त्वरित रूपरेखा
यह पोस्ट निम्नलिखित प्रदर्शित करेगी:
खोज श्रृंखला के साथ स्व-पूछें कैसे कार्यान्वित करें
- फ्रेमवर्क स्थापित करना
- भवन निर्माण पर्यावरण
- पुस्तकालय आयात करना
- भाषा मॉडल का निर्माण
- लैंगचेन अभिव्यक्ति भाषा का उपयोग करना
- एजेंट निष्पादक को कॉन्फ़िगर करना
- एजेंट चला रहा है
- सेल्फ-आस्क एजेंट का उपयोग करना
खोज श्रृंखला के साथ स्वयं-पूछें कैसे कार्यान्वित करें?
सेल्फ-आस्क चेनिंग प्रक्रिया को बेहतर बनाने की प्रक्रिया है क्योंकि यह कमांड को पूरी तरह से समझता है। चेन डेटासेट से सभी महत्वपूर्ण शब्दों के बारे में डेटा निकालकर प्रश्न को समझते हैं। एक बार जब मॉडल प्रशिक्षित हो जाता है और क्वेरी को समझ लेता है, तो यह उपयोगकर्ता द्वारा पूछी गई क्वेरी का जवाब उत्पन्न करता है।
लैंगचेन में खोज श्रृंखलाओं के साथ स्व-पूछ को लागू करने की प्रक्रिया सीखने के लिए, बस निम्नलिखित मार्गदर्शिका देखें:
चरण 1: फ्रेमवर्क स्थापित करना
सबसे पहले, निम्नलिखित कोड का उपयोग करके लैंगचेन प्रक्रिया को स्थापित करके प्रक्रिया शुरू करें और प्रक्रिया के लिए सभी निर्भरताएँ प्राप्त करें:
पाइप लैंगचैन स्थापित करें
लैंगचेन स्थापित करने के बाद, 'इंस्टॉल करें' गूगल-खोज-परिणाम OpenAI वातावरण का उपयोग करके Google से खोज परिणाम प्राप्त करने के लिए:
पिप इंस्टाल ओपनाई गूगल-सर्च-परिणाम 
चरण 2: पर्यावरण का निर्माण
एक बार मॉड्यूल और फ्रेमवर्क स्थापित हो जाने के बाद, इसके लिए वातावरण स्थापित करें ओपनएआई और सर्पएपीआई निम्नलिखित कोड का उपयोग करके अपने एपीआई का उपयोग करें। ओएस और गेटपास लाइब्रेरी आयात करें जिनका उपयोग उनके संबंधित खातों से एपीआई कुंजी दर्ज करने के लिए किया जा सकता है:
आयात आपआयात पास ले लो
आप . लगभग [ 'OPENAI_API_KEY' ] = पास ले लो . पास ले लो ( 'ओपनएआई एपीआई कुंजी:' )
आप . लगभग [ 'SERPAPI_API_KEY' ] = पास ले लो . पास ले लो ( 'सेरपापी एपीआई कुंजी:' )
चरण 3: पुस्तकालय आयात करना
पर्यावरण स्थापित करने के बाद, बस उपयोगिताओं, एजेंटों, एलएलएम और अन्य जैसी लैंगचेन निर्भरताओं से आवश्यक पुस्तकालयों को आयात करें:
से लैंगचैन. एलएमएस आयात ओपनएआईसे लैंगचैन. उपयोगिताओं आयात सर्पएपिरैपर
से लैंगचैन. एजेंट . आउटपुट_पार्सर्स आयात SelfAskOutputParser
से लैंगचैन. एजेंट . प्रारूप_स्क्रैचपैड आयात प्रारूप_लॉग_टू_स्ट्र
से लैंगचैन आयात केंद्र
से लैंगचैन. एजेंट आयात इनिशियलाइज़_एजेंट , औजार
से लैंगचैन. एजेंट आयात एजेंट प्रकार
चरण 4: भाषा मॉडल का निर्माण
पूरी प्रक्रिया के दौरान उपरोक्त लाइब्रेरी प्राप्त करना आवश्यक है क्योंकि OpenAI() का उपयोग भाषा मॉडल को कॉन्फ़िगर करने के लिए किया जाता है। खोज चर को कॉन्फ़िगर करने और एजेंट के सभी कार्यों को करने के लिए आवश्यक टूल सेट करने के लिए SerpAPIWrapper() विधि का उपयोग करें:
एलएलएम = ओपनएआई ( तापमान = 0 )खोज = सर्पएपिरैपर ( )
औजार = [
औजार (
नाम = 'मध्यवर्ती उत्तर' ,
समारोह = खोजना। दौड़ना ,
विवरण = 'जब आपको खोज के साथ पूछने की आवश्यकता हो तब उपयोगी' ,
)
]
चरण 5: लैंगचेन अभिव्यक्ति भाषा का उपयोग करना
प्रॉम्प्ट वेरिएबल में मॉडल लोड करके लैंगचेन एक्सप्रेशन लैंग्वेज (एलसीईएल) का उपयोग करके एजेंट को कॉन्फ़िगर करना शुरू करना:
तत्पर = केंद्र। खींचो ( 'hwchase17/खोज के साथ स्वयं-पूछें' )एक अन्य वेरिएबल को परिभाषित करें जिसे टेक्स्ट उत्पन्न करना बंद करने और उत्तरों की लंबाई को नियंत्रित करने के लिए निष्पादित किया जा सकता है:
एलएलएम_विथ_स्टॉप = एलएलएम बाँध ( रुकना = [ ' \एन मध्यवर्ती उत्तर:' ] )अब, लैम्ब्डा का उपयोग करके एजेंटों को कॉन्फ़िगर करें जो प्रश्नों के उत्तर उत्पन्न करने के लिए एक इवेंट-संचालित सर्वर रहित प्लेटफ़ॉर्म है। इसके अलावा, पहले से कॉन्फ़िगर किए गए घटकों का उपयोग करके अनुकूलित परिणाम प्राप्त करने के लिए मॉडल को प्रशिक्षित करने और परीक्षण करने के लिए आवश्यक चरणों को कॉन्फ़िगर करें:
प्रतिनिधि = {'इनपुट' : लैम्ब्डा एक्स: एक्स [ 'इनपुट' ] ,
'एजेंट_स्क्रैचपैड' : लैम्ब्डा एक्स: प्रारूप_लॉग_टू_स्ट्र (
एक्स [ 'मध्यवर्ती चरण' ] ,
अवलोकन_उपसर्ग = ' \एन मध्यवर्ती उत्तर: ' ,
एलएलएम_उपसर्ग = '' ,
) ,
} | शीघ्र | एलएलएम_विथ_स्टॉप | SelfAskOutputParser ( )
चरण 6: एजेंट निष्पादक को कॉन्फ़िगर करना
विधि का परीक्षण करने से पहले, एजेंट को उत्तरदायी बनाने के लिए बस लैंगचेन से एजेंट एक्ज़ीक्यूटर लाइब्रेरी को आयात करें:
से लैंगचैन. एजेंट आयात एजेंटनिष्पादकAgentExecutor() विधि को कॉल करके और घटकों को इसके तर्क के रूप में उपयोग करके एजेंट_निष्पादक चर को परिभाषित करें:
एजेंट_निष्पादक = एजेंटनिष्पादक ( प्रतिनिधि = प्रतिनिधि , औजार = औजार , वाचाल = सत्य )चरण 7: एजेंट चलाना
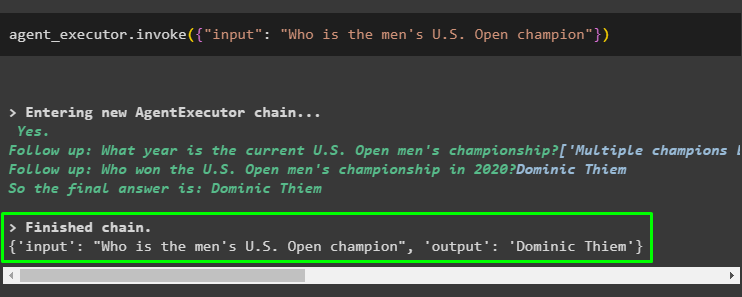
एक बार जब एजेंट निष्पादक कॉन्फ़िगर हो जाए, तो बस इनपुट वेरिएबल में प्रश्न/संकेत प्रदान करके इसका परीक्षण करें:
एजेंट_निष्पादक. आह्वान ( { 'इनपुट' : 'पुरुष यू.एस. ओपन चैंपियन कौन है' } )उपरोक्त कोड को निष्पादित करने पर आउटपुट में यूएस ओपन चैंपियन यानी डोमिनिक थिएम के नाम के साथ प्रतिक्रिया हुई है:
चरण 8: सेल्फ-आस्क एजेंट का उपयोग करना
एजेंट से प्रतिक्रिया प्राप्त करने के बाद, इसका उपयोग करें स्वयं_पूछ_के_साथ_खोजें रन() विधि में क्वेरी वाला एजेंट:
स्वयं_खोज_के_साथ_पूछें = इनिशियलाइज़_एजेंट (औजार , एलएलएम , प्रतिनिधि = एजेंट प्रकार. स्वयं_पूछें_साथ_खोजें , वाचाल = सत्य
)
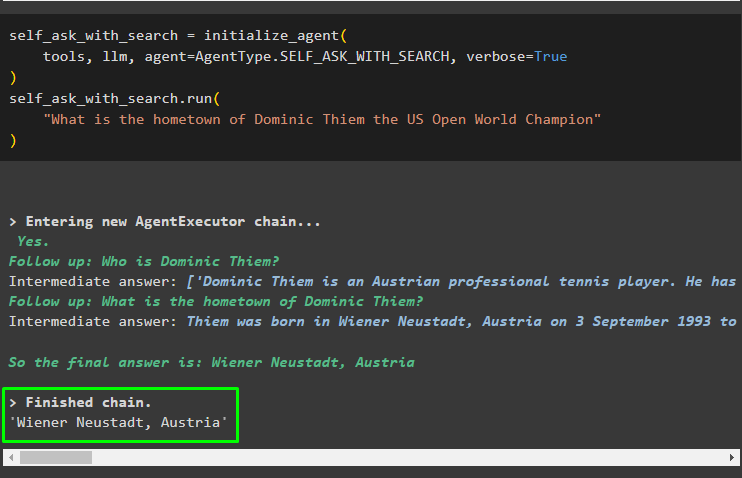
स्वयं_खोज_के_साथ_पूछें। दौड़ना (
'यूएस ओपन विश्व चैंपियन डोमिनिक थिएम का गृहनगर क्या है'
)
निम्नलिखित स्क्रीनशॉट प्रदर्शित करता है कि स्व-पूछ एजेंट डेटासेट से प्रत्येक महत्वपूर्ण शब्द के बारे में जानकारी निकालता है। एक बार जब यह क्वेरी के बारे में सारी जानकारी एकत्र कर लेता है और प्रश्नों को समझ लेता है, तो यह आसानी से उत्तर उत्पन्न कर देता है। एजेंट द्वारा स्वयं पूछे गए प्रश्न हैं:
- डोमिनिक थिएम कौन है?
- डोमिनिक थिएम का गृहनगर क्या है?
इन सवालों के जवाब मिलने के बाद, एजेंट ने मूल प्रश्न का उत्तर तैयार किया है जो है ' वीनर न्यूस्टाड, ऑस्ट्रिया ”:
यह लैंगचेन फ्रेमवर्क का उपयोग करके एक खोज श्रृंखला के साथ स्व-पूछ को लागू करने की प्रक्रिया के बारे में है।
निष्कर्ष
लैंगचेन में खोज के साथ स्वयं-पूछने को लागू करने के लिए, एजेंट से परिणाम प्राप्त करने के लिए बस Google-खोज-परिणाम जैसे आवश्यक मॉड्यूल स्थापित करें। उसके बाद, प्रक्रिया शुरू करने के लिए OpenAI और SerpAPi खातों से एपीआई कुंजियों का उपयोग करके पर्यावरण सेट करें। एजेंट को कॉन्फ़िगर करें और AgentExecutor() विधि का उपयोग करके परीक्षण करने के लिए स्वयं-पूछ मॉडल के साथ मॉडल बनाएं।