उपयोग में आसानी के साथ जोड़ा गया इसका सरल ड्रैग एंड ड्रॉप इंटरफ़ेस शैक्षिक और अनुसंधान दोनों उद्देश्यों के लिए त्वरित और कुशल डेटा खनन प्रयोग की अनुमति देता है। अन्यथा जटिल एल्गोरिथम प्रथाओं के लिए उनके सरलीकृत दृष्टिकोण के कारण कील जैसे उपकरण लोकप्रियता में बढ़ रहे हैं।
इंस्टालेशन
दो मुख्य तरीके हैं जिनसे हम स्थापित कर सकते हैं उलटना किसी भी लिनक्स मशीन पर। पहले में जाना शामिल है कील वेबपेज और वहां से सॉफ्टवेयर डाउनलोड करना। दूसरा, जिसका हम इस इंस्टॉलेशन गाइड में पालन करेंगे, हमें कील को डाउनलोड करने की आवश्यकता है wget लिनक्स उपयोगकर्ताओं के लिए डाउनलोड टूल उपलब्ध है।
1. हम प्राप्त करके प्रारंभ करते हैं wget हमारे लिनक्स मशीन पर।
Wget का उपयोग करके डाउनलोड करने के लिए निम्न कमांड चलाएँ उपयुक्त पैकेज प्रबंधक:
$ सुडो उपयुक्त-स्थापित करें wget
आप एक समान टर्मिनल आउटपुट देखेंगे:
2. अब जब हमारे पास है wget उपकरण हमारे लिनक्स मशीन पर स्थापित है, हम इसे डाउनलोड करने के लिए उपयोग करते हैं उलटना औजार।
यह है संपर्क कि हम wget को पास करते हैं।
अपने टर्मिनल में निम्न कमांड चलाएँ:
$ wget एचटीटीपी: // sci2s.ugr.es / उलटना / सॉफ़्टवेयर / प्रोटोटाइप / openVersion / सॉफ़्टवेयर- 2018 -04-09.ज़िप
आपको अपने टर्मिनल पर एक समान आउटपुट देखना चाहिए:
एक बार कील का डाउनलोड पूरा हो जाने के बाद, हम शेष इंस्टालेशन के साथ जारी रख सकते हैं।
3. अब हम कंप्रेस्ड फ़ाइल को एक्सट्रेक्ट करते हैं जिसे हमने Linux Unzip टूल का उपयोग करके पिछले चरण में डाउनलोड किया था।
निम्नलिखित आदेश चलाएँ:
$ खोलना सॉफ़्टवेयर- 2018 -04-09.ज़िप
आपको टर्मिनल में एक समान आउटपुट देखना चाहिए:
4. निम्न आदेश चलाकर कील फ़ोल्डर में नेविगेट करें:
$ सीडी सॉफ़्टवेयर- 2018 -04-09 / दस्तावेजों / प्रयोगों / उलटना / जिले /
5. स्थापना के साथ शुरू करने के लिए निम्नलिखित कमांड चलाएँ:
$ जावा -जार . / ग्राफइंटरकील.जर
इसके साथ, आपके लिनक्स मशीन पर उपयोग करने के लिए कील उपलब्ध होना चाहिए।
उपयोगकर्ता गाइड
के साथ बातचीत करना उलटना आवेदन वास्तव में आसान और सरल है। आइए आयात करके शुरू करें आईरिस डेटा सेट हमारे कार्यक्षेत्र में।
जैसे ही हम डेटा आयात करते हैं, टूल हमें डेटा सेट में डेटा बिंदु की समग्र क्लस्टरिंग दिखाता है। यह हमें उन विभिन्न वर्गों को भी दिखाता है जो डेटा सेट में मौजूद हैं, साथ ही बुनियादी जानकारी जैसे कि संख्यात्मक श्रेणियां जो इन डेटा बिंदुओं तक फैली हुई हैं और समग्र भिन्नता और औसत मूल्य मौजूद हैं। यह जानकारी उपयोगकर्ताओं को बेहतर ढंग से समझने की अनुमति देती है कि किसी भी प्रकार के डेटा विश्लेषण कार्य के लिए डेटा तैयारी के साथ कैसे आगे बढ़ना है।
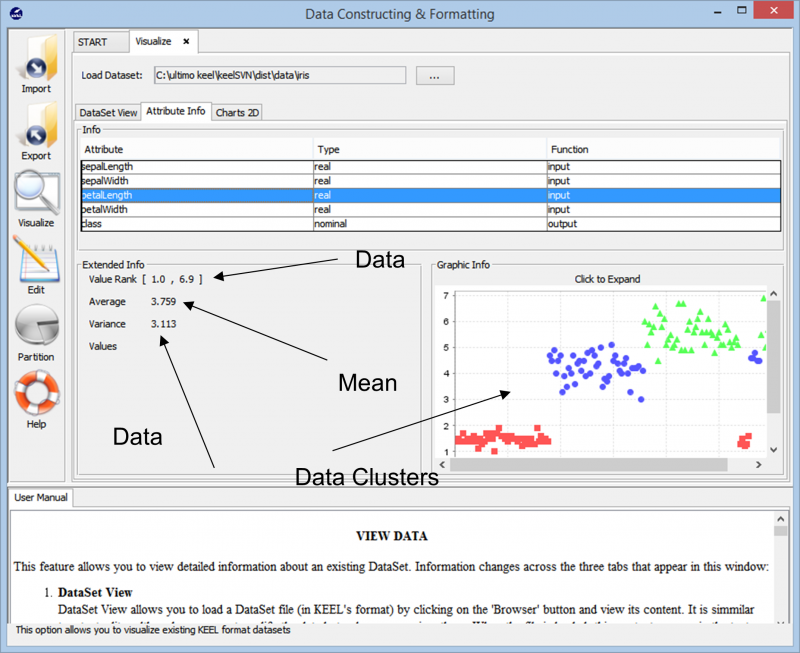
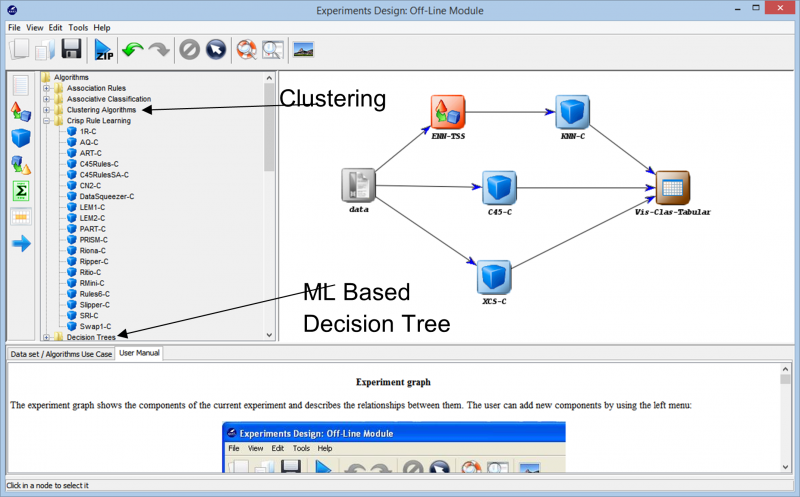
प्रयोग में आगे बढ़ते हुए, हम विभिन्न तकनीकों के संपर्क में आते हैं जिनका उपयोग किसी भी डेटा सेट पर हमारे प्रयोग को बनाने के लिए किया जा सकता है। हमारे डेटा पर इस्तेमाल किए जा सकने वाले अलग-अलग लर्निंग एल्गोरिदम को नीचे दी गई तस्वीर में देखा जा सकता है। डेटा सेट की प्रकृति और प्रयोग की आवश्यकताओं के आधार पर, विभिन्न एल्गोरिदम का प्रयोग किया जा सकता है।
उदाहरण के लिए, यदि आप बिना लेबल वाले डेटा के साथ काम कर रहे हैं और आपको अपने डेटा सेट में विभिन्न डेटा बिंदुओं के बीच समानताएं ढूंढनी हैं, तो उपलब्ध विभिन्न विकल्पों में से क्लस्टरिंग एल्गोरिथम का उपयोग करने से आपको डेटा बिंदुओं को बेहतर ढंग से समझने में मदद मिल सकती है। यह अंततः आपको डेटा बिंदुओं को लेबल और वर्गीकृत करने में मदद करता है ताकि प्रयोग को अधिक व्यापक पर्यवेक्षित शिक्षण एल्गोरिदम का उपयोग करके बनाया जा सके।
निष्कर्ष
उलटना डेटा एनालिटिक्स के लिए मंच अनुसंधान और शैक्षिक दोनों उद्देश्यों के लिए एक अच्छा संसाधन है। यह उपयोग में आसान ग्राफिकल यूजर इंटरफेस है जो उपयोगकर्ताओं को डेटा की आवश्यकताओं को बेहतर ढंग से समझने में मदद करता है साथ ही सहायक तकनीकों और एल्गोरिदम के तार्किक संदर्भ प्रदान करता है जो उपयोगकर्ताओं को उनके वर्कफ़्लोज़ में सहायता करते हैं। विभिन्न श्रेणियों और एल्गोरिथम तकनीकों के अंतर्गत आने वाले विभिन्न एल्गोरिदम की एक विस्तृत श्रृंखला होने से उपयोगकर्ता कई तार्किक दिशाओं के साथ प्रयोग कर सकते हैं और इन परिणामों की तुलना कर सकते हैं ताकि किसी भी समस्या का सबसे इष्टतम समाधान प्राप्त किया जा सके।
डाटा माइनिंग के लिए कील का कोड फ्री ड्रैग एंड ड्रॉप एप्रोच शुरुआती लोगों को भी व्यापक कम्प्यूटेशनल इंटेलिजेंस मॉडल के साथ सहजता से काम करने में मदद करता है। यह जटिल डेटा सेट में अंतर्दृष्टि प्रदान करता है और इसके परिणामस्वरूप उपयोगी संदर्भ प्राप्त करता है जो वास्तविक दुनिया की समस्याओं को हल करने में मदद करता है।