'पंडस' अजगर पर्यावरण के लिए एक उच्च-प्रदर्शन उपकरण है। यह डेटा के विश्लेषण के लिए एक 'ओपन' सोर्स कोड है। पांडा जुड़ते हैं और पांडा मर्ज विधि का उपयोग दो डेटाफ़्रेम को एक साथ एक डेटाफ़्रेम में जोड़ने के लिए किया जाता है। पांडा के दोनों तरीकों में, अंतर यह है कि पांडा 'जॉइन' फ़ंक्शन एक इंडेक्स का उपयोग करके डेटाफ़्रेम में शामिल होता है। जबकि पांडा 'मर्ज' फ़ंक्शन इंडेक्स और कॉलम विधि का उपयोग करके डेटाफ्रेम में शामिल हो जाता है जिसमें हम स्वयं वांछित कॉलम का चयन कर सकते हैं। पंडों के जुड़ने की विधि की तुलना में पंडों की मर्ज विधि का उपयोग ज्यादातर किया जाता है। कार्यान्वयन के लिए हम जिस सॉफ़्टवेयर का उपयोग करेंगे, वह 'स्पाइडर' सॉफ़्टवेयर है, जो कि अजगर वातावरण में है, जो हमें पांडा जॉइन मेथड () और पांडा मर्ज () मेथड फंक्शन के कोड कार्यान्वयन के लिए लाभ प्रदान करेगा।
पंडों का सिंटैक्स ज्वाइन () विधि
'df1. जोड़ना ( df2 ) 'उपरोक्त सिंटैक्स में 'df' 'डेटाफ़्रेम' का संक्षिप्त नाम है। सिंटैक्स में 'डॉट जॉइन' फ़ंक्शन के साथ दो डेटाफ़्रेम हैं, जो विधि को कॉल करने के लिए है। यह दो डेटाफ्रेम में शामिल होने की पांडा विधि है। यह डेटाफ्रेम को एक में संयोजित करने के लिए इंडेक्स का उपयोग करके काम करता है।
पांडस मर्ज का सिंटैक्स () विधि
'df1. मर्ज ( df2 , पर = 'आम नाम' ) 'पांडा मर्ज विधि सिंटैक्स में 'df1' और 'df2' के रूप में दो डेटाफ़्रेम होते हैं। 'डॉट मर्ज' फ़ंक्शन उल्टे कॉलम की उपस्थिति के साथ दोनों डेटाफ्रेम में शामिल होने की विधि को बुला रहा है।
पांडा मर्ज और पांडा जॉइन के तरीकों का उपयोग करने के लिए हम दो डेटाफ्रेम के संयोजन के निम्नलिखित तरीकों को कवर करेंगे:
- पंडों में शामिल हों विधि अतिव्यापी।
- पांडा इंडेक्स रीसेट का उपयोग करके विधि में शामिल होते हैं।
- पांडा मर्ज विधि (स्तंभ 'बाएं और दाएं')।
- पंडों मर्ज विधि स्पष्ट।
पंडों के विलय और पंडों के जुड़ने की विधि के कार्यान्वयन के लिए डेटाफ्रेम बनाना
सबसे पहले, हमें एक डेटा फ्रेम बनाना होगा। उसके लिए, हम 'स्पाइडर' टूल का उपयोग करेंगे। इसे ओपन करने के बाद कोड लिखना शुरू करें। पांडा लाइब्रेरी एसोसिएशन के लिए पांडा को 'पीडी' के रूप में आयात करें। हमारे पास 'एक्स', 'वाई', 'पी' और 'क्यू संगत रूप से' और 'ए' मानों के साथ '1' और 'बी' के रूप में '2' के रूप में निर्दिष्ट मान के साथ डेटाफ्रेम चर हैं।

आउटपुट एक 'df' है जो असाइन किए गए मानों के साथ बनाया गया है। हम इसे डेटा जितना बड़ा बना सकते हैं।
एक और डेटाफ़्रेम बनाना
पंडों के शामिल होने और पांडा के विलय के तरीकों को स्पष्ट रूप से समझने के लिए हमें एक और डेटाफ्रेम बनाना होगा। यहां, हमने 'df' को उपरोक्त 'df' के समान बनाया है, केवल मान दिए गए चर भिन्न हैं। हमारे पास 'एच', 'जे', 'एस' और 'डी' है, जबकि 'बी' मान '8' और 'वाई' मान '3' के साथ असाइन करें।

आउटपुट बनाया गया एक साधारण 'df' दिखाता है।

उदाहरण # 01: पंडों में शामिल होने की विधि (अतिव्यापी)
अब, हम देखेंगे कि पंडों के जुड़ने की विधि के साथ दो डेटाफ्रेम को कैसे जोड़ा जाए। इस पद्धति के लिए, हम आपकी पसंद का कॉलम चुन सकते हैं, जिस पर हम डेटाफ़्रेम से काम करना चाहते हैं। हमने 'df' से ओवरलैपिंग कॉलम 'बाएं' के साथ उदाहरण लिया है, इसलिए हम डेटा के ओवरलैपिंग को दूर करने के लिए इसे 'प्रत्यय' के साथ ठीक कर सकते हैं। यहां, उपयोग किए गए चर 'x', 'z', 'v', 'd' हैं। 'पी', 'ओ', 'एल', और 'वाई' '3', '6', '7' और '9' के रूप में निर्दिष्ट मानों के साथ। '.join' विधि को कॉल करता है, दाएं 'df' प्रत्यय के साथ बाईं ओर संरेखित सेट के साथ। ' कोड में प्रयुक्त 'प्रत्यय' इसलिए है क्योंकि डेटाफ़्रेम में, दो कॉलम हैं जिनका एक ही नाम है जो 'कुंजी' है और जो डेटा को ओवरलैप नहीं करेगा।
पंडों में शामिल होने की विधि का उपयोग करके आउटपुट दो 'df' में शामिल होने की विधि के साथ कोई अतिव्यापी डेटा प्रदर्शित नहीं करता है।
उदाहरण # 02: पांडा इंडेक्स रीसेट का उपयोग करके विधि में शामिल हों
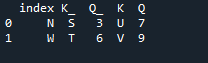
इस उदाहरण में, हम अलग से 'चालू' पैरामीटर के साथ कॉलम को 'कुंजी' के रूप में उपयोग करने के लिए विधि में शामिल होने के लिए निर्दिष्ट करेंगे जो दो डेटाफ्रेम में शामिल होने में मदद करता है। संयुक्त बात इस पैरामीटर के साथ की जाती है। साथ ही, दो 'df' में से किसी एक का इंडेक्स उनके जुड़ने के समान होना चाहिए। एक ही उद्देश्य के लिए उपयोग किए जाने वाले समान प्रकार के डेटा या डेटा प्रसंस्करण के लिए एक साथ हो सकते हैं। यह अभी भी सूचकांक का उपयोग करेगा, दाईं ओर से उपयोग कर रहा है। चर 'एस', 'टी', 'यू', 'वी', 'एन', 'डब्ल्यू', 'के', और 'क्यू' हैं। असाइन किए गए मान '3', '6', '7' और '9' हैं। 'रीसेट डॉट इंडेक्स' 'डीएफ' के सूचकांक को रीसेट करने के लिए पंडों की एक विधि है। रीसेट इंडेक्स आपकी डेटाफ़्रेम सूची के सभी पूर्णांकों को 0 से तब तक सेट करता है जब तक कि डेटाफ़्रेम डेटा लंबा नहीं हो जाता।
यहाँ पंडों के सूचकांक 'कुंजी' में शामिल होने की विधि के साथ प्रदर्शित होने वाला आउटपुट है।
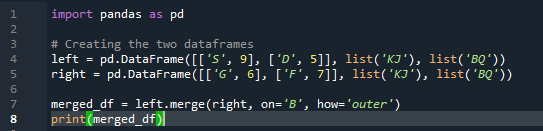
उदाहरण # 03: पांडस मर्ज विधि (स्तंभ 'बाएं और दाएं')
मर्ज विधि पंडों के जुड़ने की विधि के समान ऑपरेशन करती है। दोनों विधियाँ एक समान डेटाफ़्रेम पर डेटा के संयोजन के लिए हैं। मर्ज विधि अधिक बहुमुखी है जिसमें कुंजी निर्दिष्ट करने की आवश्यकता होती है। हम इसे आपके डेटाफ़्रेम के कार्य के आधार पर बाएँ और दाएँ कॉलम पर भी निर्दिष्ट कर सकते हैं। कोड में चर 's', 'd', 'g', 'f', 'k', 'j', 'b' और 'q' हैं। असाइन किए गए मान '9', '5', '6' और '7' हैं। पांडा मर्ज विधि फ़ंक्शन के पैरामीटर 'कैसे' का उपयोग करके बाहरी 'जॉइन' कार्यान्वयन 'डीएफ' दोनों पर किया जाता है।
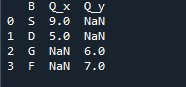
हम जो आउटपुट देखते हैं वह दो डेटाफ्रेम के मर्ज किए गए डेटा को दिखाता है। 'NaN' 'एक संख्या नहीं' का प्रतिनिधित्व करता है, जिसका अर्थ है कि जहां डेटा में कोई संख्या निर्दिष्ट नहीं है, वहां 'NaN' दिखाता है।
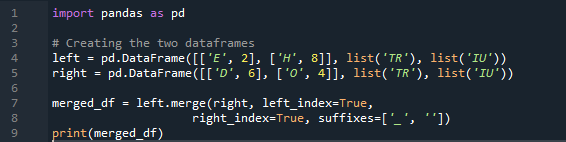
उदाहरण # 04: मर्ज विधि स्पष्ट रूप से
यहाँ, इस उदाहरण में, मर्ज विधि सूचकांक का विनाश है और डेटाफ़्रेम पर अनुक्रमणिका मान ग्रहण नहीं किया जाता है। हम इस पद्धति को किए जाने वाले आवश्यक कार्य के अनुसार करेंगे, जहां निर्दिष्ट स्पष्ट का पालन करना है। यह पैरामीटर के साथ लेफ्ट इंडेक्स या राइट इंडेक्स के आधार पर डेटा को मर्ज करेगा। इस डेटाफ़्रेम में चर 't', 'r', 'I', 'u', 'h', 'o', 'e' और 'e' हैं। असाइन किए गए मान '2', '4', '6' और '4' हैं। आवश्यकता के अनुसार कॉलम चयन के साथ पांडा मर्ज विधि का उपरोक्त उदाहरण दो डेटाफ्रेम में शामिल होने का सबसे प्रस्तुत करने योग्य और मूल्यवान तरीका है। डेटासेट में मर्ज कुंजी के अद्वितीय होने के बारे में कोड की पंक्ति के अंत में जाँच करना।
नीचे दिए गए आउटपुट में इंडेक्स को इंडेक्स के बिना नहीं दिखाया जाता है लेकिन फंक्शन दाएं और बाएं इंडेक्स के आधार पर किया जाता है।
निष्कर्ष
मर्ज () और जॉइन () विधियाँ दोनों विधियाँ बहुत सुविधाजनक और प्रभावी हैं। इन दोनों कार्यों का उपयोग एक ही डेटाफ़्रेम पर दो अलग-अलग डेटाफ़्रेम में शामिल होने के लिए किया जाता है, लेकिन मामले के आधार पर अलग-अलग उपयोग होते हैं। इस लेख में, हमने पंडों में शामिल होने और मर्ज करने की विधि के बीच महत्वपूर्ण अंतरों को सीखा है। उदाहरणों को करने और पांडा जुड़ने की विधि को समझने के बाद, हम इसे इस ज्ञान के साथ समाप्त करेंगे कि, यदि हम अधिक लचीली और डेटाबेस शैली में शामिल होना चाहते हैं, तो पांडा मर्ज विधि के साथ जाना बेहतर है। दूसरी ओर, यदि हम बड़े पैमाने पर इंडेक्स के साथ डेटाफ्रेम संयोजन करना चाहते हैं, तो हम पांडा जॉइन () विधि फ़ंक्शन के साथ जा सकते हैं।