{ नाम: 'एलेक्सा बिल' , श्रेणी: 'ए' , अवधि: 'अजगर' },
{ नाम: 'जेन मार्क्स' , श्रेणी: 'बी' , अवधि: 'जावा' },
{ नाम: 'पॉल केन' , श्रेणी: 'सी' , अवधि: 'सी#' },
{ नाम: 'एमिली जियो' , श्रेणी: 'डी' , अवधि: 'php' }
]);
जब संग्रह कुछ दस्तावेज़ों के साथ मौजूद हो तो हम एक अद्वितीय अनुक्रमणिका फ़ील्ड भी बना सकते हैं। इसके लिए, हम दस्तावेज़ को नए संग्रह में सम्मिलित करते हैं जो 'उम्मीदवार' है जिनकी प्रविष्टि के लिए क्वेरी इस प्रकार दी गई है:
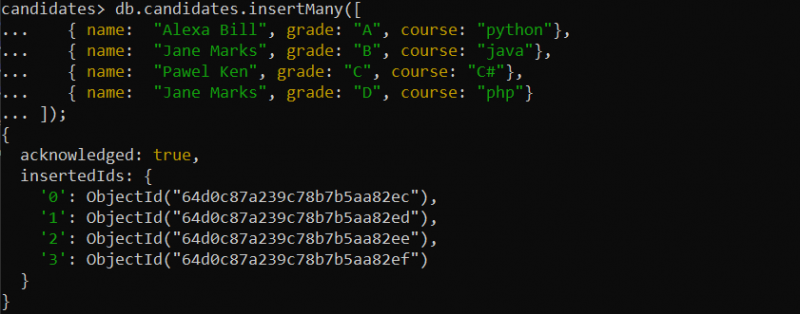
उदाहरण 1: एकल फ़ील्ड का एक अद्वितीय सूचकांक बनाएं
हम createIndex() विधि का उपयोग करके इंडेक्स बना सकते हैं और हम बूलियन 'सत्य' के साथ अद्वितीय विकल्प निर्दिष्ट करके उस फ़ील्ड को अद्वितीय बना सकते हैं।
db.candidates.createIndex( {ग्रेड: 1 }, { अद्वितीय: सत्य } )
यहां, हम एक विशिष्ट क्षेत्र का एक अद्वितीय सूचकांक बनाने के लिए 'उम्मीदवारों' संग्रह पर createIndex() विधि शुरू करते हैं। फिर, हम सूचकांक विनिर्देश के लिए '1' के मान के साथ 'ग्रेड' फ़ील्ड प्रदान करते हैं। यहां '1' का मान संग्रह के आरोही सूचकांक को दर्शाता है। इसके बाद, हम फ़ील्ड 'ग्रेड' की विशिष्टता को लागू करने के लिए 'सही' मान के साथ 'अद्वितीय' विकल्प निर्दिष्ट करते हैं।
आउटपुट दर्शाता है कि 'ग्रेड' फ़ील्ड पर अद्वितीय सूचकांक 'उम्मीदवारों' संग्रह के लिए बनाया गया है:

उदाहरण 2: एक से अधिक फ़ील्ड का एक अद्वितीय सूचकांक बनाएं
पिछले उदाहरण में, केवल एक फ़ील्ड को अद्वितीय सूचकांक के रूप में बनाया गया है। लेकिन हम createIndex() विधि का उपयोग करके एक साथ दो फ़ील्ड को एक अद्वितीय इंडेक्स के रूप में भी बना सकते हैं।
db.candidates.createIndex( {ग्रेड: 1 , अवधि: 1 }, { अद्वितीय: सत्य } )
यहां, हम उसी 'उम्मीदवारों' संग्रह पर createIndex() विधि को कॉल करते हैं। हम createIndex() विधि में दो फ़ील्ड निर्दिष्ट करते हैं - 'ग्रेड' और 'पाठ्यक्रम' - पहली अभिव्यक्ति के रूप में '1' के मान के साथ। फिर, हम इन दो अद्वितीय फ़ील्ड बनाने के लिए 'सही' मान के साथ अद्वितीय विकल्प सेट करते हैं।
निम्नलिखित 'उम्मीदवारों' संग्रह के लिए आउटपुट दो अद्वितीय सूचकांक, 'ग्रेड_1' और 'कोर्स_1' का प्रतिनिधित्व करता है:

उदाहरण 3: फ़ील्ड्स का एक मिश्रित अद्वितीय सूचकांक बनाएं
हालाँकि, हम एक ही संग्रह में एक साथ एक अद्वितीय यौगिक सूचकांक भी बना सकते हैं। हम इसे निम्नलिखित क्वेरी के माध्यम से प्राप्त करते हैं:
db.candidates.createIndex( {नाम: 1 , श्रेणी: 1 , अवधि: 1 }, { अद्वितीय: सत्य }हम 'उम्मीदवारों' संग्रह के लिए मिश्रित अद्वितीय सूचकांक बनाने के लिए फिर से createIndex() विधि का उपयोग करते हैं। इस बार, हम तीन फ़ील्ड पास करते हैं - 'ग्रेड', 'नाम,' और 'पाठ्यक्रम' - जो 'उम्मीदवारों' संग्रह के लिए आरोही सूचकांक फ़ील्ड के रूप में कार्य करते हैं। इसके बाद, हम फ़ील्ड को अद्वितीय बनाने के लिए 'अद्वितीय' विकल्प कहते हैं क्योंकि उस विकल्प के सामने 'सही' निर्दिष्ट है।
आउटपुट परिणाम प्रदर्शित करता है जो दर्शाता है कि सभी तीन फ़ील्ड अब निर्दिष्ट संग्रह के अद्वितीय सूचकांक हैं:

उदाहरण 4: डुप्लिकेट फ़ील्ड मानों का एक अद्वितीय सूचकांक बनाएं
अब, हम डुप्लिकेट फ़ील्ड मान के लिए अद्वितीय सूचकांक बनाने का प्रयास करते हैं जो विशिष्टता बाधा को बनाए रखने के लिए एक त्रुटि उत्पन्न करता है।
db.candidates.createIndex({नाम: 1 },{अद्वितीय:सत्य})यहां, हम उस फ़ील्ड के लिए अद्वितीय सूचकांक मानदंड लागू करते हैं जिसमें समान मान शामिल हैं। createIndex() विधि के अंदर, हम 'नाम' फ़ील्ड को '1' के मान के साथ कॉल करते हैं ताकि इसे एक अद्वितीय सूचकांक बनाया जा सके और अद्वितीय विकल्प को 'सही' मान के साथ परिभाषित किया जा सके। चूँकि दोनों दस्तावेज़ों में समान मानों वाला 'नाम' फ़ील्ड है, इसलिए हम इस फ़ील्ड को 'उम्मीदवारों' संग्रह का एक अद्वितीय सूचकांक नहीं बना सकते। क्वेरी के निष्पादन पर डुप्लिकेट कुंजी त्रुटि उत्पन्न होती है।
जैसा कि अपेक्षित था, आउटपुट परिणाम उत्पन्न करता है क्योंकि नाम फ़ील्ड में दो अलग-अलग दस्तावेज़ों के लिए समान मान हैं:

इस प्रकार, हम दस्तावेज़ में प्रत्येक 'नाम' फ़ील्ड को एक अद्वितीय मान देकर 'उम्मीदवारों' संग्रह को अपडेट करते हैं और फिर 'नाम' फ़ील्ड को अद्वितीय सूचकांक के रूप में बनाते हैं। उस क्वेरी को निष्पादित करने से आम तौर पर 'नाम' फ़ील्ड को अद्वितीय सूचकांक के रूप में बनाया जाता है जैसा कि निम्नलिखित में दिखाया गया है:

उदाहरण 5: किसी छूटे हुए फ़ील्ड का एक अद्वितीय सूचकांक बनाएं
वैकल्पिक रूप से, हम उस फ़ील्ड पर createIndex() विधि लागू करते हैं जो संग्रह के किसी भी दस्तावेज़ में मौजूद नहीं है। परिणामस्वरूप, सूचकांक उस फ़ील्ड के विरुद्ध एक शून्य मान संग्रहीत करता है, और फ़ील्ड के मान के विरुद्ध उल्लंघन के कारण ऑपरेशन विफल हो जाता है।
db.candidates.createIndex( { ईमेल: 1 }, { अद्वितीय: सत्य } )यहां, हम createIndex() विधि का उपयोग करते हैं जहां 'ईमेल' फ़ील्ड '1' के मान के साथ प्रदान की जाती है। 'ईमेल' फ़ील्ड 'उम्मीदवारों' संग्रह में मौजूद नहीं है और हम अद्वितीय विकल्प को 'सही' पर सेट करके इसे 'उम्मीदवारों' संग्रह के लिए एक अद्वितीय सूचकांक बनाने का प्रयास करते हैं।
जब इसके लिए क्वेरी निष्पादित की जाती है, तो हमें आउटपुट में त्रुटि मिलती है क्योंकि 'उम्मीदवार' संग्रह में 'ईमेल' फ़ील्ड गायब है:

उदाहरण 6: विरल विकल्प के साथ किसी फ़ील्ड का एक अद्वितीय सूचकांक बनाएं
इसके बाद, विरल विकल्प के साथ अद्वितीय सूचकांक भी बनाया जा सकता है। विरल सूचकांक की कार्यक्षमता यह है कि इसमें केवल वे दस्तावेज़ शामिल होते हैं जिनमें अनुक्रमित फ़ील्ड होता है, उन दस्तावेज़ों को छोड़कर जिनमें अनुक्रमित फ़ील्ड नहीं होता है। हमने विरल विकल्प को सेटअप करने के लिए निम्नलिखित संरचना प्रदान की है:
db.candidates.createIndex( { पाठ्यक्रम : 1 },{ नाम: 'अद्वितीय_विरल_पाठ्यक्रम_सूचकांक' , अद्वितीय: सत्य, विरल: सत्य } )
यहां, हम createIndex() विधि प्रदान करते हैं जहां 'कोर्स' फ़ील्ड को '1' के मान के साथ सेट किया गया है। उसके बाद, हम एक अद्वितीय इंडेक्स फ़ील्ड सेट करने के लिए अतिरिक्त विकल्प निर्दिष्ट करते हैं जो 'पाठ्यक्रम' है। विकल्पों में 'नाम' शामिल है जो 'unique_sparse_course_index' इंडेक्स सेट करता है। फिर, हमारे पास 'अद्वितीय' विकल्प है जो 'सही' मान के साथ निर्दिष्ट है और 'विरल' विकल्प भी 'सही' पर सेट है।
आउटपुट 'पाठ्यक्रम' फ़ील्ड पर एक अद्वितीय और विरल सूचकांक बनाता है जैसा कि निम्नलिखित में दिखाया गया है:

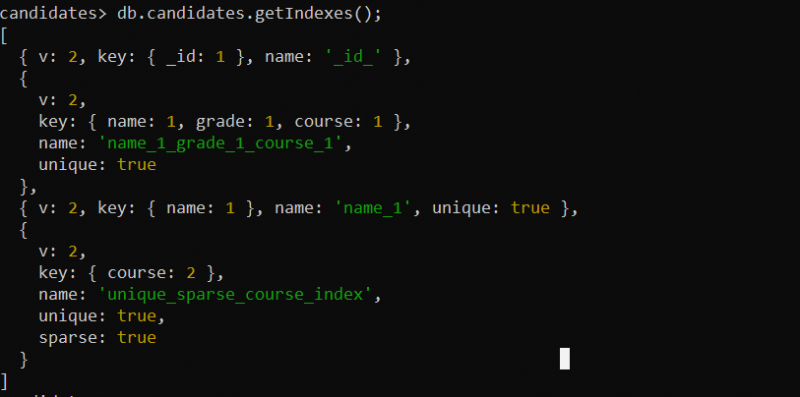
उदाहरण 7: GetIndexes() विधि का उपयोग करके निर्मित अद्वितीय सूचकांक दिखाएं
पिछले उदाहरण में, प्रदत्त संग्रह के लिए केवल एक अद्वितीय सूचकांक बनाया गया था। 'उम्मीदवारों' संग्रह के लिए अद्वितीय अनुक्रमणिका पर जानकारी देखने और प्राप्त करने के लिए, हम निम्नलिखित getIndexes() विधि का उपयोग करते हैं:
db.candidates.getIndexes();यहां, हम 'उम्मीदवारों' संग्रह पर getIndexes() फ़ंक्शन को कॉल करते हैं। GetIndexes() फ़ंक्शन 'उम्मीदवारों' संग्रह के लिए सभी इंडेक्स फ़ील्ड लौटाता है जो हमने पिछले उदाहरणों में बनाया था।
आउटपुट उस अद्वितीय सूचकांक को प्रदर्शित करता है जिसे हमने संग्रह के लिए बनाया है: या तो एक अद्वितीय सूचकांक, यौगिक सूचकांक, या अद्वितीय विरल सूचकांक:
निष्कर्ष
हमने संग्रह के विशिष्ट क्षेत्रों के लिए एक अद्वितीय सूचकांक बनाने का प्रयास किया। हमने एक फ़ील्ड और एकाधिक फ़ील्ड के लिए एक अद्वितीय सूचकांक बनाने के विभिन्न तरीकों का पता लगाया। हमने एक अद्वितीय सूचकांक बनाने का भी प्रयास किया जहां एक अद्वितीय बाधा उल्लंघन के कारण ऑपरेशन विफल हो जाता है।