इस लेख में, हम चर्चा करेंगे कि आवंटन कैसे किया जाए अलग के माध्यम से स्मृति pytorch_cuda_alloc_conf ' तरीका।
PyTorch में 'pytorch_cuda_alloc_conf' विधि क्या है?
मौलिक रूप से, ' pytorch_cuda_alloc_conf ” PyTorch ढांचे के भीतर एक पर्यावरण चर है। यह चर उपलब्ध प्रसंस्करण संसाधनों के कुशल प्रबंधन को सक्षम बनाता है जिसका अर्थ है कि मॉडल कम से कम समय में चलते हैं और परिणाम देते हैं। यदि ठीक से नहीं किया गया, तो ' अलग 'अभिकलन मंच प्रदर्शित करेगा' स्मृति से बाहर 'त्रुटि और रनटाइम को प्रभावित करें। ऐसे मॉडल जिन्हें बड़ी मात्रा में डेटा पर प्रशिक्षित किया जाना है या जिनमें बड़े ' बैच आकार रनटाइम त्रुटियां उत्पन्न हो सकती हैं क्योंकि डिफ़ॉल्ट सेटिंग्स उनके लिए पर्याप्त नहीं हो सकती हैं।
“ pytorch_cuda_alloc_conf 'चर निम्नलिखित का उपयोग करता है' विकल्प संसाधन आवंटन को संभालने के लिए:
- देशी : यह विकल्प प्रगतिरत मॉडल को मेमोरी आवंटित करने के लिए PyTorch में पहले से उपलब्ध सेटिंग्स का उपयोग करता है।
- max_split_size_mb : यह सुनिश्चित करता है कि निर्दिष्ट आकार से बड़ा कोई भी कोड ब्लॉक विभाजित न हो। इसे रोकने के लिए यह एक शक्तिशाली उपकरण है' विखंडन ”। हम इस लेख में प्रदर्शन के लिए इस विकल्प का उपयोग करेंगे।
- राउंडअप_पॉवर2_डिवीजन : यह विकल्प आवंटन के आकार को निकटतम तक बढ़ा देता है। 2 की शक्ति मेगाबाइट्स (एमबी) में विभाजन।
- राउंडअप_बायपास_थ्रेसहोल्ड_एमबी: यह निर्दिष्ट सीमा से अधिक किसी भी अनुरोध सूची के लिए आवंटन आकार को पूर्णांकित कर सकता है।
- कचरा_संग्रह_सीमा : यह वास्तविक समय में जीपीयू से उपलब्ध मेमोरी का उपयोग करके विलंबता को रोकता है ताकि यह सुनिश्चित किया जा सके कि पुनः दावा-सभी प्रोटोकॉल शुरू नहीं किया गया है।
'pytorch_cuda_alloc_conf' विधि का उपयोग करके मेमोरी कैसे आवंटित करें?
बड़े डेटासेट वाले किसी भी मॉडल को अतिरिक्त मेमोरी आवंटन की आवश्यकता होती है जो डिफ़ॉल्ट रूप से सेट से अधिक होता है। मॉडल आवश्यकताओं और उपलब्ध हार्डवेयर संसाधनों को ध्यान में रखते हुए कस्टम आवंटन को निर्दिष्ट करने की आवश्यकता है।
'का उपयोग करने के लिए नीचे दिए गए चरणों का पालन करें pytorch_cuda_alloc_conf जटिल मशीन-लर्निंग मॉडल के लिए अधिक मेमोरी आवंटित करने के लिए Google Colab IDE में विधि:
चरण 1: Google Colab खोलें
Google पर खोजें सहयोगात्मक ब्राउज़र में और एक ' बनाएं नई नोटबुक 'काम शुरू करने के लिए:
चरण 2: एक कस्टम PyTorch मॉडल सेट करें
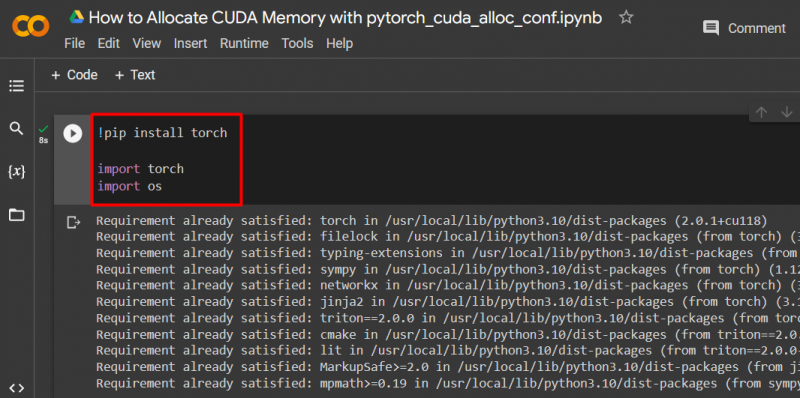
'का उपयोग करके एक PyTorch मॉडल सेट करें !पिप 'इंस्टॉलेशन पैकेज स्थापित करने के लिए' मशाल 'पुस्तकालय और' आयात 'आयात करने का आदेश' मशाल ' और ' आप परियोजना में पुस्तकालय:
मशाल आयात करें
हमें आयात करें
इस परियोजना के लिए निम्नलिखित पुस्तकालयों की आवश्यकता है:
- मशाल - यह मौलिक पुस्तकालय है जिस पर PyTorch आधारित है।
- आप – “ ऑपरेटिंग सिस्टम 'लाइब्रेरी का उपयोग पर्यावरण चर से संबंधित कार्यों को संभालने के लिए किया जाता है जैसे' pytorch_cuda_alloc_conf ” साथ ही सिस्टम निर्देशिका और फ़ाइल अनुमतियाँ:
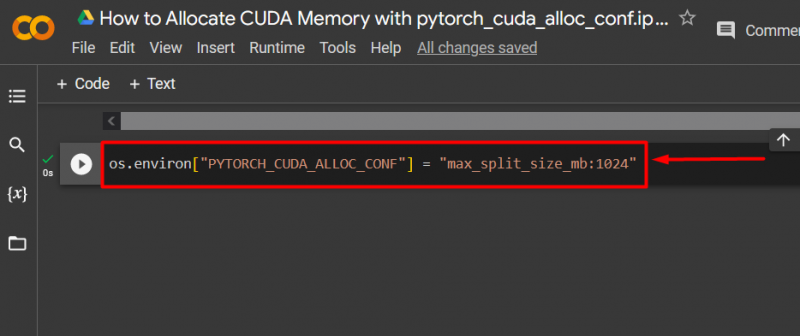
चरण 3: CUDA मेमोरी आवंटित करें
उपयोग ' pytorch_cuda_alloc_conf 'का उपयोग करके अधिकतम विभाजन आकार निर्दिष्ट करने की विधि' max_split_size_mb ”:
चरण 4: अपने PyTorch प्रोजेक्ट को जारी रखें
निर्दिष्ट करने के बाद ' अलग 'के साथ अंतरिक्ष आवंटन' max_split_size_mb 'विकल्प, बिना किसी डर के सामान्य रूप से PyTorch प्रोजेक्ट पर काम करना जारी रखें' स्मृति से बाहर ' गलती।
टिप्पणी : आप यहां हमारे Google Colab नोटबुक तक पहुंच सकते हैं जोड़ना .
प्रो टिप
जैसा कि पहले उल्लेख किया गया है, ' pytorch_cuda_alloc_conf विधि ऊपर दिए गए विकल्पों में से कोई भी ले सकती है। अपनी गहन शिक्षण परियोजनाओं की विशिष्ट आवश्यकताओं के अनुसार उनका उपयोग करें।
सफलता! हमने अभी प्रदर्शित किया है कि 'का उपयोग कैसे करें' pytorch_cuda_alloc_conf 'निर्दिष्ट करने की विधि' max_split_size_mb ” एक PyTorch प्रोजेक्ट के लिए।
निष्कर्ष
उपयोग ' pytorch_cuda_alloc_conf मॉडल की आवश्यकताओं के अनुसार इसके उपलब्ध विकल्पों में से किसी एक का उपयोग करके CUDA मेमोरी आवंटित करने की विधि। ये प्रत्येक विकल्प बेहतर रनटाइम और सुचारू संचालन के लिए PyTorch परियोजनाओं के भीतर एक विशेष प्रसंस्करण समस्या को कम करने के लिए हैं। इस लेख में, हमने '' का उपयोग करने के लिए सिंटैक्स का प्रदर्शन किया है max_split_size_mb विभाजन के अधिकतम आकार को परिभाषित करने का विकल्प।