डेटाबेस प्रशासक के रूप में, हमें डेटाबेस प्रदर्शन को बढ़ाने के उपकरणों और तरीकों के प्रति जुनूनी होने की आवश्यकता है।
PostgreSQL में, हमारे पास EXPLAIN ANALYZE कमांड तक पहुंच है जो हमें किसी दिए गए डेटाबेस क्वेरी के निष्पादन योजना और प्रदर्शन का विश्लेषण करने की अनुमति देता है। कमांड इस बारे में विस्तृत जानकारी देता है कि डेटाबेस इंजन क्वेरी को कैसे संसाधित करता है। इसमें निष्पादित कार्यों का क्रम, अनुमानित क्वेरी लागत, निष्पादन समय और बहुत कुछ शामिल है।
फिर हम इस जानकारी का उपयोग डेटाबेस प्रश्नों की पहचान करने के साथ-साथ संभावित प्रदर्शन बाधाओं को पहचानने और ठीक करने के लिए कर सकते हैं।
यह ट्यूटोरियल चर्चा करता है कि क्वेरी प्रदर्शन को देखने और अनुकूलित करने के लिए PostgreSQL में EXPLAIN ANALYZE कमांड का उपयोग कैसे करें।
PostgreSQL व्याख्या विश्लेषण
आदेश बहुत सीधा है. सबसे पहले, हमें उस क्वेरी की शुरुआत में EXPLAIN ANALYZE कमांड को जोड़ना होगा जिसका हम विश्लेषण करना चाहते हैं।
कमांड सिंटैक्स इस प्रकार है:
व्याख्या करें विश्लेषण करेंएक बार जब आप कमांड निष्पादित करते हैं, तो PostgreSQL प्रदान की गई क्वेरी के बारे में एक विस्तृत आउटपुट देता है।
व्याख्या विश्लेषण क्वेरी आउटपुट को समझना
जैसा कि उल्लेख किया गया है, एक बार जब हम EXPLAIN ANALYZE कमांड चलाते हैं, तो PostgreSQL क्वेरी योजना और निष्पादन आंकड़ों की एक विस्तृत रिपोर्ट तैयार करता है।
आउटपुट में कॉलम का एक सेट शामिल होता है जिसमें उपयोगी जानकारी होती है। परिणामी कॉलम उनके संबंधित अर्थ के साथ दिखाए गए हैं:
प्रश्न योजना - यह कॉलम निर्दिष्ट क्वेरी की निष्पादन योजना प्रदर्शित करता है। निष्पादन योजना संचालन के अनुक्रम को संदर्भित करती है जो डेटाबेस इंजन क्वेरी को सफलतापूर्वक पूरा करने के लिए करता है।
योजना - दूसरा कॉलम प्लान कॉलम है। इसमें निष्पादन योजना में प्रत्येक ऑपरेशन या चरण का एक पाठ्य प्रतिनिधित्व शामिल है। पुनः, प्रत्येक ऑपरेशन को संचालन के पदानुक्रम को इंगित करने के लिए इंडेंट किया गया है।
कुल लागत - कुल लागत कॉलम क्वेरी की अनुमानित कुल लागत का प्रतिनिधित्व करता है। लागत एक सापेक्ष माप को संदर्भित करती है जिसका उपयोग डेटाबेस क्वेरी प्लानर इष्टतम निष्पादन योजना निर्धारित करने के लिए करता है।
वास्तविक पंक्तियाँ - यह कॉलम क्वेरी निष्पादन में प्रत्येक चरण पर संसाधित की जाने वाली पंक्तियों की सटीक संख्या दिखाता है।
असली समय - यह कॉलम प्रत्येक ऑपरेशन द्वारा लिया गया वास्तविक समय दिखाता है जिसमें ऑपरेशन का निष्पादन समय और संसाधनों पर खर्च किया गया समय दोनों शामिल हैं।
योजना बनाने का समय - यह कॉलम उस समय को दर्शाता है जो क्वेरी प्लानर एक निष्पादन योजना तैयार करने में लेता है। इसमें क्वेरी अनुकूलन और योजना निर्माण का कुल समय शामिल है।
निष्पादन समय - यह कॉलम क्वेरी निष्पादित करने का कुल समय दिखाता है। इसमें योजना पर खर्च किया गया समय और क्वेरी निष्पादन समय भी शामिल है।
PostgreSQL व्याख्या विश्लेषण उदाहरण
आइए व्याख्या विश्लेषण कथन का उपयोग करने के कुछ बुनियादी उदाहरण देखें।
उदाहरण 1: कथन चुनें
आइए PostgreSQL में एक साधारण चयन कथन के निष्पादन को दिखाने के लिए EXPLAIN ANALYZE कथन का उपयोग करें।
एक बार जब हम पिछला स्टेटमेंट चलाते हैं, तो हमें निम्नानुसार आउटपुट प्राप्त होना चाहिए:
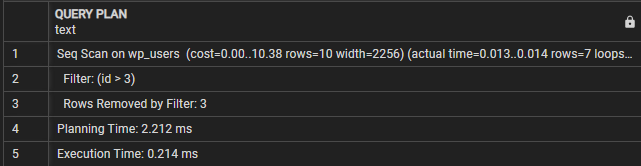
प्रश्न योजना-------------------------------------------------- -----------------
wp_users पर Seq स्कैन (लागत=0.00..10.38 पंक्तियाँ=10 चौड़ाई=2256) (वास्तविक समय=0.009..0.010 पंक्तियाँ=7 लूप=1)
फ़िल्टर: (आईडी > 3)
फ़िल्टर द्वारा हटाई गई पंक्तियाँ: 3
योजना समय: 0.995 मि.से
निष्पादन समय: 0.021 मि.से
(5 पंक्तियाँ)
इस मामले में, हम देख सकते हैं कि क्वेरी योजना अनुभाग इंगित करता है कि क्वेरी wp_users तालिका पर अनुक्रमिक स्कैन करती है। फ़िल्टर लाइन उस स्थिति को दर्शाती है जिसका उपयोग परिणामी पंक्तियों को फ़िल्टर करने के लिए किया जाता है।
फिर हम 'फ़िल्टर द्वारा हटाई गई पंक्तियाँ' देखते हैं जो फ़िल्टर स्थिति द्वारा हटाई गई पंक्तियों की संख्या को दर्शाता है।
अंत में, निष्पादन समय क्वेरी का कुल निष्पादन समय दिखाता है। इस स्थिति में, क्वेरी में 0.021ms लगते हैं।
उदाहरण 2: किसी जोड़ का विश्लेषण करना
आइए एक अधिक जटिल क्वेरी लें जिसमें SQL जुड़ाव शामिल है। इसके लिए हम पगिला नमूना डेटाबेस का उपयोग करते हैं। आप प्रदर्शन उद्देश्य के लिए नमूना डेटाबेस को अपनी मशीन पर डाउनलोड और इंस्टॉल कर सकते हैं।
हम एक साधारण जॉइन चला सकते हैं जैसा कि निम्नलिखित में दिखाया गया है:
व्याख्या करें, विश्लेषण करें, चयन करें एफ.शीर्षक, सी.नामफिल्म से एफ
f.film_id = fc.film_id पर फ़िल्म_श्रेणी fc से जुड़ें
fc.category_id = c.category_id पर श्रेणी c में शामिल हों;
एक बार जब हम दी गई क्वेरी चलाते हैं, तो हमें आउटपुट इस प्रकार देखना चाहिए:
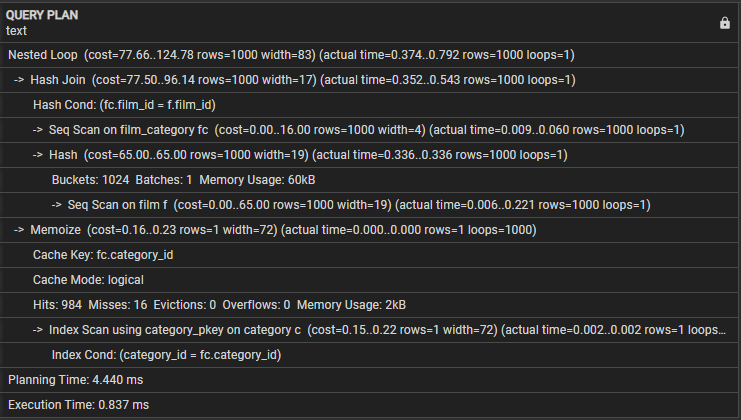
आइए निम्नलिखित क्वेरी योजना का अन्वेषण करें:
- नेस्टेड लूप - यह इंगित करता है कि जॉइन नेस्टेड लूप जॉइन रणनीति का उपयोग करता है।
- हैश जॉइन - यह ऑपरेशन हैश जॉइन एल्गोरिदम का उपयोग करके फिल्म_श्रेणी और फिल्म तालिकाओं को जोड़ता है। इस ऑपरेशन की लागत 77.50 और अनुमानित 1000 पंक्तियाँ हैं। हालाँकि, इस ऑपरेशन में लगने वाला वास्तविक समय 0.254 से 0.439 मिलीसेकंड है, और यह 1000 पंक्तियों को पुनः प्राप्त करता है।
- हैश कॉन्ड - यह इंगित करता है कि जॉइन कंडीशन फिल्म तालिकाओं में फिल्म_आईडी कॉलम और फिल्म_श्रेणी कॉलम से मेल खाने के लिए हैश जॉइन का उपयोग करती है।
- फिल्म_श्रेणी पर सेक स्कैन - यह ऑपरेशन 16.00 की लागत और अनुमानित 1000 पंक्तियों के साथ फिल्म_श्रेणी तालिका पर अनुक्रमिक स्कैन करता है। इस ऑपरेशन में लगने वाला वास्तविक समय 0.008 से 0.056 मिलीसेकंड है, और यह 1000 पंक्तियों को पुनः प्राप्त करता है।
- फिल्म पर सेक स्कैन - क्वेरी इस ऑपरेशन में परिणामी अनुमानित और वास्तविक लागत और पंक्तियों के साथ फिल्म तालिका पर अनुक्रमिक स्कैन करती है।
- मेमोइज़ - यह ऑपरेशन बाद के उपयोग के लिए फिल्म_श्रेणी और फिल्म तालिकाओं के बीच जुड़ने के परिणामों को कैश करता है।
- कैश कुंजी - यह इंगित करता है कि मेमोरीकरण के लिए उपयोग की जाने वाली कैश कुंजी फिल्म_श्रेणी से श्रेणी_आईडी कॉलम पर आधारित है।
- कैश मोड - यह इंगित करता है कि क्वेरी तार्किक कैश मोड का उपयोग करती है।
- हिट, मिस, एविक्शन, ओवरफ्लो - तीन पंक्तियाँ निष्पादन के दौरान कैश, हिट की संख्या, मिस, एविक्शन और ओवरफ्लो के बारे में आंकड़े प्रदान करती हैं। इस ब्लॉक में क्वेरी निष्पादन के दौरान मेमोरी उपयोग भी शामिल है।
- Category_pkey का उपयोग करके इंडेक्स स्कैन - यह उस ऑपरेशन को दिखाता है जो प्राथमिक कुंजी इंडेक्स का उपयोग करके श्रेणी तालिका पर इंडेक्स स्कैन करता है।
- इंडेक्स कोंड - इससे पता चलता है कि इंडेक्स स्कैन उस स्थिति पर आधारित है जो श्रेणी तालिका में कैटेगरी_आईडी कॉलम से मेल खाता है।
- नियोजन समय - यह पंक्ति क्वेरी नियोजन में लगने वाले समय को दर्शाती है जो कि 3.005 मिलीसेकंड है।
- निष्पादन समय - अंत में, यह पंक्ति क्वेरी का कुल निष्पादन समय दिखाती है जो 0.745 मिलीसेकंड है।
ये लो! PostgreSQL में एक साधारण जुड़ाव के निष्पादन के बारे में विस्तृत जानकारी।
निष्कर्ष
आपने PostgreSQL में EXPLAIN ANALYZE कथन की शक्ति और उपयोग की खोज की। व्याख्या विश्लेषण कथन क्वेरी विश्लेषण और अनुकूलन के लिए एक शक्तिशाली उपकरण है। कुशल और कम संसाधन-गहन क्वेरी बनाने के लिए इस टूल का उपयोग करें।