त्वरित रूपरेखा
यह पोस्ट निम्नलिखित प्रदर्शित करेगी:
- लैंगचेन में एक एजेंट और उसके टूल्स दोनों में मेमोरी कैसे जोड़ें
- चरण 1: फ्रेमवर्क स्थापित करना
- चरण 2: वातावरण स्थापित करना
- चरण 3: पुस्तकालय आयात करना
- चरण 4: ReadOnlyMemory जोड़ना
- चरण 5: उपकरण स्थापित करना
- चरण 6: एजेंट का निर्माण
- विधि 1: ReadOnlyMemory का उपयोग करना
- विधि 2: एजेंट और टूल दोनों के लिए समान मेमोरी का उपयोग करना
- निष्कर्ष
लैंगचेन में एजेंट और उसके टूल्स दोनों में मेमोरी कैसे जोड़ें?
एजेंटों और टूल में मेमोरी जोड़ने से वे मॉडल के चैट इतिहास का उपयोग करने की क्षमता के साथ बेहतर काम करने में सक्षम हो जाते हैं। मेमोरी के साथ, एजेंट कुशलतापूर्वक निर्णय ले सकता है कि कौन सा टूल तैनात करना है और कब। इसका उपयोग करना पसंद किया जाता है ' केवल पढ़ने के लिये मेमोरी 'एजेंटों और टूल दोनों के लिए, इसलिए वे इसे संशोधित नहीं कर पाएंगे।' लैंगचेन में एजेंटों और टूल दोनों में मेमोरी जोड़ने की प्रक्रिया सीखने के लिए, सूचीबद्ध चरणों से गुजरें:
चरण 1: फ्रेमवर्क स्थापित करना
सबसे पहले, इंस्टॉल करें लैंगचैन-प्रयोगात्मक एजेंट के लिए भाषा मॉडल और उपकरण बनाने के लिए इसकी निर्भरता प्राप्त करने के लिए मॉड्यूल। लैंगचेन प्रायोगिक वह मॉड्यूल है जो उन मॉडलों के निर्माण के लिए निर्भरता प्राप्त करता है जिनका उपयोग ज्यादातर प्रयोगों और परीक्षणों के लिए किया जाता है:
पाइप लैंगचैन स्थापित करें - प्रयोगात्मक
लाओ गूगल-खोज-परिणाम इंटरनेट से सर्वाधिक प्रासंगिक उत्तर प्राप्त करने के लिए OpenAI निर्भरता वाले मॉड्यूल:
पिप इंस्टॉल ओपनाई गूगल - खोज - परिणाम
चरण 2: वातावरण स्थापित करना
इंटरनेट से उत्तर प्राप्त करने वाले मॉडल का निर्माण करने के लिए, इसका उपयोग करके वातावरण स्थापित करना आवश्यक है ओपनएआई और सर्पएपीआई चांबियाँ:
आयात आप
आयात पास ले लो
आप। लगभग [ 'OPENAI_API_KEY' ] = पास ले लो। पास ले लो ( 'ओपनएआई एपीआई कुंजी:' )
आप। लगभग [ 'SERPAPI_API_KEY' ] = पास ले लो। पास ले लो ( 'सेरपापी एपीआई कुंजी:' )
चरण 3: पुस्तकालय आयात करना
परिवेश स्थापित करने के बाद, एजेंट के लिए उपकरण और उनके साथ एकीकृत करने के लिए अतिरिक्त मेमोरी बनाने के लिए पुस्तकालयों को आयात करें। निम्नलिखित कोड आवश्यक लाइब्रेरी प्राप्त करने के लिए एजेंटों, मेमोरी, एलएलएम, चेन, प्रॉम्प्ट और उपयोगिताओं का उपयोग करता है:
लैंगचैन से. एजेंट आयात ज़ीरोशॉटएजेंट , औजार , एजेंटनिष्पादकलैंगचैन से. याद आयात कन्वर्सेशनबफरमेमोरी , ReadOnlySharedMemory
लैंगचैन से. एलएमएस आयात ओपनएआई
#लाइब्रेरी प्राप्त करें के लिए लैंगचेन का उपयोग करके श्रृंखला का निर्माण
लैंगचैन से. चेन आयात एलएलएमचेन
लैंगचैन से. संकेतों आयात संकेत टेम्पलेट
#लाइब्रेरी प्राप्त करें के लिए इंटरनेट से जानकारी प्राप्त करना
लैंगचैन से. उपयोगिताओं आयात सर्पएपिरैपर
चरण 4: ReadOnlyMemory जोड़ना
जैसे ही उपयोगकर्ता इनपुट प्रदान करता है, एजेंट कार्य शुरू करने के लिए टेम्पलेट कॉन्फ़िगर करें। उसके बाद, जोड़ें 'कन्वर्सेशनबफ़रमेमोरी()' मॉडल के चैट इतिहास को संग्रहीत करने और आरंभ करने के लिए 'केवल पढ़ने के लिये मेमोरी' एजेंटों और उसके उपकरणों के लिए:
खाका = '' 'यह एक इंसान और एक बॉट के बीच की बातचीत है:{चैट का इतिहास}
#सटीक और आसान सारांश निकालने के लिए संरचना निर्धारित करें
{इनपुट} के लिए चैट को सारांशित करें:
' ''
तत्पर = संकेत टेम्पलेट ( इनपुट_चर = [ 'इनपुट' , 'चैट का इतिहास' ] , खाका = खाका )
याद = कन्वर्सेशनबफरमेमोरी ( मेमोरी_कुंजी = 'चैट का इतिहास' )
केवल पढ़ने के लिये मेमोरी = ReadOnlySharedMemory ( याद = याद )
सभी घटकों को एकीकृत करने के लिए #सारांश श्रृंखला के लिए बातचीत का सारांश प्राप्त करना
सारांश_श्रृंखला = एलएलएमचेन (
एलएलएम = ओपनएआई ( ) ,
तत्पर = तत्पर ,
वाचाल = सत्य ,
याद = केवल पढ़ने के लिये मेमोरी ,
)
चरण 5: उपकरण स्थापित करना
अब, चैट के सारांश के साथ इंटरनेट से उत्तर प्राप्त करने के लिए खोज और सारांश जैसे टूल सेट करें:
खोज = सर्पएपिरैपर ( )औजार = [
औजार (
नाम = 'खोज' ,
समारोह = खोजना। दौड़ना ,
विवरण = 'हाल की घटनाओं के बारे में लक्षित प्रश्नों के उचित उत्तर' ,
) ,
औजार (
नाम = 'सारांश' ,
समारोह = सारांश_श्रृंखला. दौड़ना ,
विवरण = 'चैट को सारांशित करने में सहायक और इस टूल का इनपुट एक स्ट्रिंग होना चाहिए, जो दर्शाता है कि इस सारांश को कौन पढ़ेगा' ,
) ,
]
चरण 6: एजेंट का निर्माण
जैसे ही उपकरण आवश्यक कार्य करने और इंटरनेट से उत्तर निकालने के लिए तैयार हों, एजेंट को कॉन्फ़िगर करें। “ उपसर्ग 'वेरिएबल को एजेंटों द्वारा टूल को कोई कार्य सौंपने से पहले निष्पादित किया जाता है और' प्रत्यय टूल द्वारा उत्तर निकालने के बाद 'निष्पादित किया जाता है:
उपसर्ग = '' 'निम्नलिखित टूल का उपयोग करके, यथासंभव सर्वोत्तम तरीके से निम्नलिखित प्रश्नों का उत्तर देते हुए, किसी इंसान के साथ बातचीत करें:' ''प्रत्यय = '' 'शुरू करना!'
#संरचना के लिए एजेंट को मेमोरी का उपयोग करते समय टूल का उपयोग शुरू करना होगा
{ चैट का इतिहास }
सवाल : { इनपुट }
{ एजेंट_स्क्रैचपैड } '' '
संकेत = ZeroShotAgent.create_prompt(
#प्रश्न के संदर्भ को समझने के लिए शीघ्र टेम्पलेट कॉन्फ़िगर करें
औजार,
उपसर्ग=उपसर्ग,
प्रत्यय = प्रत्यय,
इनपुट_वेरिएबल्स=[' इनपुट ', ' चैट का इतिहास ', ' एजेंट_स्क्रैचपैड '],
)
विधि 1: ReadOnlyMemory का उपयोग करना
एक बार जब एजेंट टूल को निष्पादित करने के लिए सेट हो जाता है, तो ReadOnlyMemory वाला मॉडल होता है पसंदीदा उत्तर प्राप्त करने के लिए श्रृंखला बनाने और निष्पादित करने का तरीका और प्रक्रिया इस प्रकार है:
चरण 1: श्रृंखला का निर्माण
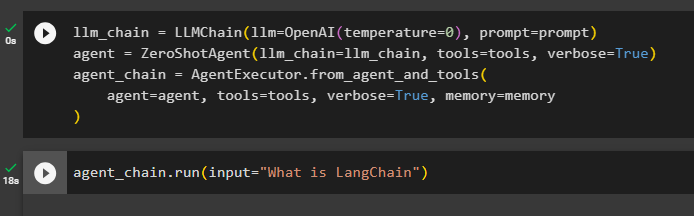
इस विधि में पहला कदम श्रृंखला और निष्पादक का निर्माण करना है 'ज़ीरोशॉटएजेंट()' अपने तर्कों के साथ. 'एलएलएमचेन()' एलएलएम और प्रॉम्प्ट तर्कों का उपयोग करके भाषा मॉडल में सभी चैट के बीच कनेक्शन बनाने के लिए उपयोग किया जाता है। एजेंट अपने तर्क के रूप में llm_चेन, टूल्स और वर्बोज़ का उपयोग करता है और मेमोरी के साथ एजेंटों और उसके टूल्स दोनों को निष्पादित करने के लिए एजेंट_चेन बनाता है:
एलएलएम_चेन = एलएलएमचेन ( एलएलएम = ओपनएआई ( तापमान = 0 ) , तत्पर = तत्पर )प्रतिनिधि = ज़ीरोशॉटएजेंट ( एलएलएम_चेन = एलएलएम_चेन , औजार = औजार , वाचाल = सत्य )
एजेंट_चेन = एजेंटनिष्पादक. from_agent_and_tools (
प्रतिनिधि = प्रतिनिधि , औजार = औजार , वाचाल = सत्य , याद = याद
)
चरण 2: श्रृंखला का परीक्षण
बुलाएं एजेंट_चेन इंटरनेट से प्रश्न पूछने के लिए रन() विधि का उपयोग करना:
एजेंट_चेन. दौड़ना ( इनपुट = 'लैंगचेन क्या है' )एजेंट ने खोज टूल का उपयोग करके इंटरनेट से उत्तर निकाला है:
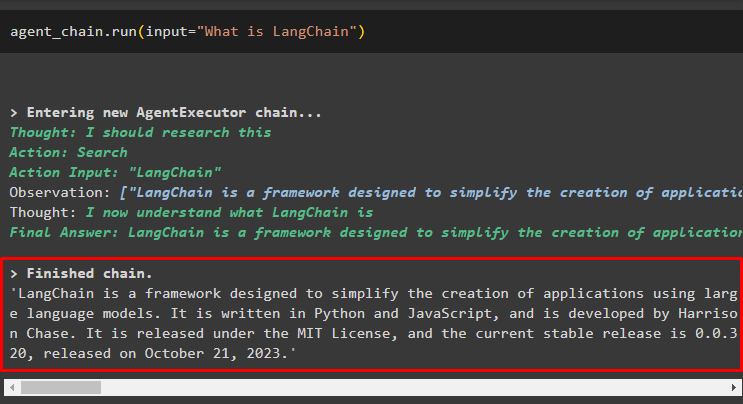
उपयोगकर्ता एजेंट से जुड़ी मेमोरी का परीक्षण करने के लिए अस्पष्ट अनुवर्ती प्रश्न पूछ सकता है:
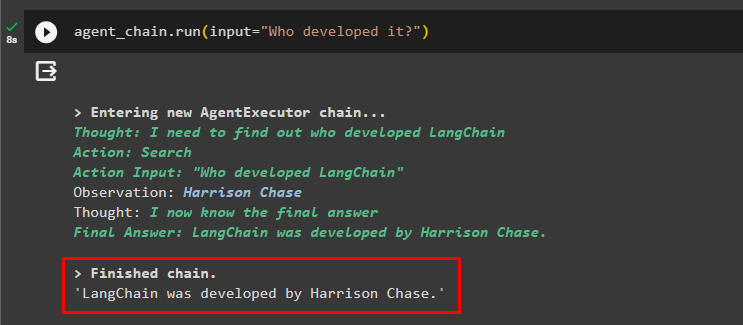
एजेंट_चेन. दौड़ना ( इनपुट = 'इसे किसने विकसित किया?' )एजेंट ने प्रश्नों के संदर्भ को समझने के लिए पिछली चैट का उपयोग किया है और उत्तर प्राप्त किए हैं जैसा कि निम्नलिखित स्क्रीनशॉट में दिखाया गया है:
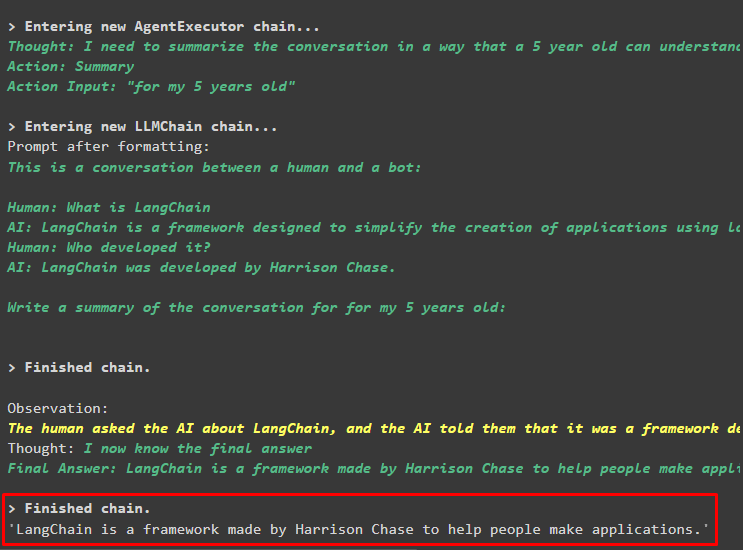
एजेंट की मेमोरी का उपयोग करके पहले निकाले गए सभी उत्तरों का सारांश निकालने के लिए एजेंट टूल (सारांश_चेन) का उपयोग करता है:
एजेंट_चेन. दौड़ना (इनपुट = 'धन्यवाद! मेरे 5 साल के बच्चे के लिए बातचीत को संक्षेप में प्रस्तुत करें'
)

उत्पादन
पहले पूछे गए प्रश्नों का सारांश निम्नलिखित स्क्रीनशॉट में 5-वर्षीय बच्चे के लिए प्रदर्शित किया गया है:
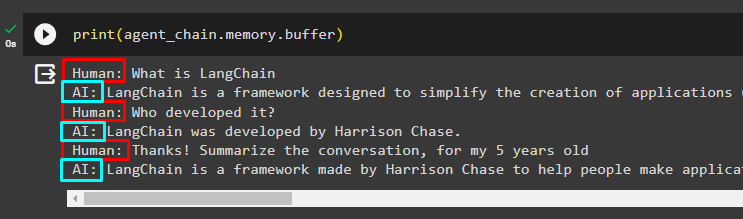
चरण 3: मेमोरी का परीक्षण
निम्नलिखित कोड का उपयोग करके इसमें संग्रहीत चैट को निकालने के लिए बफर मेमोरी को प्रिंट करें:
छपाई ( एजेंट_चेन. याद . बफर )बिना किसी संशोधन के चैट को उसके सही क्रम में निम्नलिखित स्निपेट में प्रदर्शित किया गया है:
विधि 2: एजेंट और टूल दोनों के लिए समान मेमोरी का उपयोग करना
दूसरी विधि जो प्लेटफ़ॉर्म द्वारा अनुशंसित नहीं है वह एजेंटों और टूल दोनों के लिए बफर मेमोरी का उपयोग करना है। उपकरण मेमोरी में संग्रहीत चैट को बदल सकते हैं जो बड़ी बातचीत में गलत आउटपुट दे सकते हैं:
चरण 1: श्रृंखला का निर्माण
एक छोटे से बदलाव के साथ एजेंटों के लिए टूल और चेन बनाने के लिए टेम्पलेट से पूरे कोड का उपयोग करना क्योंकि इस बार ReadOnlyMemory नहीं जोड़ा गया है:
खाका = '' 'यह एक इंसान और एक बॉट के बीच की बातचीत है:{चैट का इतिहास}
{इनपुट} के लिए बातचीत का सारांश लिखें:
' ''
#चैट की संरचना बनाएं इंटरफेस श्रृंखला के साथ मेमोरी जोड़कर प्रॉम्प्ट टेम्पलेट का उपयोग करना
तत्पर = संकेत टेम्पलेट ( इनपुट_चर = [ 'इनपुट' , 'चैट का इतिहास' ] , खाका = खाका )
याद = कन्वर्सेशनबफरमेमोरी ( मेमोरी_कुंजी = 'चैट का इतिहास' )
सारांश_श्रृंखला = एलएलएमचेन (
एलएलएम = ओपनएआई ( ) ,
तत्पर = तत्पर ,
वाचाल = सत्य ,
याद = याद ,
)
#उपकरण बनाएं ( खोजें और सारांश ) के लिए एजेंटों को कॉन्फ़िगर करना
खोज = सर्पएपिरैपर ( )
औजार = [
औजार (
नाम = 'खोज' ,
समारोह = खोजना। दौड़ना ,
विवरण = 'हाल की घटनाओं के बारे में लक्षित प्रश्नों के उचित उत्तर' ,
) ,
औजार (
नाम = 'सारांश' ,
समारोह = सारांश_श्रृंखला. दौड़ना ,
विवरण = 'चैट का सारांश प्राप्त करने में मददगार और इस टूल में स्ट्रिंग इनपुट की आवश्यकता है जो यह दर्शाता है कि इस सारांश को कौन पढ़ेगा' ,
) ,
]
#चरणों की व्याख्या करें के लिए एजेंट जानकारी निकालने के लिए उपकरणों का उपयोग करता है के लिए वार्ता
उपसर्ग = '' 'निम्नलिखित टूल का उपयोग करके सर्वोत्तम संभव तरीके से प्रश्नों का उत्तर देते हुए, किसी इंसान के साथ बातचीत करें:' ''
प्रत्यय = '' 'शुरू करना!'
#संरचना के लिए एजेंट को मेमोरी का उपयोग करते समय टूल का उपयोग शुरू करना होगा
{ चैट का इतिहास }
सवाल : { इनपुट }
{ एजेंट_स्क्रैचपैड } '' '
प्रॉम्प्ट = ZeroShotAgent.create_prompt(
#प्रश्न के संदर्भ को समझने के लिए शीघ्र टेम्पलेट कॉन्फ़िगर करें
औजार,
उपसर्ग=उपसर्ग,
प्रत्यय = प्रत्यय,
इनपुट_वेरिएबल्स=[' इनपुट ', ' चैट का इतिहास ', ' एजेंट_स्क्रैचपैड '],
)
#एजेंट निष्पादक का निर्माण करते समय सभी घटकों को एकीकृत करें
llm_चेन = LLMChain(llm=OpenAI(तापमान=0), प्रॉम्प्ट=प्रॉम्प्ट)
एजेंट = ज़ीरोशॉटएजेंट(llm_चेन=llm_चेन, टूल्स=टूल्स, वर्बोज़=ट्रू)
एजेंट_चेन = AgentExecutor.from_agent_and_tools(
एजेंट = एजेंट, उपकरण = उपकरण, वर्बोज़ = सत्य, मेमोरी = मेमोरी
)
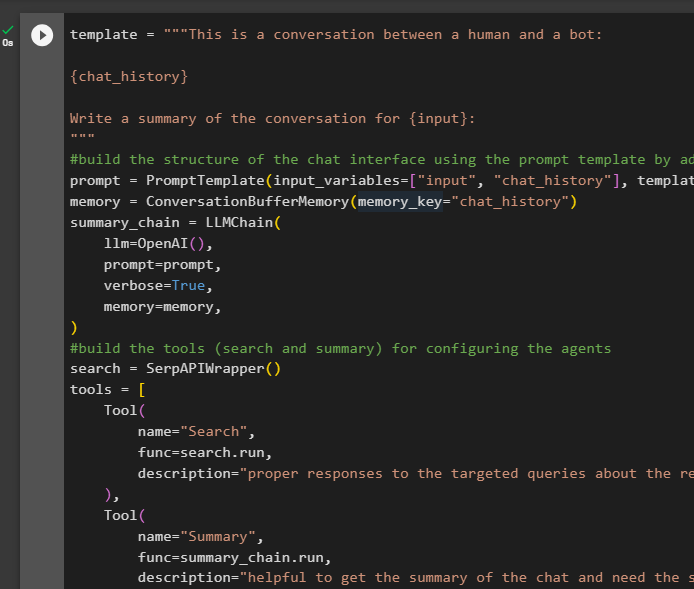
चरण 2: श्रृंखला का परीक्षण
निम्नलिखित कोड चलाएँ:
एजेंट_चेन. दौड़ना ( इनपुट = 'लैंगचेन क्या है' )उत्तर सफलतापूर्वक प्रदर्शित और मेमोरी में संग्रहीत है:
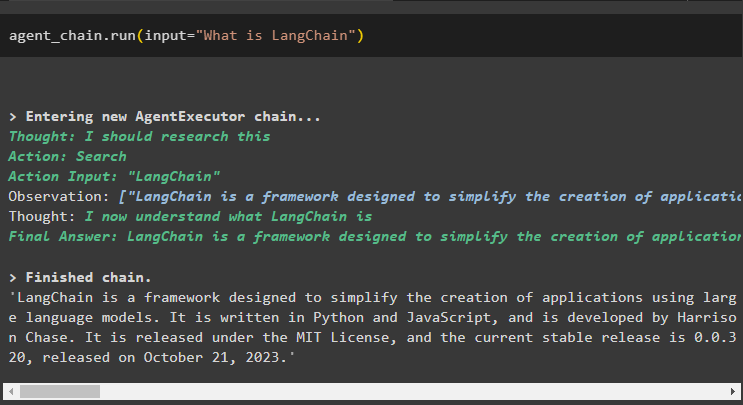
अधिक संदर्भ दिए बिना अनुवर्ती प्रश्न पूछें:
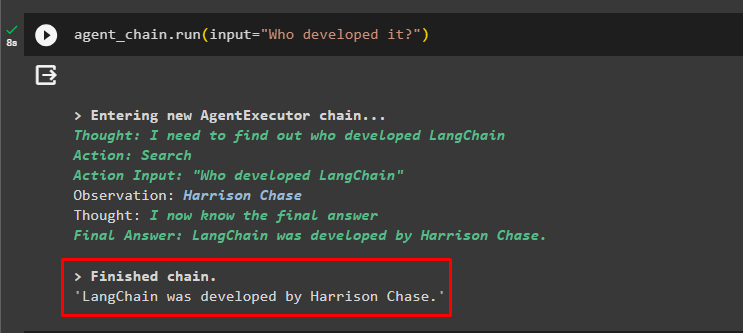
एजेंट_चेन. दौड़ना ( इनपुट = 'इसे किसने विकसित किया?' )एजेंट प्रश्न को रूपांतरित करके समझने के लिए मेमोरी का उपयोग करता है और फिर उत्तर प्रिंट करता है:
एजेंट से जुड़ी मेमोरी का उपयोग करके चैट का सारांश प्राप्त करें:
एजेंट_चेन. दौड़ना (इनपुट = 'धन्यवाद! मेरे 5 साल के बच्चे के लिए बातचीत को संक्षेप में प्रस्तुत करें'
)
उत्पादन
सारांश सफलतापूर्वक निकाला गया है, और अब तक सब कुछ वैसा ही लग रहा है लेकिन परिवर्तन अगले चरण में आता है:
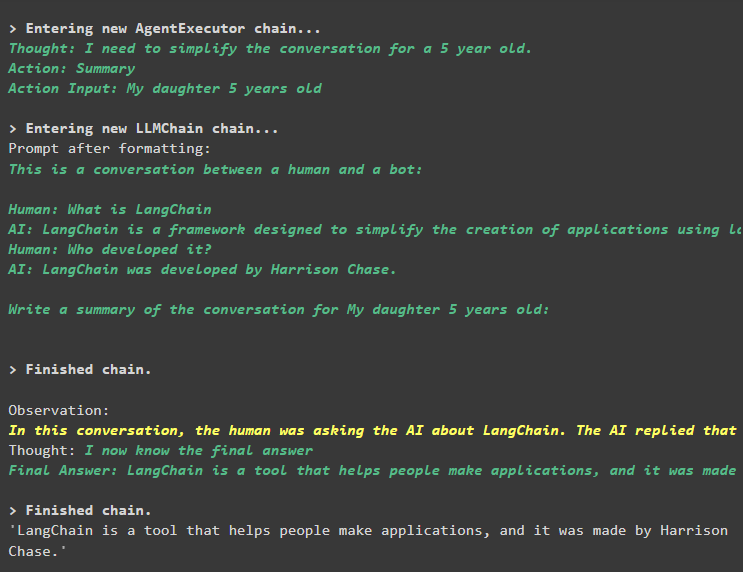
चरण 3: मेमोरी का परीक्षण
निम्नलिखित कोड का उपयोग करके मेमोरी से चैट संदेश निकालना:
छपाई ( एजेंट_चेन. याद . बफर )टूल ने एक और प्रश्न जोड़कर इतिहास को संशोधित किया है जो मूल रूप से नहीं पूछा गया था। ऐसा तब होता है जब मॉडल a का उपयोग करके प्रश्न को समझता है स्वयं से पूछें सवाल। टूल गलती से सोचता है कि यह उपयोगकर्ता द्वारा पूछा गया है और इसे एक अलग क्वेरी के रूप में मानता है। तो यह उस अतिरिक्त प्रश्न को भी स्मृति में जोड़ देता है जिसका उपयोग बातचीत का संदर्भ प्राप्त करने के लिए किया जाता है:
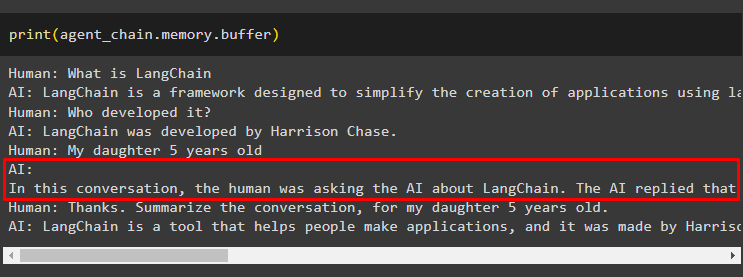
अभी के लिए इतना ही।
निष्कर्ष
लैंगचेन में एक एजेंट और उसके टूल दोनों में मेमोरी जोड़ने के लिए, उनकी निर्भरता प्राप्त करने और उनसे लाइब्रेरी आयात करने के लिए मॉड्यूल स्थापित करें। उसके बाद, वार्तालाप मेमोरी, भाषा मॉडल, उपकरण और मेमोरी जोड़ने के लिए एजेंट बनाएं। अनुशंसित विधि मेमोरी जोड़ने के लिए चैट इतिहास को संग्रहीत करने के लिए एजेंट और उसके टूल्स में ReadOnlyMemory का उपयोग किया जाता है। उपयोगकर्ता इसका भी उपयोग कर सकता है संवादी स्मृति एजेंटों और उपकरणों दोनों के लिए। लेकिन, उन्हें मिलता है अस्पष्ट कभी-कभी और मेमोरी में चैट बदलें।