त्वरित रूपरेखा
यह पोस्ट निम्नलिखित प्रदर्शित करेगी:
- लैंगचेन में किसी एजेंट के मध्यवर्ती चरणों तक कैसे पहुंचें
- फ्रेमवर्क स्थापित करना
- OpenAI वातावरण सेट करना
- पुस्तकालय आयात करना
- बिल्डिंग एलएलएम और एजेंट
- एजेंट का उपयोग करना
- विधि 1: मध्यवर्ती चरणों तक पहुँचने के लिए डिफ़ॉल्ट रिटर्न प्रकार
- विधि 2: मध्यवर्ती चरणों तक पहुँचने के लिए 'डंप' का उपयोग करना
- निष्कर्ष
लैंगचेन में किसी एजेंट के मध्यवर्ती चरणों तक कैसे पहुँचें?
लैंगचेन में एजेंट बनाने के लिए, उपयोगकर्ता को मॉडल में शामिल चरणों की संख्या प्राप्त करने के लिए इसके टूल और टेम्पलेट की संरचना को कॉन्फ़िगर करना होगा। एजेंट विचारों, कार्यों, टिप्पणियों आदि जैसे मध्यवर्ती चरणों को स्वचालित करने के लिए जिम्मेदार है। लैंगचेन में किसी एजेंट के मध्यवर्ती चरणों तक पहुंचने का तरीका जानने के लिए, बस सूचीबद्ध चरणों का पालन करें:
चरण 1: फ्रेमवर्क स्थापित करना
सबसे पहले, बस पायथन नोटबुक में निम्नलिखित कोड निष्पादित करके लैंगचेन की निर्भरता स्थापित करें:
पाइप लैंगचैन_एक्सपेरिमेंटल इंस्टॉल करें
इसका उपयोग करके इसकी निर्भरता प्राप्त करने के लिए OpenAI मॉड्यूल स्थापित करें रंज भाषा मॉडल बनाने के लिए उन्हें कमांड दें और उनका उपयोग करें:
पिप इंस्टाल ओपनाई
चरण 2: OpenAI वातावरण सेट करना
एक बार मॉड्यूल स्थापित हो जाने के बाद, इसे सेट करें ओपनएआई वातावरण अपने खाते से उत्पन्न एपीआई कुंजी का उपयोग करना:
आयात आप
आयात पास ले लो
आप। लगभग [ 'OPENAI_API_KEY' ] = पास ले लो। पास ले लो ( 'ओपनएआई एपीआई कुंजी:' )
चरण 3: पुस्तकालय आयात करना
अब जब हमारे पास निर्भरताएं स्थापित हो गई हैं, तो लैंगचेन से लाइब्रेरी आयात करने के लिए उनका उपयोग करें:
लैंगचैन से. एजेंट आयात लोड_टूल्सलैंगचैन से. एजेंट आयात इनिशियलाइज़_एजेंट
लैंगचैन से. एजेंट आयात एजेंट प्रकार
लैंगचैन से. एलएमएस आयात ओपनएआई
चरण 4: एलएलएम और एजेंट का निर्माण
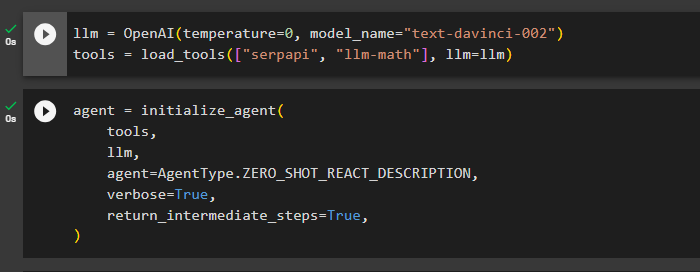
एक बार लाइब्रेरी आयात हो जाने के बाद, एजेंट के लिए भाषा मॉडल और उपकरण बनाने के लिए उनका उपयोग करने का समय आ गया है। एलएलएम वैरिएबल को परिभाषित करें और इसे OpenAI() विधि के साथ निर्दिष्ट करें जिसमें तापमान और मॉडल_नाम तर्क हों। “ औजार 'वेरिएबल में सर्पएपीआई और एलएलएम-गणित उपकरण और इसके तर्क में भाषा मॉडल के साथ लोड_टूल्स() विधि शामिल है:
एलएलएम = ओपनएआई ( तापमान = 0 , मॉडल नाम = 'टेक्स्ट-डेविन्सी-002' )औजार = लोड_टूल्स ( [ 'सर्पापी' , 'एलएम-गणित' ] , एलएलएम = एलएलएम )
एक बार भाषा मॉडल और उपकरण कॉन्फ़िगर हो जाने के बाद, एजेंट को भाषा मॉडल में उपकरणों का उपयोग करके मध्यवर्ती चरण निष्पादित करने के लिए डिज़ाइन करें:
प्रतिनिधि = इनिशियलाइज़_एजेंट (औजार ,
एलएलएम ,
प्रतिनिधि = एजेंट प्रकार. शून्य_SHOT_REACT_DESCRIPTION ,
वाचाल = सत्य ,
वापसी_मध्यवर्ती_चरण = सत्य ,
)
चरण 5: एजेंट का उपयोग करना
अब, एजेंट() विधि के इनपुट में एक प्रश्न पूछकर और उसे क्रियान्वित करके एजेंट का परीक्षण करें:
प्रतिक्रिया = प्रतिनिधि ({
'इनपुट' : 'लियो डिकैप्रियो की गर्लफ्रेंड कौन है और उनकी उम्र में कितना अंतर है'
}
)
मॉडल ने लियो डिकैप्रियो की गर्लफ्रेंड का नाम, उसकी उम्र, लियो डिकैप्रियो की उम्र और उनके बीच का अंतर जानने के लिए कुशलता से काम किया है। निम्नलिखित स्क्रीनशॉट अंतिम उत्तर तक पहुंचने के लिए एजेंट द्वारा खोजे गए कई प्रश्न और उत्तर प्रदर्शित करता है:
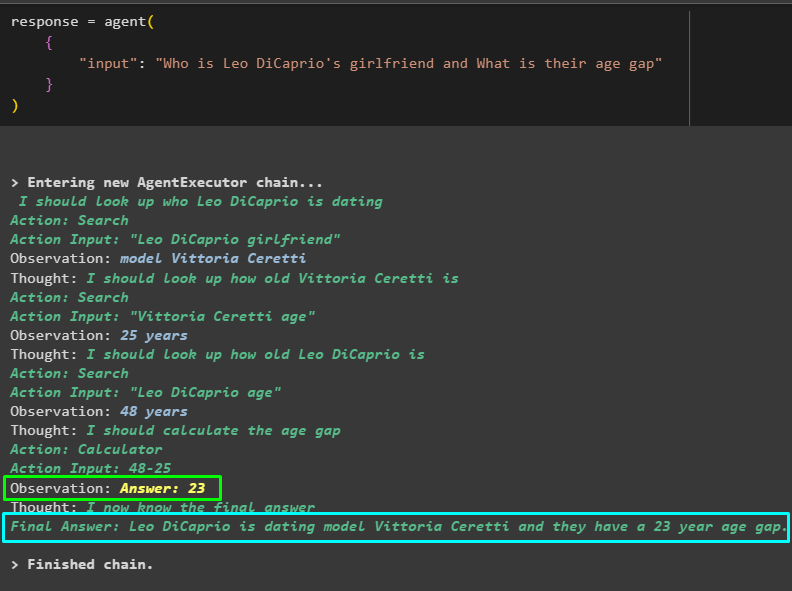
उपरोक्त स्क्रीनशॉट एजेंट के कामकाज को प्रदर्शित नहीं करता है और यह सभी उत्तरों को खोजने के लिए उस चरण तक कैसे पहुंचता है। आइए चरणों को खोजने के लिए अगले भाग पर जाएँ:
विधि 1: मध्यवर्ती चरणों तक पहुँचने के लिए डिफ़ॉल्ट रिटर्न प्रकार
मध्यवर्ती चरण तक पहुंचने की पहली विधि निम्नलिखित कोड का उपयोग करके लैंगचेन द्वारा प्रस्तावित डिफ़ॉल्ट रिटर्न प्रकार का उपयोग करना है:
छपाई ( प्रतिक्रिया [ 'मध्यवर्ती चरण' ] )निम्नलिखित GIF मध्यवर्ती चरणों को एक पंक्ति में प्रदर्शित करता है जो पठनीयता पहलू के मामले में काफी अच्छा नहीं है:

विधि 2: मध्यवर्ती चरणों तक पहुँचने के लिए 'डंप' का उपयोग करना
अगली विधि लैंगचेन फ्रेमवर्क से डंप लाइब्रेरी का उपयोग करके मध्यवर्ती चरण प्राप्त करने का एक और तरीका बताती है। आउटपुट को अधिक संरचित और पढ़ने में आसान बनाने के लिए सुंदर तर्क के साथ डंप() विधि का उपयोग करें:
लैंगचैन से. भार . गंदी जगह आयात उदासीनताछपाई ( उदासीनता ( प्रतिक्रिया [ 'मध्यवर्ती चरण' ] , सुंदर = सत्य ) )
अब, हमारे पास आउटपुट अधिक संरचित रूप में है जो उपयोगकर्ता द्वारा आसानी से पढ़ा जा सकता है। इसे अधिक अर्थपूर्ण बनाने के लिए इसे कई खंडों में विभाजित किया गया है और प्रत्येक खंड में प्रश्नों के उत्तर खोजने के चरण शामिल हैं:
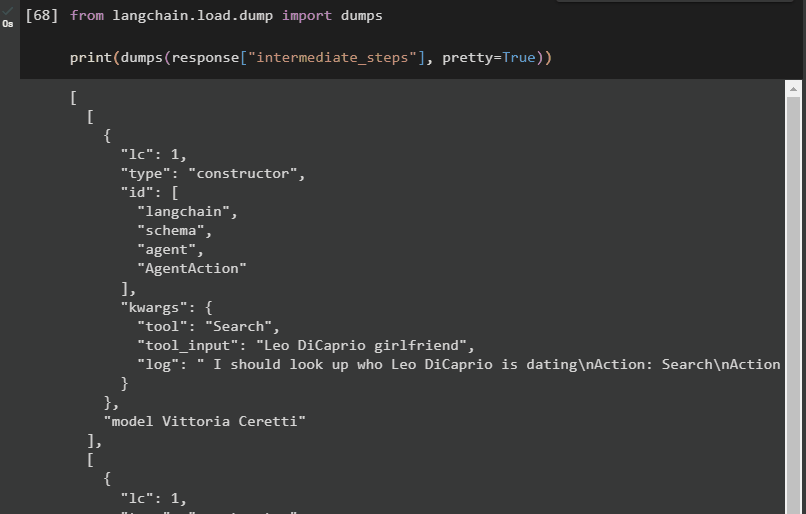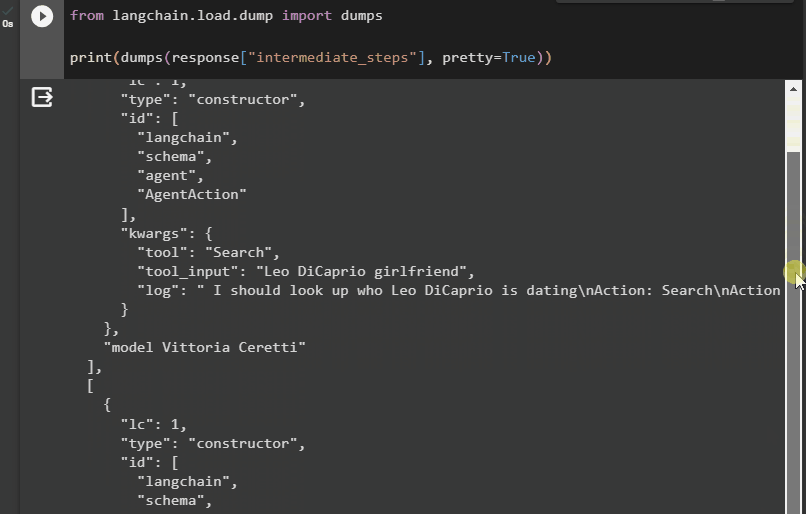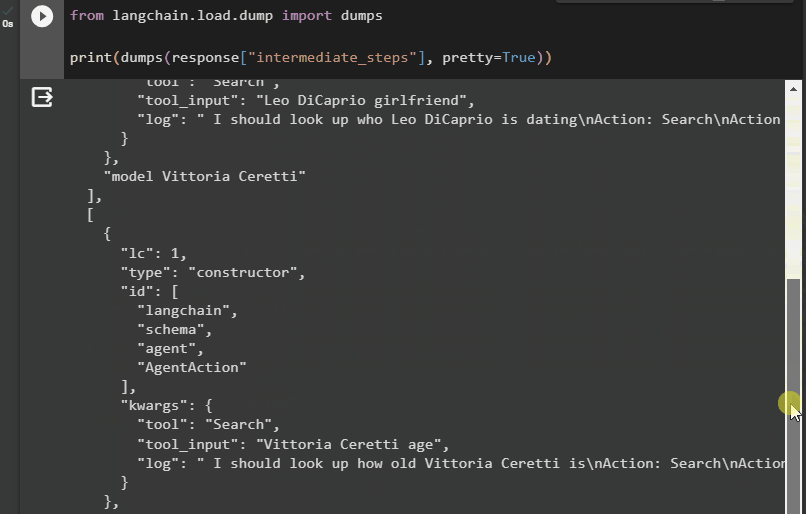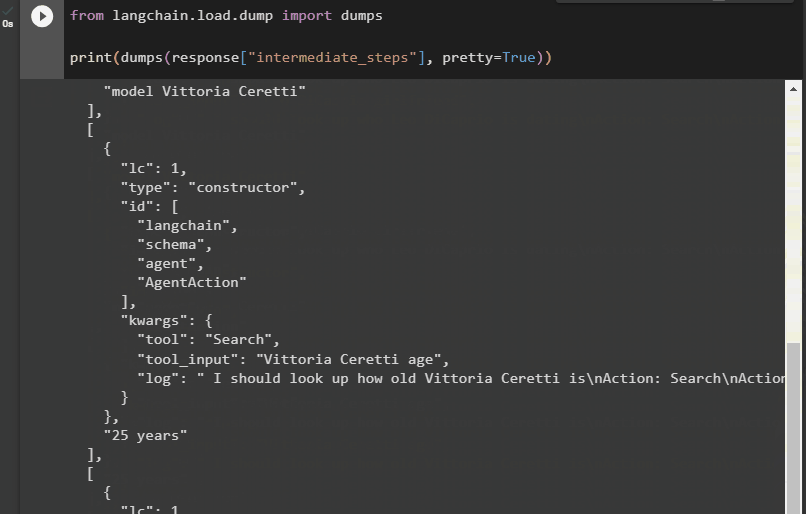
यह सब लैंगचेन में एक एजेंट के मध्यवर्ती चरणों तक पहुँचने के बारे में है।
निष्कर्ष
लैंगचेन में किसी एजेंट के मध्यवर्ती चरणों तक पहुंचने के लिए, भाषा मॉडल के निर्माण के लिए लाइब्रेरी आयात करने के लिए मॉड्यूल स्थापित करें। उसके बाद, टूल, एलएलएम और एजेंट के प्रकार का उपयोग करके एजेंट को आरंभ करने के लिए टूल सेट करें जो प्रश्नों का उत्तर दे सके। एक बार एजेंट कॉन्फ़िगर हो जाने के बाद, उत्तर प्राप्त करने के लिए इसका परीक्षण करें और फिर मध्यवर्ती चरणों तक पहुंचने के लिए डिफ़ॉल्ट प्रकार या डंप लाइब्रेरी का उपयोग करें। इस गाइड में लैंगचेन में एक एजेंट के मध्यवर्ती चरणों तक पहुँचने की प्रक्रिया के बारे में विस्तार से बताया गया है।