'पांडा' में, हम 'पांडा' विधि की मदद से पाठ फ़ाइल को आसानी से पढ़ सकते हैं। 'पंडस' हमें पाठ फ़ाइल को पढ़ने का अवसर प्रदान करता है। 'पंडस' पाठ फ़ाइल को पढ़ने के लिए विभिन्न अंतर्निहित तरीके प्रदान करता है। हम यहां इस ट्यूटोरियल में सभी मापदंडों के साथ सभी विधियों पर चर्चा करेंगे और उन्हें विस्तार से समझाएंगे। साथ ही, हम यहां अपने कोड में 'पांडा' के तरीकों का उपयोग करके 'पांडा' में पाठ फ़ाइल पढ़ेंगे।
'पंडों' में पाठ फ़ाइल को पढ़ने के तरीके
'पांडा' में, हमारे पास तीन विधियाँ हैं जो पाठ फ़ाइल को पढ़ने में हमारी मदद करती हैं। हमने यहां कुछ उदाहरण भी दिए हैं जिनमें हम टेक्स्ट फाइल पढ़ते हैं। 'पंडों' द्वारा प्रदान की जाने वाली विधियों की चर्चा नीचे की गई है:
-
- pd.read_csv() विधि का उपयोग करके।
- pd.read_table() विधि का उपयोग करके।
- pd.read_fwf() विधि का उपयोग करके।
अब, हम इन सभी विधियों के सिंटैक्स की व्याख्या कर रहे हैं और इस ट्यूटोरियल में सभी विधियों के मापदंडों पर विस्तार से चर्चा कर रहे हैं।
Read_csv का सिंटैक्स ()
pd.read_csv ( 'filename.txt', सितम्बर = '' ', हैडर = कोई नहीं, नाम = [ 'Col_name1', 'Col_name2, 'Col_name2', ………….. ] )
इस मेथड में हम सबसे पहले उस टेक्स्ट फाइल का नाम जोड़ते हैं जिसका डेटा हम पढ़ना चाहते हैं और यह इस मेथड का पहला पैरामीटर है। फिर, हम 'सितंबर' डालते हैं, जो इस पद्धति में एक विभाजक है, और हम यहां स्थान को वर्ण के रूप में रखते हैं ताकि यह अंतरिक्ष को विभाजक के रूप में मान सके। इसके बाद, हमारे पास हेडर पैरामीटर है, और इस पैरामीटर के 'कोई नहीं' मान का उपयोग किया जाता है, इसलिए यह डिफ़ॉल्ट हेडर बनाएगा, और यदि हम इस पैरामीटर को नहीं जोड़ते हैं, तो यह टेक्स्ट फ़ाइल की पहली पंक्ति पर विचार करेगा। शीर्षलेख के रूप में। 'नाम' पैरामीटर में, हम उन कॉलम नामों को जोड़ सकते हैं जिन्हें हमें हेडर के रूप में जोड़ना है।
Read_table का सिंटैक्स ()
pd.read_table ( 'filename.txt' , सीमांकक = '' )
इस विधि में, हम टेक्स्ट फ़ाइल के फ़ाइल नाम को पहले पैरामीटर के रूप में रखते हैं। सीमांकक में, जब हम '''' रखते हैं, तो यह स्पेस कैरेक्टर को सेपरेटर के रूप में लेगा।
Read_fwf का सिंटैक्स ()
pd.read_fwf ( 'filename.txt' )
यह विधि केवल एक पैरामीटर लेती है, जो टेक्स्ट फ़ाइल का नाम है।
अब, हम इन विधियों का उपयोग 'पांडा' कोड में टेक्स्ट फ़ाइलों को पढ़ने और टर्मिनल पर टेक्स्ट फ़ाइल के डेटा को दिखाने के लिए करेंगे।
उदाहरण # 01
'स्पाइडर' ऐप यहां है जिसमें हमने ये सभी कोड किए हैं जो इस ट्यूटोरियल में प्रस्तुत किए गए हैं। टेक्स्ट फ़ाइल जिसका डेटा हम पढ़ना चाहते हैं, नीचे दिखाया गया है। हम इस पाठ फ़ाइल को 'पांडा' में पढ़ने के लिए 'read_csv ()' विधि का उपयोग करेंगे।
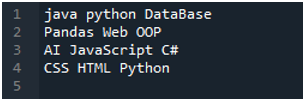
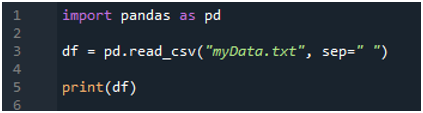
हम पहले 'पांडा' पुस्तकालय आयात करते हैं क्योंकि हम 'read_csv ()' विधि का उपयोग करना चाहते हैं, और यह 'पांडा' की विधि है। हम इस पद्धति का उपयोग केवल तभी करते हैं जब हमने 'पंडों' के पुस्तकालय को आयात किया हो। यहां, हम 'पंडों के रूप में पीडी' का उल्लेख करते हैं, इसलिए इस 'पीडी' को इसका उपयोग करने की विधि के नाम के साथ रखा गया है। इसके बाद हम यहाँ पर एक वेरिएबल “df” बनाते हैं, जो पढ़ने के बाद टेक्स्ट फ़ाइल के डेटा को स्टोर करने के लिए उपयोग किया जाता है। हम यहां 'pd.read_csv ()' विधि रखते हैं, जो टेक्स्ट फ़ाइल को पढ़ने और टेक्स्ट फ़ाइल डेटा को डेटाफ़्रेम में परिवर्तित करने और इसे 'df' चर में संग्रहीत करने में मदद करता है।
हमने फ़ाइल नाम पास किया है, जो कि 'myData.txt' है, और फिर हम 'sep' का उपयोग करते हैं और इस 'sep' को रिक्त वर्ण असाइन करते हैं। तो, यह रिक्त वर्ण टेक्स्ट फ़ाइल में विभाजक के रूप में कार्य करता है। फिर, हमने नीचे 'प्रिंट ()' का उपयोग किया, जिसका उपयोग टेक्स्ट फ़ाइल के डेटा को प्रिंट करने के लिए किया जाता है। यह टेक्स्ट फ़ाइल के डेटा को DataFrame फॉर्म में प्रदर्शित करेगा।
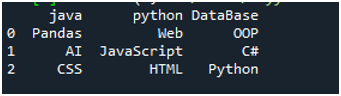
इस कोड के निष्पादन के लिए, हमें 'Shift+Enter' को दबाना होगा और आउटपुट 'स्पाइडर के' टर्मिनल पर प्रस्तुत किया जाएगा। उपरोक्त कोड का परिणाम दिए गए स्क्रीनशॉट में प्रदर्शित होता है, और आप देख सकते हैं कि टेक्स्ट फ़ाइल का डेटा डेटाफ़्रेम के रूप में प्रदर्शित होता है, और हमारी टेक्स्ट फ़ाइल की पहली पंक्ति उस डेटाफ़्रेम के कॉलम नामों के रूप में यहाँ प्रस्तुत की जाती है। यह उस डेटा को भी अलग करता है जहां टेक्स्ट फ़ाइल में स्पेस कैरेक्टर मौजूद है।
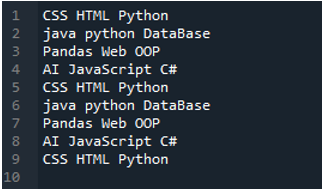
उदाहरण # 02
इस उदाहरण में हम जो टेक्स्ट फ़ाइल पढ़ेंगे, वह यहां दिखाई गई है, और हम फिर से 'read_csv ()' विधि का उपयोग करेंगे, लेकिन विभिन्न मापदंडों के साथ।
'पांडा' विधि 'pd.read_csv ()' का उपयोग किया जाता है, और हम यहां तीन पैरामीटर पास करते हैं। सबसे पहले, हम फ़ाइल नाम रखते हैं, जो 'Record.txt' है। दूसरा पैरामीटर 'sep' पैरामीटर है और इसे रिक्त वर्ण निर्दिष्ट करता है, और फिर हमारे पास तीसरा पैरामीटर होता है जिसमें हम 'हेडर' सेट करते हैं और इसे 'कोई नहीं' में समायोजित करते हैं, इसलिए यह डेटाफ़्रेम का डिफ़ॉल्ट हेडर बनाएगा जब हम इस कोड को निष्पादित करते हैं। हमने यह सब 'My_Record' वेरिएबल में सेव किया है और प्रिंटिंग के लिए 'प्रिंट ()' फंक्शन में 'My_Record' भी जोड़ा है।

सभी डेटा डेटाफ़्रेम में सहेजा जाता है, और यह उस डेटा को अलग करता है जहां टेक्स्ट फ़ाइल डेटा में स्पेस कैरेक्टर मौजूद है। साथ ही, इसने यहां डेटाफ़्रेम का डिफ़ॉल्ट हेडर बनाया क्योंकि हमने 'हेडर' पैरामीटर को 'कोई नहीं' में समायोजित किया था।
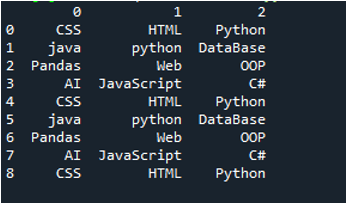
उदाहरण # 03
इस उदाहरण की टेक्स्ट फ़ाइल प्रदर्शित होती है, और हम एक बार फिर संशोधित मापदंडों के साथ 'read_csv ()' विधि का उपयोग करेंगे।
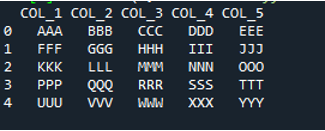
इस कोड में, 'पांडा' विधि 'pd.read_csv ()' के लिए यहां चार पैरामीटर पास किए गए हैं। टेक्स्ट फ़ाइल का नाम पहला पैरामीटर है। दूसरे पैरामीटर में 'sep' पैरामीटर को रिक्त वर्ण दिया गया है। तीसरे तर्क में 'हेडर' पैरामीटर 'कोई नहीं' पर सेट है, और चौथे पैरामीटर के रूप में, हमने 'नाम' सेट किया है जो टेक्स्ट फ़ाइल को पढ़ने के बाद डेटाफ्रेम के कॉलम नामों के रूप में दिखाई देगा, और ये कॉलम नाम हैं 'COL_1, COL_2, COL_3, COL_4, और COL_5'। यह सारी जानकारी 'My_Record' चर में सहेजी गई है, और 'My_Record' को 'प्रिंट ()' विधि में भी जोड़ा गया है, इसलिए यह टर्मिनल पर प्रिंट होगा।

टेक्स्ट फ़ाइल की सभी जानकारी यहाँ डेटाफ़्रेम के रूप में प्रस्तुत की जाती है, और यह उस डेटा को भी अलग करती है जहाँ टेक्स्ट फ़ाइल में रिक्त स्थान जोड़े जाते हैं। यह तदनुसार कॉलम नाम भी जोड़ता है, जिसे हमने ऊपर कोड में जोड़ा है।
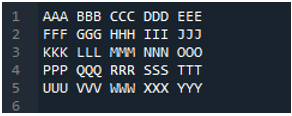
उदाहरण # 04
यह वह टेक्स्ट फ़ाइल है जिसे हम इस उदाहरण में एक अन्य विधि, 'pd.read_table ()' विधि का उपयोग करके पढ़ेंगे।
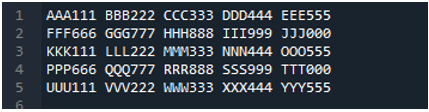
टेक्स्ट फ़ाइल को पढ़ने के लिए 'pd.read_table ()' विधि यहां जोड़ी गई है, और हम 'ABC.txt' जोड़ते हैं, जो टेक्स्ट फ़ाइल का नाम है। यह विधि टेक्स्ट फ़ाइल को पढ़ने में मदद करती है, और साथ ही, हमने 'सीमांकक' पैरामीटर को स्पेस कैरेक्टर में समायोजित किया है, इसलिए यह विभाजक की तरह भी काम करेगा जिसे हमने ऊपर बताया है। फिर सभी टेक्स्ट का फ़ाइल डेटा 'My_Data' वेरिएबल में सहेजा जाता है और यहां प्रिंट भी किया जाता है।

हमारी टेक्स्ट फ़ाइल की प्रारंभिक पंक्ति यहाँ DataFrame के कॉलम नामों के रूप में दिखाई गई है, और टेक्स्ट फ़ाइल का डेटा DataFrame के रूप में प्रिंट किया गया है। इसके अतिरिक्त, यह टेक्स्ट फ़ाइल के डेटा को अलग करता है जहाँ इसमें स्पेस कैरेक्टर मौजूद होता है।
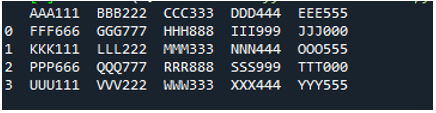
उदाहरण # 05
अब, टेक्स्ट फ़ाइल में डेटा होता है, जो नीचे प्रदर्शित होता है। हम इस बार 'read_fwf ()' लागू करेंगे और दिखाएंगे कि यह टेक्स्ट फ़ाइल को पढ़ने के बाद डेटा कैसे प्रस्तुत करता है।
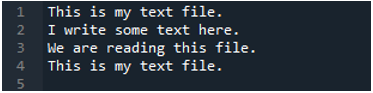
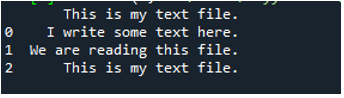
जैसा कि हम जानते हैं कि यह 'read_fwf ()' विधि केवल एक पैरामीटर लेती है, जो कि फ़ाइल नाम है जिसे हम पढ़ना चाहते हैं। हम यहां 'textfile.txt' जोड़ते हैं, जो कि हमारी टेक्स्ट फ़ाइल का नाम है और इस पांडा विधि को 'File_Data' वेरिएबल में असाइन करते हैं, जो इस टेक्स्ट फ़ाइल के डेटा को संग्रहीत करेगा। फिर हम 'प्रिंट (फाइल_डेटा)' डालते हैं, इसलिए यह इस डेटा को प्रिंट भी करता है।

यहां, टेक्स्ट फ़ाइल का सभी डेटा दिखाया गया है। इसने डेटा को अलग नहीं किया जहां अंतरिक्ष वर्ण मौजूद हैं क्योंकि इस फ़ंक्शन में 'सितंबर' या 'सीमांकक' जैसा कोई पैरामीटर नहीं है।
निष्कर्ष
यह ट्यूटोरियल बताता है कि 'पांडा' में टेक्स्ट फ़ाइल को कैसे पढ़ा जाए और 'पांडा' में टेक्स्ट फ़ाइल को पढ़ने के लिए किन विधियों का उपयोग किया जाता है। हमने उन सभी विधियों पर चर्चा की है जो हमें 'पांडा' में पाठ फ़ाइल को पढ़ने में मदद करती हैं। हमने इस ट्यूटोरियल में 'पंडों' में अपनी टेक्स्ट फाइलों को पढ़ने के लिए 'पंडों' के तीन अलग-अलग तरीकों का पता लगाया है। हमने यहां सभी विधियों के सिंटैक्स के साथ-साथ सभी विधियों के मापदंडों को भी विस्तार से समझाया है और इस ट्यूटोरियल में सभी संभावित मापदंडों के साथ विभिन्न विधियों को लागू करके कई टेक्स्ट फाइलें पढ़ी हैं।