पंडों ने NaN मान भरें
यदि आपके डेटा फ़्रेम के किसी कॉलम में NaN या कोई नहीं मान है, तो आप उन्हें शून्य (0) से भरने के लिए 'fillna ()' या 'replace ()' फ़ंक्शन का उपयोग कर सकते हैं।
भरना()
NA/NaN मान 'fillna ()' फ़ंक्शन का उपयोग करके प्रदान किए गए दृष्टिकोण से भरे हुए हैं। इसका उपयोग निम्नलिखित सिंटैक्स पर विचार करके किया जा सकता है:
यदि आप एकल कॉलम के लिए NaN मान भरना चाहते हैं, तो सिंटैक्स इस प्रकार है:

जब आपको संपूर्ण डेटाफ़्रेम के लिए NaN मान भरने की आवश्यकता होती है, तो सिंटैक्स प्रदान किया जाता है:

बदलने के()
NaN मानों के एकल स्तंभ को बदलने के लिए, प्रदान किया गया सिंटैक्स इस प्रकार है:

जबकि, पूरे DataFrame के NaN मानों को बदलने के लिए, हमें निम्नलिखित सिंटैक्स का उपयोग करना होगा:

इस लेखन में, अब हम अपने पंडों के डेटाफ़्रेम में NaN मानों को भरने के लिए इन दोनों विधियों के व्यावहारिक कार्यान्वयन का पता लगाएंगे और सीखेंगे।
उदाहरण 1: पंडों का उपयोग करके NaN मान भरें 'फिलना ()' विधि
यह चित्रण दिए गए डेटाफ़्रेम में NaN मानों को 0 से भरने के लिए पंडों के 'DataFrame.fillna ()' फ़ंक्शन के अनुप्रयोग को दर्शाता है। आप या तो एक कॉलम में लापता मानों को भर सकते हैं या आप उन्हें पूरे डेटाफ़्रेम के लिए भर सकते हैं। यहां, हम इन दोनों तकनीकों को देखेंगे।
इन रणनीतियों को अमल में लाने के लिए, हमें कार्यक्रम के निष्पादन के लिए एक उपयुक्त मंच प्राप्त करने की आवश्यकता है। इसलिए, हमने 'स्पाइडर' टूल का उपयोग करने का निर्णय लिया। हमने प्रोग्राम में 'पांडा' टूलकिट आयात करके अपना पायथन कोड शुरू किया क्योंकि हमें डेटाफ़्रेम के निर्माण के साथ-साथ उस डेटाफ़्रेम में लापता मानों को भरने के लिए पंडों की सुविधा का उपयोग करने की आवश्यकता है। पूरे कार्यक्रम में 'पीडी' का उपयोग 'पांडा' के उपनाम के रूप में किया जाता है।
अब, हमारे पास पंडों की सुविधाओं तक पहुंच है। हम अपने डेटाफ़्रेम को उत्पन्न करने के लिए सबसे पहले इसके 'pd.DataFrame ()' फ़ंक्शन का उपयोग करते हैं। हमने इस पद्धति को लागू किया और इसे तीन स्तंभों के साथ आरंभ किया। इन स्तंभों के शीर्षक 'M1', 'M2', और 'M3' हैं। 'M1' कॉलम में मान '1', 'कोई नहीं', '5', '9', और '3' हैं। 'M2' में प्रविष्टियाँ 'कोई नहीं', '3', '8', '4' और '6' हैं। जबकि 'M3' डेटा को '1', '2', '3', '5', और 'कोई नहीं' के रूप में संग्रहीत करता है। हमें एक DataFrame ऑब्जेक्ट की आवश्यकता होती है जिसमें 'pd.DataFrame ()' मेथड को कॉल करने पर हम इस DataFrame को स्टोर कर सकते हैं। हमने एक 'लापता' डेटाफ़्रेम ऑब्जेक्ट बनाया और इसे 'पीडी.डेटाफ़्रेम ()' फ़ंक्शन से प्राप्त परिणाम के अनुसार असाइन किया। फिर, हमने पायथन कंसोल पर डेटाफ़्रेम को प्रदर्शित करने के लिए पायथन की 'प्रिंट ()' विधि को नियोजित किया।
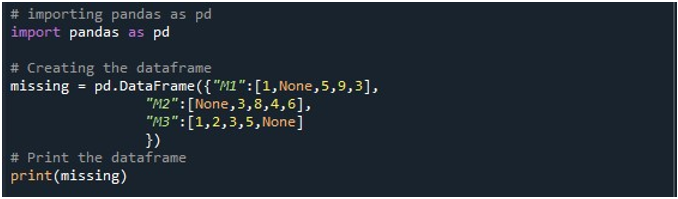
जब हम कोड के इस हिस्से को चलाते हैं, तो टर्मिनल पर तीन कॉलम वाला डेटाफ्रेम देखा जा सकता है। यहाँ, हम देख सकते हैं कि तीनों स्तंभों में शून्य मान हैं।
हमने लापता मानों को 0 से भरने के लिए पंडों के 'फिलना ()' फ़ंक्शन को लागू करने के लिए कुछ शून्य मानों के साथ एक डेटाफ़्रेम बनाया। आइए जानें कि हम ऐसा कैसे कर सकते हैं।
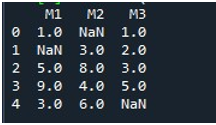
डेटाफ़्रेम प्रदर्शित करने के बाद, हमने पंडों के 'फ़िलना ()' फ़ंक्शन को लागू किया। यहां, हम लापता मानों को एक कॉलम में भरना सीखेंगे। इसके लिए सिंटेक्स का उल्लेख ट्यूटोरियल की शुरुआत में पहले ही किया जा चुका है। हमने डेटाफ़्रेम का नाम प्रदान किया और '.fillna ()' फ़ंक्शन के साथ विशेष कॉलम शीर्षक निर्दिष्ट किया। इस पद्धति के कोष्ठकों के बीच, हमने वह मान प्रदान किया है जिसे शून्य स्थानों में रखा जाएगा। डेटाफ़्रेम नाम 'अनुपलब्ध' है और हमने यहां जो कॉलम चुना है वह 'एम 2' है। 'फिलना ()' के ब्रेसिज़ के बीच प्रदान किया गया मान '0' है। अंत में, हमने अपडेट किए गए डेटाफ़्रेम को देखने के लिए 'प्रिंट ()' फ़ंक्शन को कॉल किया।

यहां, आप देख सकते हैं कि DataFrame के 'M2' कॉलम में अब कोई लापता मान नहीं है क्योंकि NaN मान 0 से भरा हुआ है।
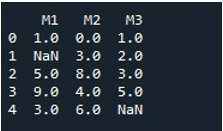
संपूर्ण डेटाफ़्रेम के NaN मानों को एक ही विधि से भरने के लिए, हमने 'fillna ()' कहा। यह काफी सरल है। हमने डेटाफ्रेम नाम को 'फिलना ()' फ़ंक्शन के साथ प्रदान किया और कोष्ठक के बीच फ़ंक्शन मान '0' असाइन किया। अंत में, 'प्रिंट ()' फ़ंक्शन ने हमें भरा हुआ डेटाफ़्रेम दिखाया।

यह हमें बिना किसी NaN मान वाला डेटाफ़्रेम प्राप्त करता है क्योंकि सभी मान अब 0 से भर दिए गए हैं।
उदाहरण 2: पंडों का उपयोग करके NaN मान भरें 'बदलें ()' विधि
आलेख का यह भाग डेटाफ़्रेम में NaN मानों को भरने के लिए एक अन्य विधि को प्रदर्शित करता है। हम एक कॉलम में और संपूर्ण डेटाफ़्रेम में मानों को भरने के लिए पंडों के 'प्रतिस्थापन ()' फ़ंक्शन का उपयोग करेंगे।
हम 'स्पाइडर' टूल में कोड लिखना शुरू करते हैं। सबसे पहले, हमने आवश्यक पुस्तकालयों का आयात किया। यहां, हमने पंडों के तरीकों का उपयोग करने के लिए पायथन प्रोग्राम को सक्षम करने के लिए पंडों की लाइब्रेरी को लोड किया। दूसरी लाइब्रेरी जिसे हमने लोड किया है वह NumPy है और इसे 'np' के नाम से जाना जाता है। NumPy लापता डेटा को 'बदलें ()' विधि से संभालता है।
फिर, हमने तीन कॉलम - 'स्क्रू', 'नेल' और 'ड्रिल' वाले डेटाफ्रेम को जेनरेट किया। प्रत्येक कॉलम में मान क्रमशः दिए गए हैं। 'स्क्रू' कॉलम में '112', '234', 'कोई नहीं' और '650' मान हैं। 'नेल' कॉलम में '123', '145', 'कोई नहीं' और '711' है। अंत में, 'ड्रिल' कॉलम में '312', 'कोई नहीं', '500' और 'कोई नहीं' मान हैं। डेटाफ़्रेम को 'टूल' डेटाफ़्रेम ऑब्जेक्ट में संग्रहीत किया जाता है और 'प्रिंट ()' विधि का उपयोग करके प्रदर्शित किया जाता है।
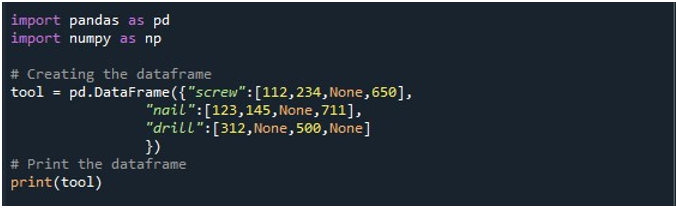
रिकॉर्ड में चार NaN मानों वाला एक डेटाफ़्रेम निम्न आउटपुट छवि में देखा जा सकता है:
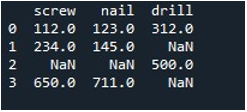
अब, हम डेटाफ़्रेम के एकल कॉलम में अशक्त मानों को भरने के लिए पंडों की 'प्रतिस्थापन ()' विधि का उपयोग करते हैं। कार्य के लिए, हमने 'बदलें ()' फ़ंक्शन को लागू किया। हमने डेटाफ़्रेम नाम 'टूल' और कॉलम 'स्क्रू' को '.replace ()' विधि के साथ आपूर्ति की। इसके ब्रेसिज़ के बीच, हम डेटाफ़्रेम में 'np.nan' प्रविष्टियों के लिए '0' मान सेट करते हैं। आउटपुट प्रदर्शित करने के लिए 'प्रिंट ()' विधि कार्यरत है।

परिणामी डेटाफ़्रेम हमें पहला कॉलम दिखाता है जिसमें NaN प्रविष्टियाँ 'स्क्रू' कॉलम में 0 से बदली जा रही हैं।
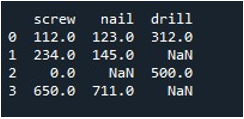
अब, हम संपूर्ण DataFrame में मानों को भरना सीखेंगे। हमने डेटाफ़्रेम के नाम से 'प्रतिस्थापन ()' विधि को बुलाया और वह मान प्रदान किया जिसे हम np.nan प्रविष्टियों से बदलना चाहते हैं। अंत में, हमने अपडेट किए गए डेटाफ़्रेम को 'प्रिंट ()' फ़ंक्शन के साथ प्रिंट किया।

यह हमें बिना किसी रिकॉर्ड के परिणामी डेटाफ़्रेम देता है।
निष्कर्ष
डेटाफ़्रेम में गुम प्रविष्टियों से निपटना एक मौलिक है और डेटा विश्लेषण प्रक्रिया में जटिलता को कम करने और डेटा को सुरक्षित रूप से संभालने के लिए एक आवश्यक आवश्यकता है। इस समस्या से निपटने के लिए पांडा हमें कुछ विकल्प प्रदान करता है। हम इस गाइड में दो आसान रणनीतियाँ लाए हैं। हमने आपके लिए चीजों को थोड़ा समझने योग्य और आसान बनाने के लिए नमूना कोड निष्पादित करने के लिए 'स्पाइडर' टूल की सहायता से दोनों तकनीकों का अभ्यास किया। इन कार्यों का ज्ञान प्राप्त करना आपके पंडों के कौशल को तेज करेगा।