लैंगचेन में वार्तालाप बफ़र विंडो का उपयोग कैसे करें?
वार्तालाप बफ़र विंडो का उपयोग नवीनतम संदर्भ प्राप्त करने के लिए वार्तालाप के नवीनतम संदेशों को स्मृति में रखने के लिए किया जाता है। यह लैंगचेन फ्रेमवर्क का उपयोग करके मेमोरी में संदेशों या स्ट्रिंग्स को संग्रहीत करने के लिए K के मान का उपयोग करता है।
लैंगचेन में वार्तालाप बफ़र विंडो का उपयोग करने की प्रक्रिया सीखने के लिए, बस निम्नलिखित मार्गदर्शिका देखें:
चरण 1: मॉड्यूल स्थापित करें
वार्तालाप मॉडल बनाने के लिए आवश्यक निर्भरता के साथ लैंगचेन मॉड्यूल स्थापित करके वार्तालाप बफर विंडो का उपयोग करने की प्रक्रिया शुरू करें:
पाइप लैंगचैन स्थापित करें
उसके बाद, OpenAI मॉड्यूल स्थापित करें जिसका उपयोग लैंगचेन में बड़े भाषा मॉडल बनाने के लिए किया जा सकता है:
पिप इंस्टाल ओपनाई
अब, OpenAI वातावरण स्थापित करें OpenAI खाते से एपीआई कुंजी का उपयोग करके एलएलएम श्रृंखला बनाने के लिए:
आयात आप
आयात पास ले लो
आप . लगभग [ 'OPENAI_API_KEY' ] = पास ले लो . पास ले लो ( 'ओपनएआई एपीआई कुंजी:' )
चरण 2: वार्तालाप बफ़र विंडो मेमोरी का उपयोग करना
लैंगचेन में वार्तालाप बफ़र विंडो मेमोरी का उपयोग करने के लिए, आयात करें कन्वर्सेशनबफरविंडोमेमोरी पुस्तकालय:
से लैंगचैन. याद आयात कन्वर्सेशनबफरविंडोमेमोरीका उपयोग करके मेमोरी को कॉन्फ़िगर करें कन्वर्सेशनबफरविंडोमेमोरी () अपने तर्क के रूप में k के मान के साथ विधि। K के मान का उपयोग बातचीत के नवीनतम संदेशों को रखने और फिर इनपुट और आउटपुट चर का उपयोग करके प्रशिक्षण डेटा को कॉन्फ़िगर करने के लिए किया जाएगा:
याद = कन्वर्सेशनबफरविंडोमेमोरी ( क = 1 )याद। save_context ( { 'इनपुट' : 'नमस्ते' } , { 'आउटपुट' : 'आप कैसे हैं' } )
याद। save_context ( { 'इनपुट' : 'मैं तुम्हारे बारे में अच्छा सोचता हूं' } , { 'आउटपुट' : 'ज्यादा नहीं' } )
को कॉल करके मेमोरी का परीक्षण करें लोड_मेमोरी_वेरिएबल्स ()बातचीत शुरू करने का तरीका:
याद। लोड_मेमोरी_वेरिएबल्स ( { } ) 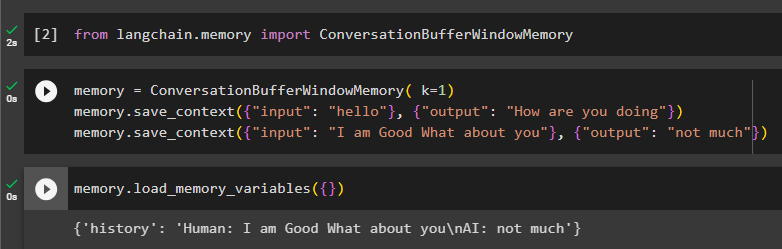
बातचीत का इतिहास प्राप्त करने के लिए, ConversationBufferWindowMemory() फ़ंक्शन का उपयोग करके कॉन्फ़िगर करें वापसी_संदेश तर्क:
याद = कन्वर्सेशनबफरविंडोमेमोरी ( क = 1 , वापसी_संदेश = सत्य )याद। save_context ( { 'इनपुट' : 'नमस्ते' } , { 'आउटपुट' : 'क्या चल रहा है' } )
याद। save_context ( { 'इनपुट' : 'आप ज़्यादा नहीं' } , { 'आउटपुट' : 'ज्यादा नहीं' } )
अब, का उपयोग करके मेमोरी को कॉल करें लोड_मेमोरी_वेरिएबल्स () बातचीत के इतिहास के साथ प्रतिक्रिया प्राप्त करने की विधि:
याद। लोड_मेमोरी_वेरिएबल्स ( { } ) 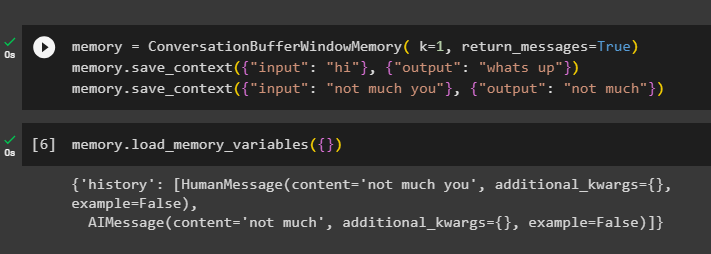
चरण 3: एक श्रृंखला में बफ़र विंडो का उपयोग करना
का उपयोग करके श्रृंखला बनाएं ओपनएआई और वार्तालाप शृंखला लाइब्रेरीज़ और फिर वार्तालाप में नवीनतम संदेशों को संग्रहीत करने के लिए बफ़र मेमोरी को कॉन्फ़िगर करें:
से लैंगचैन. चेन आयात वार्तालाप शृंखलासे लैंगचैन. एलएमएस आयात ओपनएआई
#कई मापदंडों का उपयोग करके बातचीत का सारांश तैयार करना
बातचीत_साथ_सारांश = वार्तालाप शृंखला (
एलएलएम = ओपनएआई ( तापमान = 0 ) ,
#हाल के संदेशों को संग्रहीत करने के लिए k के मान के साथ इसके फ़ंक्शन का उपयोग करके मेमोरी बफर बनाना
याद = कन्वर्सेशनबफरविंडोमेमोरी ( क = 2 ) ,
#अधिक पठनीय आउटपुट प्राप्त करने के लिए वर्बोज़ वेरिएबल कॉन्फ़िगर करें
वाचाल = सत्य
)
बातचीत_साथ_सारांश. भविष्यवाणी करना ( इनपुट = 'नमस्ते क्या हुआ' )
अब मॉडल द्वारा प्रदान किए गए आउटपुट से संबंधित प्रश्न पूछकर बातचीत जारी रखें:
बातचीत_साथ_सारांश. भविष्यवाणी करना ( इनपुट = 'उनके मुद्दे क्या हैं' ) 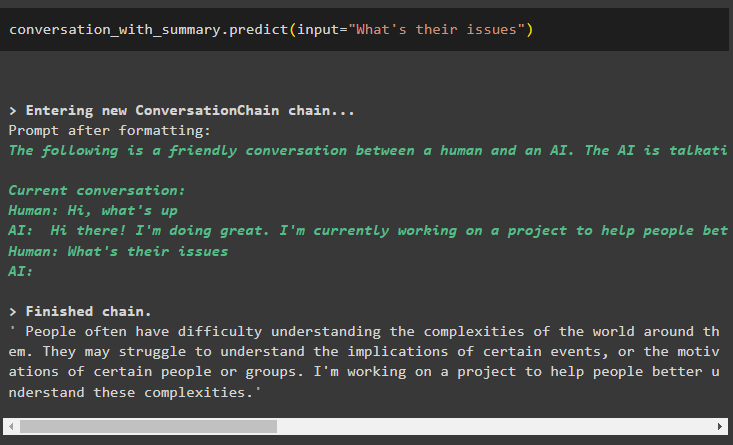
मॉडल को केवल एक पिछले संदेश को संग्रहीत करने के लिए कॉन्फ़िगर किया गया है जिसे संदर्भ के रूप में उपयोग किया जा सकता है:
बातचीत_साथ_सारांश. भविष्यवाणी करना ( इनपुट = 'क्या यह ठीक चल रहा है' ) 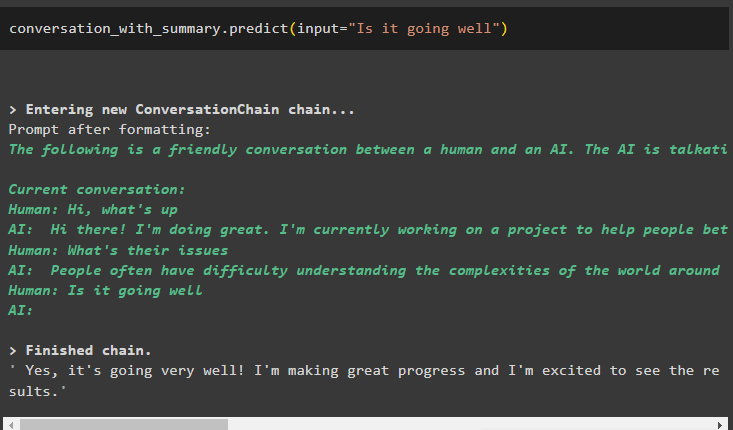
समस्याओं के समाधान के लिए पूछें और आउटपुट संरचना पहले के संदेशों को हटाकर बफ़र विंडो को स्लाइड करती रहेगी:
बातचीत_साथ_सारांश. भविष्यवाणी करना ( इनपुट = 'क्या उपाय है' ) 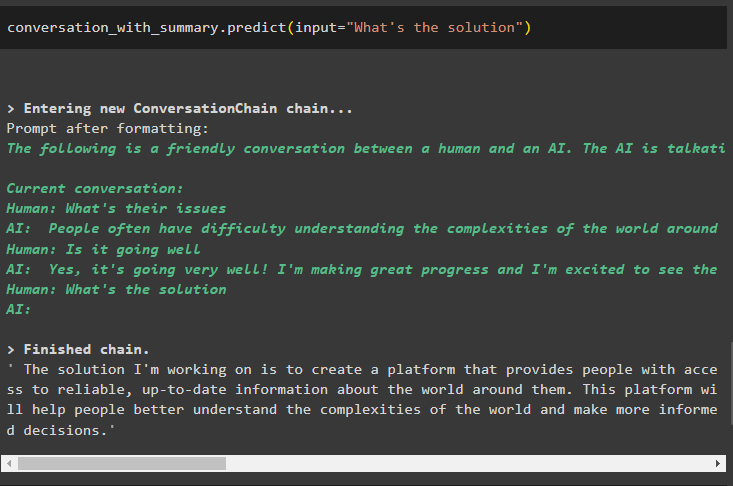
यह सब वार्तालाप बफ़र विंडोज़ लैंगचेन का उपयोग करने की प्रक्रिया के बारे में है।
निष्कर्ष
लैंगचेन में वार्तालाप बफर विंडो मेमोरी का उपयोग करने के लिए, बस मॉड्यूल स्थापित करें और ओपनएआई की एपीआई कुंजी का उपयोग करके पर्यावरण सेट करें। उसके बाद, संदर्भ को बनाए रखने के लिए बातचीत में नवीनतम संदेशों को रखने के लिए k के मान का उपयोग करके बफर मेमोरी बनाएं। एलएलएम या चेन के साथ बातचीत शुरू करने के लिए बफर मेमोरी का उपयोग चेन के साथ भी किया जा सकता है। इस गाइड में लैंगचेन में वार्तालाप बफ़र विंडो का उपयोग करने की प्रक्रिया के बारे में विस्तार से बताया गया है।